Introduction à la recherche d’information¶
Supports complémentaires:
Un cours complet en ligne (en anglais) et accompagné d’un ouvrage de référence : http://www-nlp.stanford.edu/IR-book/. Certaines parties du cours empruntent des exemples à ce livre.
S1: les principes¶
Supports complémentaires:
Qu’est ce que la recherche d’information¶
La Recherche d’Information (RI, Information Retrieval, IR en anglais) consiste à trouver des documents peu ou faiblement structurés, dans une grande collection, en fonction d’un besoin d’information. Le domaine d’application le plus connu est celui de la recherche « plein texte ». Étant donné une collection de documents constitués essentiellement de texte, comment trouver les plus pertinents en fonction d’un besoin exprimé par quelques mots-clés? La RI développe des modèles pour interpréter les documents d’une part, le besoin d’information d’autre part, en vue de faire correspondre les deux, mais aussi des techniques pour calculer des réponses rapidement même en présence de collections très volumineuses. Enfin, des systèmes (appelés « moteurs de recherches ») fournissent des solutions sophistiquées prêtes à l’emploi.
La RI a pris une très grande importance, en raison notamment de l’émergence de vastes sources de documents que l’on peut agréger et exploiter (le Web bien sûr, mais aussi les systèmes d’information d’entreprise). Les techniques utilisées ont également beaucoup progressé, avec des résultats spectaculaires. La RI est maintenant omniprésente dans beaucoup d’environnements informatiques, et notamment:
La recherche sur le Web, utilisée quotidiennement par des milliards d’utilisateurs,
La recherche de messages dans votre boîte mail,
La recherche de fichiers sur votre ordinateur (Spotlight),
La recherche de documents dans une base documentaire, publique ou privée,
Ce chapitre introduit ces différents aspects en se concentrant sur la recherche d’information appliquée à des collections de documents structurés, comprenant des parties textuelles importantes.
Précision et rappel¶
Comme le montre la définition assez imprécise donnée en préambule, la recherche d’information se donne un objectif à la fois ambitieux et relativement vague. Cela s’explique en partie par le contexte d’utilisation de ces systèmes. Avec une base de données classique, on connaît le schéma des données, leur organisation générale, avec des contraintes qui garantissent qu’elles ont une certaine régularité. En RI, les données, ou « documents », sont souvent hétérogènes, de provenances diverses, présentent des irrégularités et des variations dues à l’absence de contrainte et de validation au moment de leur création. De plus, un système de RI est souvent utilisé par des utilisateurs non-experts. À la difficulté d’interpréter le contenu des documents et de le décrire s’ajoute celle de comprendre le « besoin », exprimé souvent de manière très partielle.
D’une certaine manière, la RI vise essentiellement à prendre en compte ces difficultés pour proposer des réponses les plus pertinentes possibles. La notion de pertinence est centrale ici: un document est pertinent s’il satisfait le besoin exprimé. Quand on utilise SQL, on considère que la réponse est toujours exacte car définie de manière mathématique (en fonction de l’état de la base). En RI, on ne peut jamais considérer qu’un résultat, constitué d’un ensemble de documents, est exact, mais on mesure son degré de pertinence (c’est-à-dire les erreurs du système de recherche) en distinguant:
les faux positifs: ce sont les documents non pertinents inclus dans le résultat; ils ont été sélectionnés à tort. En anglais, on parle de false positive.
les faux négatifs: ce sont les documents pertinents qui ne sont pas inclus dans le résultat. En anglais, on parle de false negative.
Les documents pertinents inclus dans le résultat sont appelés les vrais positifs, les documents non pertinents non inclus dans le résultat sont appelés les vrais négatifs. On le voit à ce qui vient d’être dit : on emploie le terme positif pour désigner ce qui a été ramené dans le résultat de recherche. À l’inverse, les documents qui sont négatifs ont été laissés de côté par le moteur de recherche au moment de faire correspondre des documents avec un besoin d’information. Et l’on désigne par vrai ce qui a été bien classé (dans le résultat ou hors du résultat).
Deux indicateurs formels, basés sur ces notions, sont couramment employés pour mesurer la qualité d’un système de RI.
La précision
La précision mesure la proportion des vrais positifs dans le résultat r. Si on note respectivement \(t_p(r)\) et \(f_p(r)\) le nombre de vrais et de faux positifs dans r (de taille \(|r|\)), alors
Une précision de 1 correspond à l’absence totale de faux positifs. Une précision nulle indique un résultat ne contenant aucun document pertinent.
Le rappel
Le rappel mesure la proportion des documents pertinents qui sont inclus dans le résultat. Si on note \(f_n(r)\) le nombre de documents faussement négatifs, alors le rappel est:
Un rappel de 1 signifie que tous les documents pertinents apparaissent dans le résultat. Un rappel de 0 signifie qu’il n’y a aucun document pertinent dans le résultat.
La Fig. 31 illustre (en anglais) ces concepts pour bien distinguer les ensembles dont on parle pour chaque requête de recherche et les mesures associées.
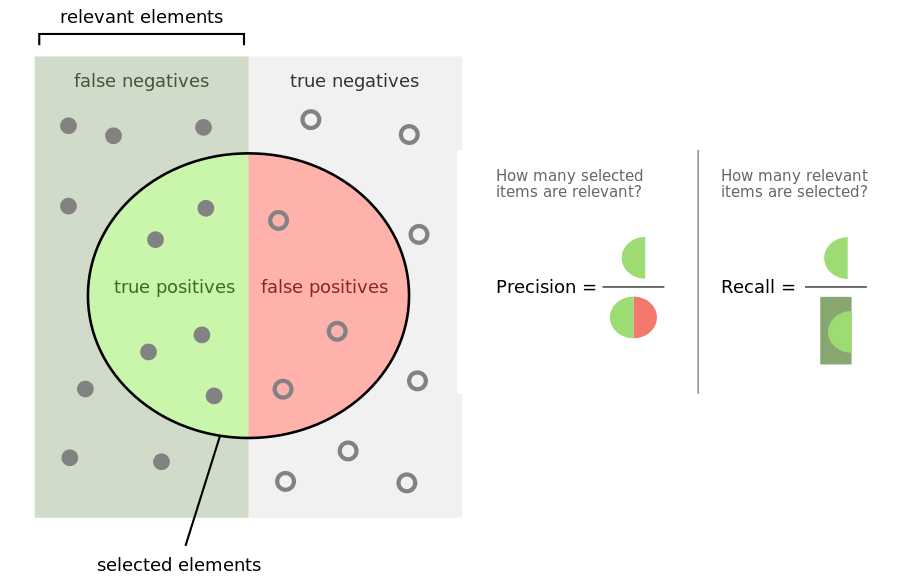
Fig. 31 Vrai, faux, positifs, négatifs.¶
Ces deux indicateurs sont très difficiles à optimiser simultanément. Pour augmenter le rappel, il suffit d’ajouter plus de documents dans le résultat, au détriment de la précision. À l’extrême, un résultat qui contient toute la collection interrogée a un rappel de 1, et une précision qui tend vers 0. Inversement, si on fait le choix de ne garder dans le résultat que les documents dont on est sûr de la pertinence, la précision s’améliore mais on augmente le risque de faux négatifs (c’est-à-dire de ne pas garder des documents pertinents), et donc d’un rappel dégradé.
L’évaluation d’un système de RI est un tâche complexe et fragile car elle repose sur des enquêtes impliquant des utilisateurs. Reportez-vous à l’ouvrage de référence cité au début du chapitre (et au matériel de cours associé) pour en savoir plus.
La recherche plein texte¶
Commençons par étudier une méthode simple de recherche pour trouver des documents répondant à une recherche dite « plein texte » constituée d’un ensemble de mots-clés. On va donner à cette recherche une définition assez restrictive pour l’instant: il s’agit de trouver tous les documents contenant tous les mots-clés. Prenons pour exemple l’ensemble (modeste) de documents ci-dessous.
\(d_1\):
Le loup est dans la bergerie.\(d_2\):
Le loup et le trois petits cochons\(d_3\):
Les moutons sont dans la bergerie.\(d_4\):
Spider Cochon, Spider Cochon, il peut marcher au plafond.\(d_5\):
Un loup a mangé un mouton, les autres loups sont restés dans la bergerie.\(d_6\):
Il y a trois moutons dans le pré, et un mouton dans la gueule du loup.\(d_7\):
Le cochon est à 12 le Kg, le mouton à 10 E/Kg\(d_8\):
Les trois petits loups et le grand méchant cochon
Et ainsi de suite. Supposons que l’on recherche tous les documents parlant de loups, de moutons mais pas de bergerie (c’est le besoin). Une solution simple consiste à parcourir tous les documents et à tester la présence des mots-clés. Ce n’est pas très satisfaisant car:
c’est potentiellement long, pas sur notre exemple bien sûr, mais en présence d’un ensemble volumineux de documents;
le critère « pas de bergerie » n’est pas facile à traiter;
les autres types de recherche (« le mot “loup” doit être près du mot “mouton” ») sont difficiles;
quid si je veux classer par pertinence les documents trouvés?
On peut faire mieux en créant une structure compacte sur laquelle peuvent s’effectuer les opérations de recherche. Les données sont organisées dans une matrice (dite d’incidence) qui représente l’occurrence (ou non) de chaque mot dans chaque document. On peut, au choix, représenter les mots en colonnes et les documents en ligne, ou l’inverse. La première solution semble plus naturelle (chaque fois que j’insère un nouveau document, j’ajoute une ligne dans la matrice). Nous verrons plus loin que la seconde représentation, appelée matrice inversée, est en fait beaucoup plus appropriée pour une recherche efficace.
Terme, vocabulaire.
Nous utilisons progressivement la notion de terme (token en anglais) qui est un peu différente de celle de « mot ». Le vocabulaire, parfois appelé dictionnaire, est l’ensemble des termes sur lesquels on peut poser une requête. Ces notions seront développées plus loin.
Commençons par montrer une matrice d’incidence avec les documents en ligne. On se limite au vocabulaire suivant: {« loup », « mouton », « cochon », « bergerie », « pré », « gueule »}.
Tableau 9 La matrice d’incidence¶ loup
mouton
cochon
bergerie
pré
gueule
\(d_1\)
1
0
0
1
0
0
\(d_2\)
1
0
1
0
0
0
\(d_3\)
0
1
0
1
0
0
\(d_4\)
0
0
1
0
0
0
\(d_5\)
1
1
0
1
0
0
\(d_6\)
1
1
0
0
1
1
\(d_7\)
0
1
1
0
0
0
\(d_8\)
1
0
1
0
0
0
Cette structure est parfois utilisée dans les bases de données sous le nom d’index bitmap. Elle permet de répondre à notre besoin de la manière suivante :
On prend les vecteurs d’incidence de chaque terme contenu dans la requête, soit les colonnes dans notre représentation :
Loup: 11001101
Mouton: 00101110
Bergerie: 01010011
On fait un
et(logique) sur les vecteurs de Loup et Mouton et on obtient 00001100Puis on fait un
etdu résultat avec le complément du vecteur de Bergerie (01010111)On obtient 00000100, d’où on déduit que la réponse est limitée au document \(d_6\), puisque la 6e position est la seule où il y a un “1”.
Les index inversés¶
Si on imagine maintenant des données à grande échelle, on s’aperçoit que cette approche un peu naïve soulève quelques problèmes. Posons par exemple les hypothèses suivantes:
Un million de documents, mille mots chacun en moyenne (ordre de grandeur d’une encyclopédie en ligne bien connue)
Disons 6 octets par mot, soit 6 Go (pas très gros en fait!)
Disons 500 000 termes distincts (ordre de grandeur du nombre de mots dans une langue comme l’anglais)
La matrice a 1 000 000 de lignes, 500 000 colonnes, donc \(500 \times 10^9\) bits, soit 62 GO. Elle ne tient pas en mémoire de nombreuses machines, ce qui va beaucoup compliquer les choses…. Comment faire mieux?
Une première remarque est que nous avons besoin des vecteurs pour les termes
(mots) pour effectuer des opérations logiques (and, or, not) et il
est donc préférable d’inverser la matrice pour disposer les termes en ligne
(la représentation est une question de convention: ce qui est important c’est
qu’au niveau de la structure de données, le vecteur d’incidence associé à un
terme soit stocké contigument en mémoire et donc accessible simplement et
rapidement). On obtient la structure de la Fig. 32
pour notre petit ensemble de documents.
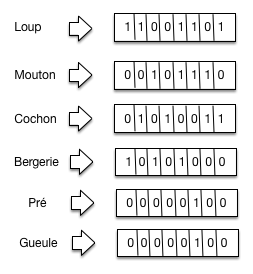
Fig. 32 Inversion de la matrice¶
Seconde remarque: la matrice d’incidence est creuse. En effet, sur chaque ligne, il y a au plus 1000 « 1 » (cas extrême où tous les termes du document sont distincts). Donc, dans l’ensemble de la matrice, il n’y a au plus que \(10^9\) positions avec des 1, soit un sur 500. Il est donc tout à fait inutile de représenter les cellules avec des 0. On obtient une structure appelée index inversé qui est essentiellement l’ensemble des lignes de la matrice d’incidence, dans laquelle on ne représente que les cellules correspondant à au moins une occurrence du terme (en ligne) dans le document (en colonne).
Important
Comme on ne représente plus l’ensemble des colonnes pour chaque ligne, il faut indiquer, pour chaque cellule, à quelle colonne elle correspond. Pour cela, on place dans les cellules l’identifiant du document (docId). De plus chaque liste est triée sur l’identifiant du document.
La Fig. 33 montre un exemple d’index inversé pour trois termes, pour une collection importante de documents consacrés à nos animaux familiers. À chaque terme est associé une liste inverse.
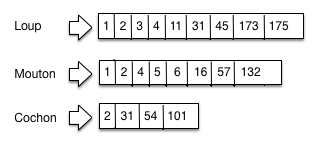
Fig. 33 Un index inversé¶
On parle donc de cochon dans les documents 2, 31, 54 et 101 (notez que les documents sont ordonnés — très important). Il est clair que la taille des listes inverses varie en fonction de la fréquence d’un terme dans la collection.
La structure d’index inversé est utilisée dans tous les moteurs de recherche. Elle présente d’excellentes propriétés pour une recherche efficace, avec en particulier des possibilités importantes de compression des listes associées à chaque terme.
Vocabulaire
Le dictionnaire (dictionary) est l’ensemble des termes de l’index inversé; le répertoire est la structure qui associe chaque terme à l’adresse de la liste inversée (posting list) associée au terme. Enfin on ne parle plus de cellule (la matrice a disparu) mais d’entrée pour désigner un élément d’une liste inverse.
En principe, le répertoire est toujours en mémoire, ce qui permet de trouver très rapidement les listes impliquées dans la recherche. Les listes inverses sont, autant que possible, en mémoire, sinon elles sont compressées et stockées dans des fichiers (contigus) sur le disque.
Opérations de recherche¶
Étant donné cette structure, recherchons les documents parlant de loup et de
mouton. On ne peut plus faire un et sur des tableaux de bits de taille fixe
puisque nous avons maintenant des listes de taille variable. L’algorithme
employé est une fusion (« merge ») de liste triées. C’est une technique très
efficace qui consiste à parcourir en parallèle et séquentiellement des listes,
en une seule fois. Le parcours unique est permis par le tri des listes sur un
même critère (l’identifiant du document).
La Fig. 34 montre comment on traite la requête loup
et mouton. On maintient deux curseurs, positionnés au départ au début de
chaque liste. L’algorithme compare les valeurs des docId contenues dans les
cellules pointées par les deux curseurs. On compare ces deux valeurs, puis:
(choix A) si elles sont égales, on a trouvé un document: on place son identifiant dans le résultat, à gauche; on avance les deux curseurs d’un cran
(choix B) sinon, on avance le curseur pointant sur la cellule dont la valeur est la plus petite, jusqu’à atteindre ou dépasser la valeur la plus grande.
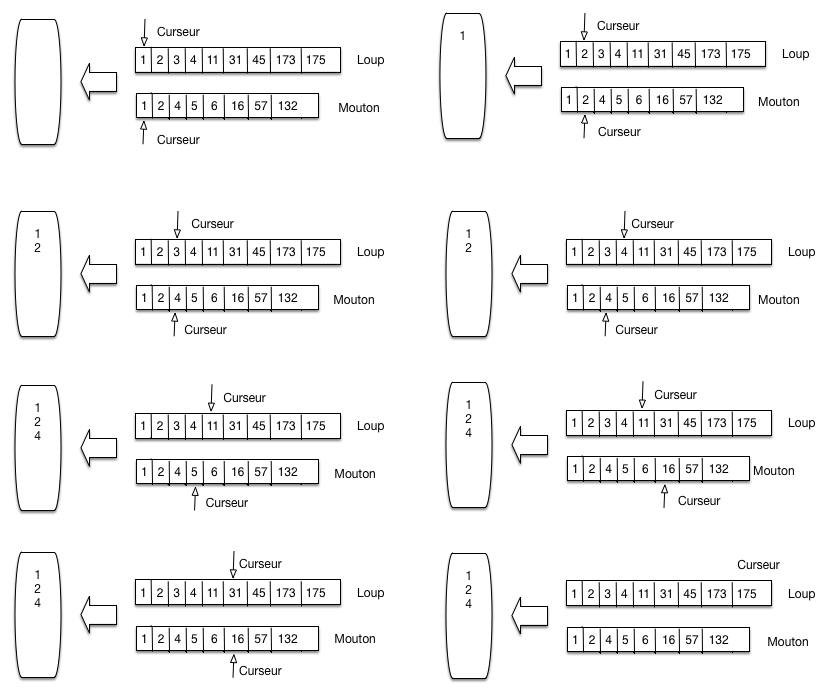
Fig. 34 Parcours linéaire pour la fusion de listes triées¶
La Fig. 34 se lit de gauche à droite, de haut en bas. On applique tout d’abord deux fois le choix A: les documents 1 et 2 parlent de loup et de mouton. À la troisième étape, le curseur du haut (loup) pointe sur le document 3, le pointeur du bas (mouton) sur le document 4. On applique le choix B en déplaçant le curseur du haut jusqu’à la valeur 4.
Et ainsi de suite. Il est clair qu’un seul parcours suffit. La recherche est linéaire, et l’efficacité est garantie par un parcours séquentiel d’une structure (la liste) très compacte. De plus, il n’est pas nécessaire d’attendre la fin du parcours de toutes les listes pour commencer à obtenir le résultat. L’algorithme est résumé ci-dessous.
// Fusion de deux listes l1 et l2
function Intersect($l1, $l2)
{
$résultat = [];
// Début de la fusion des listes
while ($l1 != null and $l2 != null) {
if ($l1.docId == $l2.docId) {
// On a trouvé un document contenant les deux termes
$résultat += $l1.docId;
// Avançons sur les deux listes
$l1 = $l1.next; $l2 = $l2.next;
}
else if ($l1.docId < $l2.docId) {
// Avançons sur l1
$l1 = $l1.next;
}
else {
// Avançons sur l2
$l2 = $l2.next;
}
}
}
C’est l’algorithme de base de la recherche d’information. Dans la version présentée ici, on satisfait des requêtes dites booléennes: l’appartenance d’un document au résultat est binaire, et il n’y a aucun classement par pertinence.
À partir de cette technique élémentaire, on peut commencer à raffiner, pour aboutir aux techniques sophistiquées visant à capturer au mieux le besoin de l’utilisateur, à trouver les documents qui satisfont ce besoin et à les classer par pertinence. Pour en arriver là, tout un ensemble d’étapes que nous avons ignorées dans la présentation abrégée qui précède sont nécessaires. Nous les reprenons dans ce qui suit.


S2: L’analyse de documents¶
Supports complémentaires:
En présence d’un document textuel un tant soit peu complexe, on ne peut pas se contenter de découper plus ou moins arbitrairement en mots sans se poser quelques questions et appliquer un pré-traitement du texte. Les effets de ce pré-traitement doivent être compris et maîtrisés: ils influent directement sur la précision et le rappel. Quelques exemples simples pour s’en convaincre:
si on cherche les documents contenant le mot « loup », on s’attend généralement à trouver ceux contenant « loups », « Loup », « louve »; il faut donc, quand on conserve un document dans Elasticsearch, qu’il soit en mesure de mettre ces différentes formes dans le même index inversé;
si on ne normalise pas (on conserve les majuscules et les pluriels), on va dégrader le rappel, puisqu’un utilisateur saisissant le mot-clef « loup » ne trouvera pas les documents dans lesquels ce terme apparaît seulement sous la forme « Loup » ou « loups »;
on le comprend immédiatement avec le cas de « loup / louve », il faut une connaissance experte de la langue pour décider que « louve » et « loup » doivent être associés, ce qui requiert une transformation qui dépend de la langue et nécessite une analyse approfondie du contenu;
inversement, si on normalise (retrait des accents, par exemple) « cote », « côte », « côté », on va unifier des mots dont le sens est différent, et on va diminuer la précision.
En fonction des caractéristiques des documents traités, des utilisateurs de notre système de recherche, il faudra trouver un bon équilibre, aucune solution n’étant parfaite. C’est de l’art et du réglage…
L’analyse se compose de plusieurs phases:
Tokenization: découpage du texte en « termes ».
Normalisation: identification de toutes les variantes d’écritures d’un même terme et choix d’une règle de normalisation (que faire des majuscules? acronymes? apostrophes? accents?).
Stemming (« racinisation »): rendre la racine des mots pour éviter le biais des variations autour d’un même sens (auditer, auditeur, audition, etc.)
Stop words (« mots vides »), comment éliminer les mots très courants qui ne rendent pas compte de la signification propre du document?
Ce qui suit est une brève introduction, essentiellement destinée à comprendre les outils prêts à l’emploi que nous utiliserons ensuite. Remarquons en particulier que les étapes ci-dessus sont parfois décomposées en sous-étapes plus fines avec des algorithmes spécifiques (par exemple, un pour les accents, un autre pour les majuscules). L’ordre que nous donnons ci-dessus est un exemple, il peut y avoir de légères variations. Enfin, notez bien que le texte transformé dans une étape sert de texte d’entrée à la transformation suivante (nous y reviendrons dans la partie pratique).
Tokenisation et normalisation¶
Un tokenizer prend en entrée un texte (une chaîne de caractères) et produit une séquence de tokens. Il effectue donc un traitement purement lexical, consistant typiquement à éliminer les espaces blancs, la ponctuation, les liaisons, etc., et à identifier les « mots ». Des transformations peuvent également intervenir (suppression des accents par exemple, ou normalisation des acronymes - U.S.A. devient USA).
La tokenization est très fortement dépendante de la langue. La première chose à faire est d’identifier cette dernière. En première approche on peut examiner le jeu de caractères (Fig. 35).

Fig. 35 Quelques jeux de caractères … exotiques¶
Il s’agit respectivement du: Coréen, Japonais, Maldives, Malte, Islandais. Ce n’est évidemment pas suffisant pour distinguer des langues utilisant le même jeu de caractères. Une extension simple est d’identifier les séquences de caractères fréquents, (n-grams). Des bibliothèques fonctionnelles font ça très bien (e.g., Tika, http://tika.apache.org)
Une fois la langue identifiée, on divise le texte en tokens (« mots »). Ce n’est pas du tout aussi facile qu’on le dirait!
Dans certaines langues (Chinois, Japonais), les mots ne sont pas séparés par des espaces.
Certaines langues s’écrivent de droite à gauche, de haut en bas.
Que faire (et de manière cohérente) des acronymes, élisions, nombres, unités, URL, email, etc.
Que faire des mots composés: les séparer en tokens ou les regrouper en un seul? Par exemple:
Anglais: hostname, host-name et host name, …
Français: Le Mans, aujourd’hui, pomme de terre, …
Allemand: Levensversicherungsgesellschaftsangestellter (employé d’une société d’assurance vie).
Pour les majuscules et la ponctuation, une solution simple est de normaliser systématiquement (minuscules, pas de ponctuation). Ce qui donnerait le résultat suivant pour notre petit jeu de données.
\(d_1\):
le loup est dans la bergerie\(d_2\):
le loup et les trois petits cochons\(d_3\):
les moutons sont dans la bergerie\(d_4\):
spider cochon spider cochon il peut marcher au plafond\(d_5\):
un loup a mangé un mouton les autres loups sont restés dans la bergerie\(d_6\):
il y a trois moutons dans le pré et un mouton dans la gueule du loup\(d_7\):
le cochon est à 12 euros le kilo le mouton à 10 euros kilo\(d_8\):
les trois petits loups et le grand méchant cochon
Stemming (racine), lemmatisation¶
La racinisation consiste à confondre toutes les formes d’un même mot, ou de mots apparentés, en une seule racine. Le stemming morphologique retire les pluriels, marque de genre, conjugaisons, modes, etc. Le stemming lexical fond les termes proches lexicalement: « politique, politicien, police (?) » ou « université, universel, univers (?) ». Ici, le choix influe clairement sur la précision et le rappel (plus d’unification favorise le rappel au détriment de la précision).
La racinisation est très dépendante de la langue et peut nécessiter une analyse linguistique complexe. En anglais, geese est le pluriel de goose, mice de mouse; les formes masculin / féminin en français n’ont parfois rien à voir (« loup / louve ») mais aussi (« cheval / jument »: parle-t-on de la même chose?) Quelques exemples célèbres montrent les difficultés d’interprétation:
« Les poules du couvent couvent »: où est le verbe, où est le substantif?
« La petite brise la glace »: idem.
Voici un résultat possible de la racinisation pour nos documents.
\(d_1\):
le loup etre dans la bergerie\(d_2\):
le loup et les trois petit cochon\(d_3\):
les mouton etre dans la bergerie\(d_4\):
spider cochon spider cochon il pouvoir marcher au plafond\(d_5\):
un loup avoir manger un mouton les autre loup etre rester dans la bergerie\(d_6\):
il y avoir trois mouton dans le pre et un mouton dans la gueule du loup\(d_7\):
le cochon etre a 12 euro le kilo le mouton a 10 euro kilo\(d_8\):
les trois petit loup et le grand mechant cochon
Il existe des procédures spécialisées pour chaque langue. En anglais, l’algorithme Snowball de Martin Porter fait référence et est toujours développé aujourd’hui. Il a connu des déclinaisons dans de nombreuses langues, dont le français, par un travail collaboratif.
Mots vides et autres filtres¶
Un des filtres les plus courants consiste à retire les mots porteurs d’une information faible (« stop words » ou « mots vides ») afin de limiter le stockage.
Les articles: le, le, ce, etc.
Les verbes « fonctionnels »: être, avoir, faire, etc.
Les conjonctions: et, ou, etc.
et ainsi de suite.
Le choix est délicat car, d’une part, ne pas supprimer les mots vides augmente l’espace de stockage nécessaire (et ce d’autant plus que la liste associée à un mot très fréquent est très longue), d’autre part les éliminer peut diminuer la pertinence des recherches (« pomme de terre », « Let it be », « Stade de France »).
Parmi les autres filtres, citons en vrac:
Majuscules / minuscules. On peut tout mettre en minuscules, mais on perd alors la distinction nom propre / nom commu,, par exemple Lyonnaise des Eaux, Société Générale, Windows, etc.
Acronymes. CAT = cat ou Caterpillar Inc.? M.A.A.F ou MAAF ou Mutuelle … ?
Dates, chiffres. Monday 24, August, 1572 – 24/08/1572 – 24 août 1572; 10000 ou 10,000.00 ou 10,000.00
Dans tous les cas, les même règles de transformation s’appliquent aux documents ET à la requête. Voici, au final, pour chaque document la liste des tokens après application de quelques règles simples.
\(d_1\):
loup etre bergerie\(d_2\):
loup trois petit cochon\(d_3\):
mouton etre bergerie\(d_4\):
spider cochon spider cochon pouvoir marcher plafond\(d_5\):
loup avoir manger mouton autre loup etre rester bergerie\(d_6\):
avoir trois mouton pre mouton gueule loup\(d_7\):
cochon etre douze euro kilo mouton dix euro kilo\(d_8\):
trois petit loup grand mechant cochon
S3: Introduction à ElasticSearch¶
Supports complémentaires
Dans cette section, nous allons passer au concret en introduisant les moteurs de recherche. Nous allons utiliser ici Elastic Search, un moteur de recherche qui s’installe et s’initialise très facilement. Nous indexerons nos premiers documents, et commencerons à faire nos premières requêtes.
ElasticSearch ou Solr
ElasticSearch est un moteur de recherche disponible sous licence libre (Apache). Il repose sur Lucene (nous verrons plus bas ce que cela signifie). Il a été développé à partir de 2004 et est aujourd’hui adossé à une entreprise, Elastic.co. Un autre moteur de recherche libre existe: Solr (prononcé « Solar »), lui aussi reposant sur Lucene. Bien que leurs configurations soient différentes, les fonctionnalités de ces deux moteurs sont comparables (cela n’a pas toujours été le cas). Nous choisissons ElasticSearch pour ce cours, mais vous ne devriez pas avoir beaucoup de difficultés à passer à Solr.
Nous allons nous appuyer entièrement sur les choix par défaut d’ElasticSearch pour nous concentrer sur son utilisation. La construction d’un moteur de recherche en production demande un peu plus de soin, nous en verrons au chapitre suivant les étapes nécessaires.
Architecture du système d’information avec un moteur de recherche¶
Un moteur de recherche comme ElasticSearch est une application spécialisée dans la recherche, qui s’appuie sur un index open source écrit en Java, Lucene. C’est-à-dire que l’implémentation des structures de données et les algorithmes de parcours vus dans la section précédente sont déléguées à Lucene (qui profite régulièrement des avancées des techniques de Recherche d’Information issues du monde académique).
Une question qui vient naturellement à l’esprit est alors: mais pourquoi ne pas utiliser directement le moteur de recherche comme gestionnaire des documents ? En effet, pourquoi s’embarrasser de MongoDB alors qu’ElasticSearch permet des recherches puissantes, efficaces, ainsi que le stockage et l’accès aux documents.
La réponse est qu’un système comme ElasticSearch est entièrement consacré à la recherche (donc à la lecture) la plus efficace possible de documents. Il s’appuie pour cela sur des structures compactes, compressées, optimisées (les index inversés) dont nous avons donné un aperçu. En revanche, ce n’est pas nécessairement un très bon outil pour les autres fonctionnalités d’une base de données. Le stockage par exemple n’est ni aussi robuste ni aussi stable, et il faut parfois reconstruire l’index à partir de la base originale (on parlera de réindexer les documents).
Un système comme ElasticSearch (ou Solr, ou un autre s’appuyant sur des index inversés) n’est pas non plus très bon pour des données souvent modifiées. Pour des raisons qui tiennent à la structure de ces index, les mises à jour sont coûteuses et s’effectuent difficilement en temps réel. La notion de mise à jour vaut ici aussi bien pour le contenu des documents (modification de la valeur d’un champ) que pour leur structure (ajout ou suppression d’un champ par exemple).
La pratique la plus courante consiste donc à utiliser un système de recherche comme un complément d’un serveur de base de données (relationnelle ou documentaire) et à lui confier les tâches de recherche que le serveur BD ne sait pas accomplir (soit, en gros, les recherches non structurées). Dans le cas des bases NoSQL, l’absence fréquente de tout langage de requête fait du moteur de recherche associé un outil indispensable.
Même en cas de présence d’un langage d’interrogation fourni par le système NoSQL, le moteur de recherche est un candidat tout à fait valide pour satisfaire les recherches plein texte et les recherches structurées. En résumé, à part les deux inconvénients (reconstruction depuis une source extérieure, support faible des mises à jour), les moteurs de recherche sont des composants puissants aptes à satisfaire efficacement les besoins d’un système documentaire.
Note
Les paragraphes ci-dessus sont à prendre avec réserve, car l’évolution d’un système comme Elastic Search montre qu’il tend à devenir également un gestionnaire robuste pour le stockage de documents. Il n’est pas exclu qu’Elastic Search devienne à terme une option tout à fait valable pour l’indexation et le stockage ce qui simplifierait l’architecture.
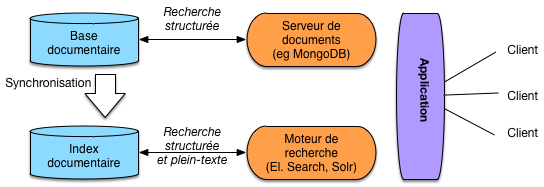
Fig. 36 Architecture d’une application avec moteur de recherche.¶
La Fig. 36 montre une architecture typique, en prenant pour exemple une base de données MongoDB. Les documents (applicatifs) sont donc dans la base MongoDB qui fournit des fonctionnalités de recherche structurées. On peut indexer la collection des documents applicatifs en extrayant des « champs » formant des documents (au sens d’ElasticSearch, Solr) fournis à l’index qui se charge de les organiser pour satisfaire efficacement des requêtes. L’application peut alors soit s’adresser au serveur MongoDB, soit au moteur de recherche.
Un scénario typique est celui d’une recherche par mot-clé dans un site. Les
données du site sont périodiquement extraites de la base et indexées dans
Elasticsearch. Ce dernier se charge alors de répondre à la fonctionnalité
Search que l’on trouve couramment sur tous les types de site.
Note
On pourrait se demander s’il n’est pas inefficace de dupliquer les documents de la base de données vers le moteur de recherche. En fait, c’est un inconvénient, mais assez mineur car on filtre généralement les documents de la base pour n’indexer que les champs soumis à des recherches plein texte comme le résumé du film. De plus, les données fournies ne sont pas stockées telles-quelles mais compressées et réorganisées dans des listes inversées. Le contenu de la base de données n’est donc pas un miroir de l’index géré par le moteur de recherche.
Mise en place d’ElasticSearch¶
Commençons par l’installation avec Docker. Voici une commande qui devrait fonctionner sous tous les systèmes et mettre ElasticSearch en attente sur le port 9200.
docker run -d --name es1 -p 9200:9200 elasticsearch:8.13.0
Les versions d’ElasticSearch
ElasticSearch évolue rapidement. Pour éviter que les instructions qui suivent ne deviennent rapidement obsolètes, j’indique le numéro de version dans l’installation avec Docker (la 8.13.0, de mars 2024).
Quelques commandes supplémentaires sont nécesssaires. Un compte elastic
est créé, on lui attribue un mot de passe avec la commande suivante:
docker exec -it es1 /usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic
Notez le mot de passe et placez-le éventuellement dans une variable d’environnement
export ELASTIC_PASSWORD=<le_mot_de_passe>
Si vous voulez interagir avec curl, il faut récupérer un certificat
d’authentification SSL.
docker cp es1:/usr/share/elasticsearch/config/certs/http_ca.crt .
Toutes les interactions avec un serveur ElasticSearch passent par une interface
REST basée sur JSON (revoyez au besoin le chapitre Interrogation de bases NoSQL). Vous
pouvez directement vous adresser au serveur REST en écoute
sur https://localhost:9200. Avec curl vous pouvez donc faire:
curl --cacert http_ca.crt -U elastic:mot_de_passe https://localhost:9200
Vous devriez obtenir un document JSON semblable à celui-ci:
{
"name": "7a46670f6a9e",
"cluster_name": "docker-cluster",
"cluster_uuid": "89U3LpNhTh6Vr9UUOTZAjw",
"version": {
"number": "8.13.0",
"...": "...",
"lucene_version": "9.1.1",
},
"tagline": "You Know, for Search"
}
Pour une inspection confortable du serveur et des index ElasticSearch, nous
vous conseillons d’utiliser une interface d’administration: ElasticVue,
disponible sous toutes les plateformes.
Elle peut être téléchargée ici: https://elasticvue.com/.
En lançant l’application, on peut se connecter au serveur https://localhost:9200
et on obtient l’interface de la figure Fig. 37.
La barre supérieure de l’interface propose des options REST
et SEARCH qui vont nous intéresser dans un premier temps.
Fig. 37 Le tableau de bord proposé par ElasticVue.¶
Première indexation¶
L’indexation dans un moteur de recherche, c’est l’opération qui consiste à
stocker un document, à l’aide des index. Nous allons dans ce qui suit indexer
un de nos films dans l’index nfe204-1. Elasticsearch
est par défaut assez souple et se charge d’inférer la nature des champs du
document que nous lui transmettons. Nous verrons dans le chapitre
Opérations de recherche avec ElasticSearch que l’on peut paramétrer précisément cette étape, pour
optimiser les performances d’ElasticSearch et améliorer l’expérience des
utilisateurs de notre application.
Téléchargez le document movie_1.json.
Pour créer l’index on envoie un PUT à l’adresse
https://localhost:9200/nfe204-1 pour créer la ressource.
C’est facile avec la fenêtre REST d’ElasticVue: voir
Fig. 38.
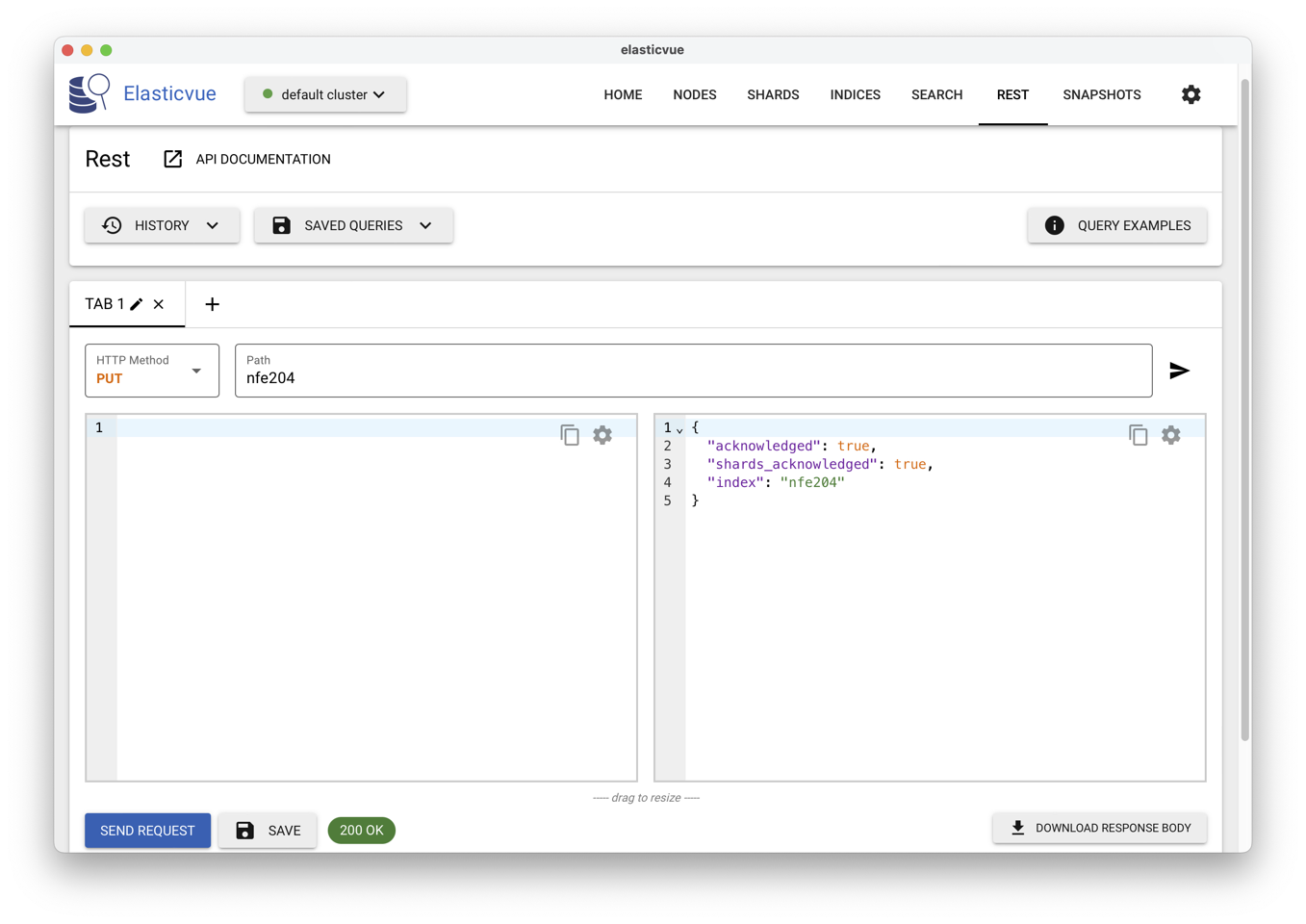
Fig. 38 Utilisation d’ElasticVue pour transmettre des commandes REST¶
Le PUT crée une « ressource » (au sens Web/REST du terme, cf. chapitre
Interrogation de bases NoSQL) à l’URL indiquée.
Nous pouvons maintenant insérer un document en transmettant
un POST à l’index https://localhost:9200/nfe204-1/_doc,
ou un PUT à l’adresse https://localhost:9200/nfe204-1/doc-id
où doc-id désigne l’identifiant du document.
Dans le cas du POST cet identifiant est pris dans le document lui-même
(champ _id) ou généré par ElasticSearch. Vous pouvez utiliser curl ou,
beaucoup plus facile, ElasticVue comme montré dans la Fig. 39.
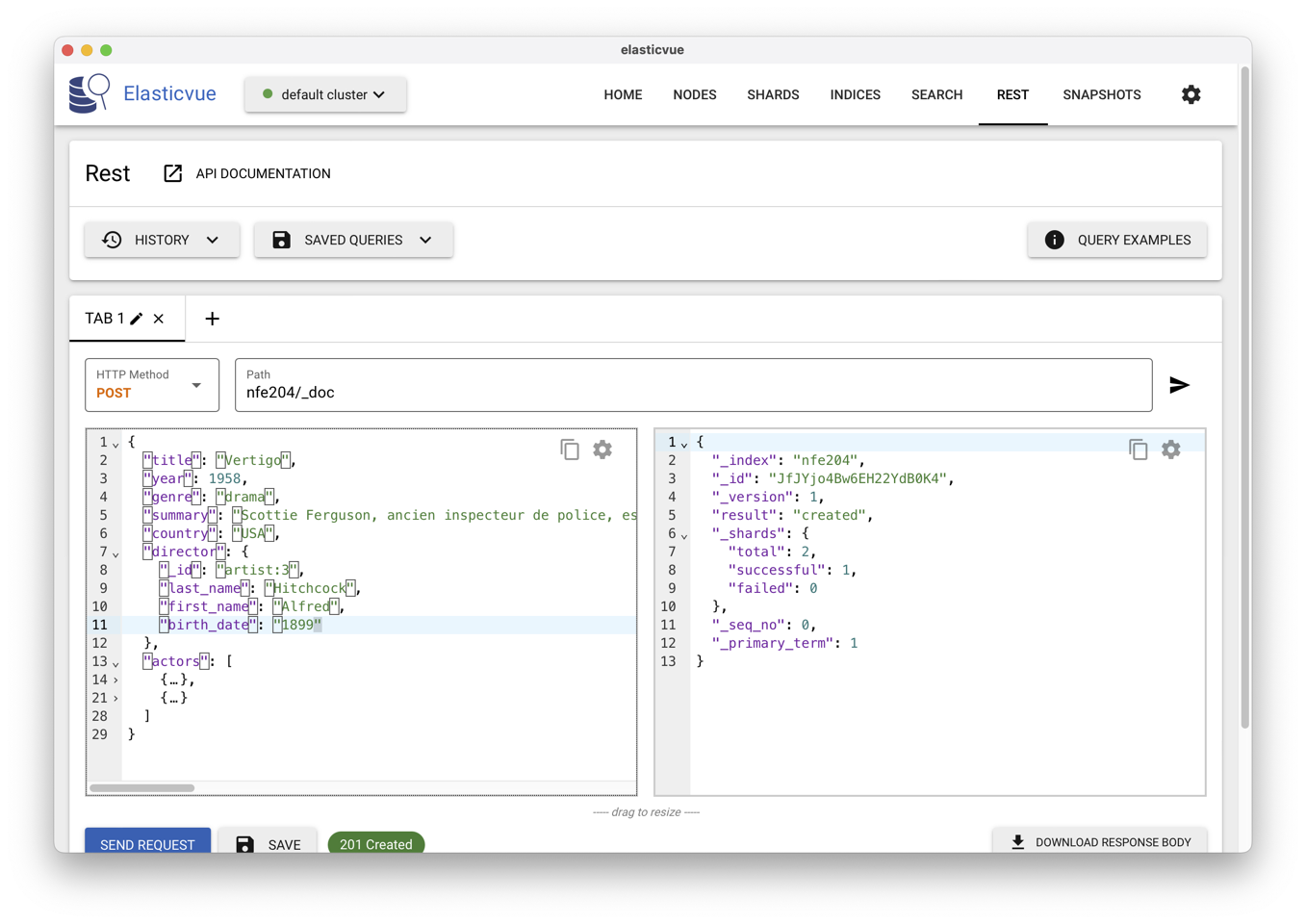
Fig. 39 Utilisation d’ElasticVue pour insérer un document¶
La ressource étant créée, un GET permet de la ramener. C’est le moment
de tester la fenêtre SEARCH d’ElasticVue qui devrait vous ramener
votre premier document.
Indexer davantage de documents¶
Il serait très fastidieux d’indexer un à un tous les documents d’une collection, d’autant plus que c’est une opération à répéter régulièrement pour mettre les documents du moteur de recherche à jour avec le contenu de la base.
Sinon, on risque d’avoir les deux situations suivantes, peu souhaitable pour les utilisateurs du système :
un document présent dans la source mais pas dans l’index, et donc non trouvé lors d’une recherche;
un document présent dans l’index mais détruit dans la source, trouvé donc par une recherche alors qu’il n’existe pas.
Nous verrons en
Travaux Pratiques comment automatiser tout de même cette synchronisation. Pour
le moment, nous allons nous contenter d’utiliser une autre interface
d’Elasticsearch, appelée bulk (en grosses quantités), qui permet comme son
nom l’indique d’indexer de nombreux documents en une seule commande.
Récupérez notre collection de films, au format JSON adapté à l’insertion en masse
dans ElasticSearch, sur le site http://deptfod.cnam.fr/bd/tp/datasets/. Le fichier
se nomme films_esearch.json.
Vous pouvez l’ouvrir pour voir le format. Chaque document
« film » (sur une seule ligne) est précédé d’un petit document JSON qui précise l’index (movies),
et l’identifiant (1).
{"index":{"_index": "nfe204", "_id": "movie"}}
On trouve ensuite les documents JSON proprement dits. Attention il ne doit pas y avoir de retour à la ligne dans le codage JSON, ce qui est le cas dans le document que nous fournissons.
{"title": "Mars Attacks!", "summary": "...", "...": "..."}
Ensuite, importez les documents dans Elasticsearch en le transmettant par
un POST à l’URL https://localhost:9200/_bulk/
Avec les paramètres spécifiés dans le fichier films_esearch.json, vous
devriez retrouver un index nfe204 maintenant présent dans l’interface, contenant
les données sur les films.
Nous sommes prêts à interroger notre moteur de recherche
en entrant des requêtes dans la fenêtre SEARCH.
Interrogation¶
Nous reverrons plus longuement les méthodes d’interrogation après avoir expliqué, dans le prochain chapitre, les techniques de classement. En attendant voici un premier aperçu qui vous permettra de vérifier que vos données sont bien là.
Une première méthode pour transmettre des recherches est de passer une expression en paramètre à l’URL à laquelle répond votre serveur ElasticSearch. La forme la plus simple d’expression est une liste de mots-clés. Voici quelques exemples d’URLs de recherche:
https://localhost:9200/nfe204/_search?q=alien
https://localhost:9200/nfe204/_search?q=alien,coppola
https://localhost:9200/nfe204/_search?q=alien,coppola,1994
Les dernières versions (à partir de la 8)
d’ElasticSearch ont introduit des mesures de sécurité qui compliquent
fortement l’accès direct au serveur en HTTPS. Mieux vaut donc utiliser
ElasticVue avec la fenêtre SEARCH qui se charge se constituer l’URL
de requête.
Une seconde méthode est de transmettre un document JSON décrivant la recherche. L’envoi
d’un document suppose que l’on utilise la méthode POST. Voici
par exemple un document avec une recherche sur trois mots-clé.
{
"query": {
"query_string" : {
"query" : "alien,coppola,1994"
}
}
}
La Fig. 40 montre l’exécution avec l’interface ElasticVue.
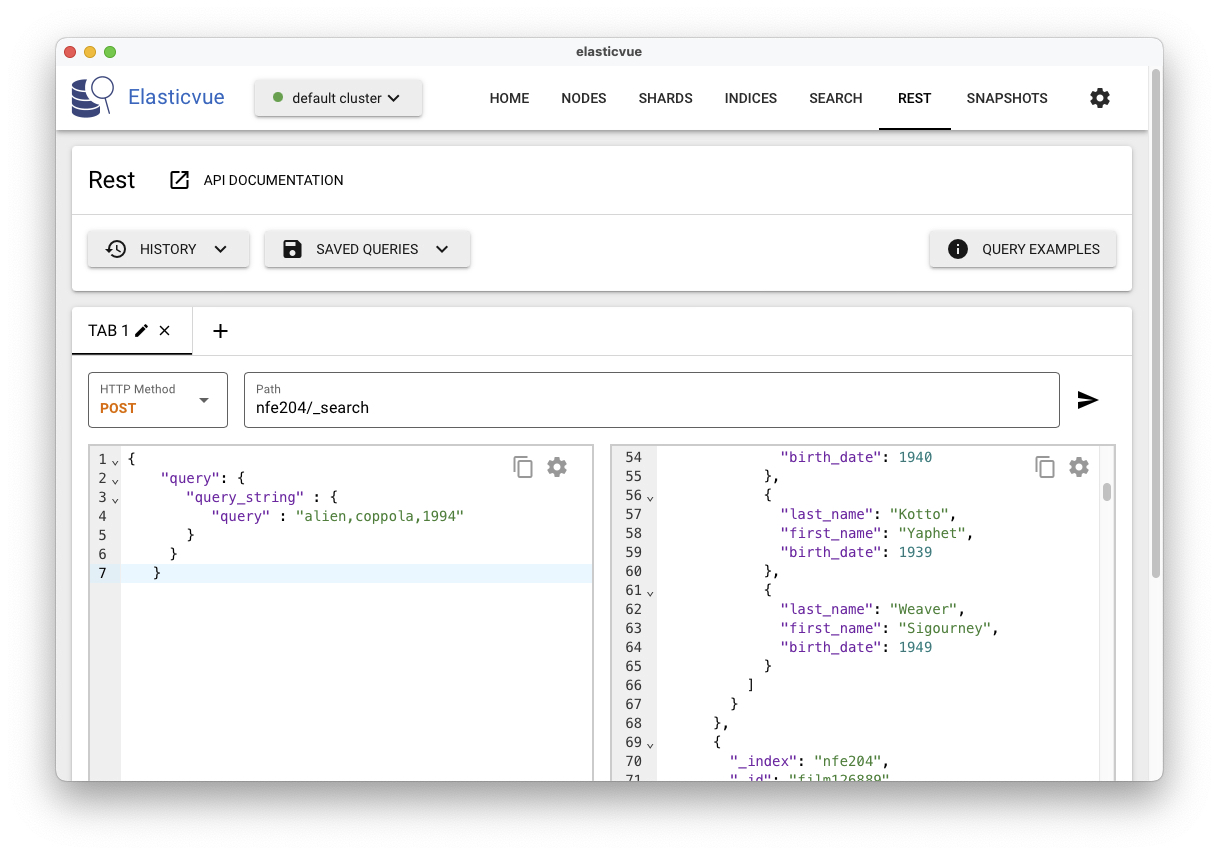
Fig. 40 L’interface ElasticVue avec recherches structurées¶
On voit clairement (mais partiellement) le résultat, produit sous la forme d’un
document JSON énumérant les documents trouvés dans un tableau hits. Notez
que le document indexé lui-même est présent, dans le champ _source,
correspondant à un comportement par défaut d’ElasticSearch: la totalité des documents sont dupliqués dans ElasticSearch: la
question de l’utilisation de deux systèmes qui semblent partiellement
redondants se pose. Nous revenons sur cette question plus loin.
Exprimer une recherche revient donc à envoyer à ElasticSearch
(utiliser la méthode POST) un document encodant la requête.
Le langage de recherche proposé par ElasticSearch, dit « DSL » pour Domain
Specific Language, est très riche. Pour vous donner juste un exemple,
voici comme on prend les 5 premiers documents d’une requête, en excluant la
source du résultat.
{
"from": 0,
"size": 5,
"_source": false,
"query": {
"query_string" : {
"query" : "matrix,2000,jamais"
}
}
}
Nous allons pour l’instant nous contenter d’une variante du language,
dite Query String, qui
correspond, essentiellement, au langage de base de Lucene. Toutes les
expressions données ci-dessous peuvent être entrées comme valeur du champ
query dans le document-recherche passé à l’interface REST.
Termes¶
La notion de base est celle de terme. Un terme est soit un mot, soit une séquence de mots (une phrase) placée entre apostrophes. La recherche:
Princess Leia
retourne tous les documents contenant soit « Princess », soit « Leia ». La recherche
"Princess Leia"
ramène les documents contenant les deux mots côte à côte (vous devez utiliser \ » pour intégrer un guillemet double dans une requête).
{
"query": {
"query_string" : {
"query" : "\"Princess Leia\""
}
}
}
Par défaut, la recherche s’effectue toujours sur tous les champs d’un document
indexé (ou , plus précisément, sur un champ _all dans lequel ElasticSearch
concatène toutes les chaînes de caractères). La syntaxe complète pour associer
le champ et le terme est:
champ:terme
Par exemple, pour ne chercher le mot-clé Alien que dans les titres des films, on peut
utiliser la syntaxe suivante :
{
"query": {
"query_string" : {
"query" : "title:alien"
}
}
}
Revenez au fichier JSON et à la structure de ses documents pour
voir que les données de chaque film sont imbriquées sous un champ fields.
Nous l’omettons dans la suite, pensez à l’ajouter.
Si on ne précise pas le champ, c’est celui par défaut qui est pris en compte. Les requêtes précédentes sont donc équivalentes à:
_all:"Princess Leia"
Les valeurs des termes (dans la requête) et le texte indexé sont tous deux soumis à des transformations que nous étudierons dans le chapitre suivant. Une transformation simple est de tout transcrire en minuscules. La requête:
_all:"PRINCESS LEIA"
devrait donc donner le même résultat, les majuscules étant converties en minuscules. La conception d’un index doit soigneusement indiquer les transformations à appliquer, car elles déterminent le résultat des recherches.
On peut spécifier un terme simple (pas une phrase) de manière incomplète
le “?” indique un caractère inconnue:
opti?aldésigneoptimal,optical, etc.le “*” indique n’importe quelle séquence de caractères (
opti*pour toute chaîne commençant paropti).
La valeur d’un terme peut-être indiquée de manière approximative en ajoutant le suffixe “-“, si l’on n’est pas sûr de l’orthographe par
exemple. Essayez de rechercher optimal, puis optimal-. La proximité des termes est établie par
une distance dite « distance d’édition » (nombre d’opérations d’éditions permettant de passer d’une valeur - optimal -
à une autre - optical).
Des recherches par intervalle sont possibles. Les crochets [] expriment des intervalles bornes comprises, les accolades {} des intervalles bornes non comprises. Voici comment on recherche tous les documents pour une année comprise entre 1990 et 2005:
year:[1990 TO 2005]
Connecteurs booléens¶
Les critères de recherche peuvent être combinés avec les connecteurs Booléens
AND, OR et NOT. Quelques exemples.
year:[1990 TO 2005] OR title:M*
year:[1990 TO 2005] AND NOT title:M*
Important
Attention à bien utiliser des majuscules pour les connecteurs Booléens.
Par défaut, un OR est appliqué, de sorte qu’une recherche sur plusieurs critères ramène l’union
des résultats sur chaque critère pris individuellement.
Venons-en maintenant à l’opérateur « + ». Utilisé comme préfixe d’un nom de champ, il indique que la valeur du champ doit être égale au terme. La recherche suivante:
+year:2000 title:matrix
recherche les documents dont l’année est 2000 (obligatoire) ou dont le titre
est matrix ou n’importe quel titre.
Quelle est alors la différence avec +year:2000? La réponse tient
dans le classement effectué par le moteur de recherche: les documents dont
le titre est matrix seront mieux classés que les autres. C’est une illustration,
parmi d’autres, de la différence entre « recherche d’information » et « interrogation
de bases de données ». Dans le premier cas, on cherche les documents les plus « proches »,
les plus « pertinents », et on classe par pertinence.
Mise en pratique¶
Exercice MEP-S2-1: mise en route ElasticSearch
Installez ElasticSearch sur votre machine selon les instruction précédentes. Insérez le fichier des films. Vous pouvez alors en profiter pour explorer les options de l’interface ElasticVue, ce qui vous facilitera les choses par la suite.
Exercices¶
Exercice Ex-S1-1: précision et rappel, calculons
Voici une matrice donnant les faux positifs et faux négatifs, vrais positifs et vrais négatifs pour une recherche.
Pertinent |
Non pertinent |
|
|---|---|---|
Ramené (positif) |
50 |
10 |
Non ramené (négatif) |
30 |
120 |
Quelques questions:
Donnez la précision et le rappel.
Quelle méthode stupide donne toujours un rappel maximal?
Quelles sont les valeurs possibles pour la précision si je tire un seul document au hasard?
Si j’effectue un tirage aléatoire, que penser de l’évolution de la précision et du rappel en fonction de la taille du tirage ?
Correction
Précision: 50 / 60
Rappel: 50 / 80
Ramener tous les documents
La précision est soit 1, soit 0.
Avec un tirage aléatoire, la relation entre espérance du rappel (plus précisément de l’espérance du rappel) et nombre de résultats est monotone croissante. La proportion pertinents / non pertinents reste constante en espérance. Evidemment, plus l’échantillon est restreint, plus cette hypothèse se fragilise, avec donc une variance qui augmente.
Exercice Ex-S1-2: précision et rappel, réfléchissons.
Soit un système qui affiche systématiquement 20 documents, ni plus ni moins, pour toutes les recherches. Indiquez quel est la précision et le rappel dans les cas suivants:
Mon besoin de recherche correspond à un document unique de la collection, il est affiché parmi les 20.
Ma base contient 100 documents, je veux tous les obtenir, le système m’en renvoie 20.
Je fais une recherche dont je sais qu’elle devrait me ramener 30 documents. Parmi les 20 que renvoie le système, je n’en retrouve que 10 parmi ceux attendus.
Correction
p = 1/20, r = 1/1 = 1
p = 20/20 = 1 ; r = 20/100 = 0.2
p = 10/20 = 0.5 ; r = 10/30 = 1/3
Exercice Ex-S1-3: proposons une autre mesure
Voici une autre mesure de qualité, que nous appellerons exactitude comme traduction de accuracy (exactitude). Elle se définit comme la fraction du résultat qui est correcte (en comptant les vrais positifs et vrais négatifs comme corrects). Donc,
Où p et n désignent les négatifs et positifs, t et f les vrais et faux, respectivement.
Cette mesure ne convient pas en recherche d’information. Pourquoi? Imaginez un système où seule une infime partie des documents sont pertinents, quelle que soit la recherche.
Quelle serait l’exactitude dans ce cas?
Quelle méthode simple et stupide donnerait une exactitude proche de la perfection?
Correction
L’exactitude tend vers 1
Il suffit de renvoyer un résultat vide, quelle que soit la requête.
Exercice Ex-S1-4: matrice d’incidence
Faire un fichier Excel (ou l’équivalent) qui calcule la taille d’une collection, la taille de la matrice d’incidence, et la densité de 1 dans cette matrice, en fonction des paramètres suivants :
n, le nombre de documents,
d, le nombre de termes distincts,
m, le nombre moyen de mots dans un document,
w, la taille moyenne d’un mot (en octets).
Exercice Ex-S1-5: algorithme de négation
On sait faire une fusion pour une recherche de type ET. La recherche de type OU est évidente (?). Montrer qu’un algorithme similaire existe pour une recherche de type NOT (« les documents qui parlent de loup mais pas de mouton »).
Exercice Ex-S1-6: recherches
Exprimez les recherches suivantes sur votre base de données
les films dans lesquels on parle d’un « meurtrier »;
même critère, mais en ajoutant le mot-clé « féroce »;
films avec Kate Winslett et Leonardo di Caprio;
films qui sont soit des drames, soit du fantastique;
films avec le mot-clé « France »; obtient-on les films produits en France? Sinon pourquoi? Que faudrait-il faire?
on recherche le film « Sleepy Hollow »; effectuez une recherche sur le titre (« Sleepy », « Hollow », « Sleepy Hollow ») puis sur le résumé.
films satisfaisant une combinaison de critères: parus entre 1990 et 2000 et aux USA, ou contenant les mots-clés « Michael » et « Sonny »;
etc.
Vous êtes invités à effectuer les recherches avec ou sans majuscules, à chercher des phrases comme « féroce et meurtrier », à indiquer ou non des noms de champs, et à interpréter les résultats (ou l’absence de résultat) obtenus.

Ce cours de Philippe Rigaux est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Table Of Contents
- Introduction
- Préliminaires: Docker
- Modélisation de bases NoSQL
- Interrogation de bases NoSQL
- MapReduce, premiers pas
- Cassandra - Travaux Pratiques
- MongoDB - Travaux Pratiques
- Introduction à la recherche d’information
- Principes du classement de documents
- Opérations de recherche avec ElasticSearch
- Le cloud, une nouvelle machine de calcul
- Systèmes NoSQL: la réplication
- Systèmes NoSQL: le partitionnement
- Calcul distribué: Hadoop et MapReduce
- Traitement de données massives avec Apache Spark
- Traitement de flux massifs avec Apache Flink
- Pig : Travaux pratiques
- Projets NFE204
- Annales des examens
Recherche
Saisissez un ou plusieurs mots-clés.