La plupart des systèmes étudiés dans ce cours peuvent s’installer et s’exécuter
avec l’environnement Docker (http://www.docker.com). Docker permet
d’émuler un système distribué de serveurs.
Un serveur est une entité
qui fournit un service (!). Concrètement:
un serveur (machine) est un ordinateur, tournant sous un système d’exploitation,
et connecté en permanence au réseau via des ports; un serveur machine est
identifiable sur le réseau par son adresse IP.
un serveur (logiciel), ou service, est un processus exécuté en tâche de fond d’un serveur machine qui
communique avec des clients (logiciels) via un port particulier.
un système distribué est constitué de plusieurs services qui communiquent les uns
avec les autres ; ces services peuvent ou non être répartis sur plusieurs serveurs-machine.
un client (logiciel) est un programme qui communique avec un service;
une machine virtuelle est un programme qui simule, sur une machine hôte,
un autre ordinateur.
Exemple.
Un serveur web est un processus (Apache par exemple) qui communique sur le
port 80 d’un serveur machine. Si ce serveur machine a pour IP 163.12.9.10, alors tout
client web (Firefox par exemple) peut s’adresser au serveur web à l’adresse 163.12.9.10:80.
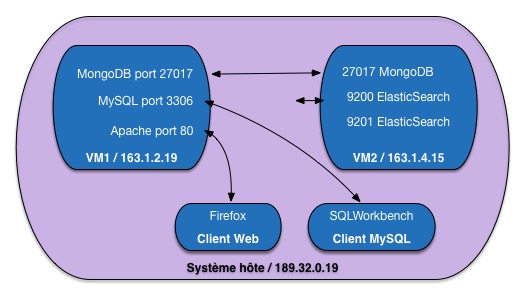
La Fig. 1 illustre ces concepts de base, que nous utiliserons maintenant
intensivement sans plus d’explication. Elle montre dans une machine physique (le
« système hôte ») deux machines virtuelles. Chacune de ces machines dispose
d’une adresse IP qui lui est propre, et propose des services en écoute sur certains ports.
Un serveur MongoDB est présent par exemple sur chacune des deux machines, en écoute
sur le port par défaut 27017, la différentiation des serveurs se faisant donc dans
ce cas par l’adresse IP du serveur qui les héberge.
Inversement, on peut avoir deux serveurs identiques sur une
même machine, mais sur des ports différents. C’est ce qu’illustre
la présence de deux serveurs ElasticSearch sur la seconde machine virtuelle,
sur les ports respectifs 9200 et 9201.
Fig. 1 Un exemple de système distribué, avec serveurs virtuels et clients¶
Avant de donner
quelques explications plus élaborées, il vous suffit de considérer que Docker permet d’installer
et d’exécuter très facilement, sur votre ordinateur personnel, et avec
une consommation de ressources (mémoire et disque) très faible, ce que nous appellerons
pour l’instant des « pseudos-serveurs » en attendant d’être plus précis.
Docker offre deux très grands avantages.
il propose des pseudo-serveurs pré-configurés, prêts à l’emploi (les « images »),
qui s’installent en quelques clics;
il est tout aussi facile d’installer plusieurs pseudos-serveurs communiquant
les uns avec les autres et d’obtenir donc un système distribué complet, sur
un simple portable (doté d’une puissance raisonnable).
Docker permet de transformer un simple ordinateur personnel en data center! Bien entendu, il n’en a
pas la puissance mais pour tester et expérimenter, c’est extrêmement pratique.
Installation: Docker existe sous tous les systèmes, dont Windows. Pour Windows et Mac OS, un installateur
Docker Desktop
est fourni à https://www.docker.com/products/docker-desktop. Il contient tous les composants nécessaires
à l’utilisation de Docker.
Note
Merci de me signaler des compléments qui seraient utiles à intégrer dans le présent
document, pour les environnements différents de Mac OS X, et notamment Windows.
Essayons de comprendre ce qu’est Docker avant d’aller plus loin. Vous connaissez
peut-être déjà la notion de machine virtuelle (VM). Elle consiste à simuler
par un composant logiciel, sur une machine physique, un ordinateur
auquel on alloue une partie des ressources (mémoire, CPU). Partant
d’une machine dotée par exemple de 4 disques et 256 GO de mémoire, on
peut créer 4 VMs indépendantes avec chacune 1 disque et 64 GO de RAM. Ces
VMs peuvent être totalement différentes les unes des autres. On peut en avoir
une sous le système Windows, une autre sous le système Linux, etc.
L’intérêt des VMs est principalement la souplesse et l’optimisation
de l’utilisation des ressources matérielles. L’organisation en VMs
rend plus facile la réaffectation, le changement du dimensionnement,
et améliore le taux d’utilisation des dispositifs physiques (disque, mémoire,
réseau, etc.).
Les VMs ont aussi l’inconvénient d’être assez gourmandes en ressource, puisqu’il
faut, à chaque fois, faire tourner un système d’exploitation complet, avec tout
ce que cela implique, en terme d’emprise mémoire notamment.
Docker propose une solution beaucoup plus légère, basée sur la capacité
du système Linux (généralisée à Mac OS et Windows) à créer des espaces isolés auxquels on affecte une partie
des ressources de la machine-hôte. Ces espaces, ou containers partitionnent
en quelque sorte le système-hôte en sous-systèmes étanches, au sein desquels
le nommage (des processus, des utilisateurs, des ports réseaux) est purement local.
On peut par exemple faire tourner un processus apache sur le port 80
dans le conteneur A, un autre processus apache sur le port 80 dans le conteneur B,
sans conflit ni confusion.
Tous les nommages sont en quelque sorte interprétés par rapport à un container donné (notion
d’espace de nom).
Les conteneurs sont beaucoup plus légers en consommation de ressources que
les VMs, puisqu’ils s’exécutent au sein d’un unique système d’exploitation. Docker
exploite cette spécificité pour proposer un mode de virtualisation
(que nous avons appelé « pseudo-serveur » en préambule) léger et flexible.
Docker (ou, très précisément, le docker engine) est un
programme qui va nous permettre de créer des conteneurs et d’y installer
des environnements prêts à l’emploi, les images.
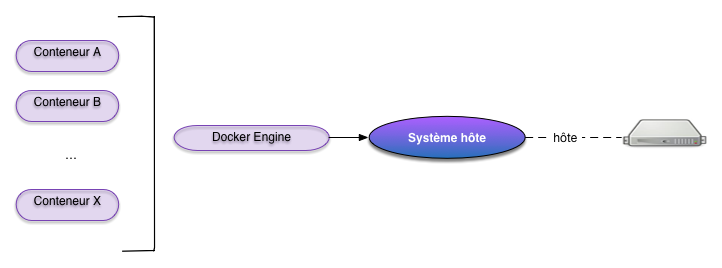
Un peu de vocabulaire: dans tout ce qui suit,
Le système hôte est le système d’exploitation principal gérant votre machine ;
c’est par exemple Windows, ou Mac OS.
Docker engine ou moteur docker est le programme qui gère les conteneurs.
Un conteneur est une partie autonome du système hôte, se comportant comme une
machine indépendante.
Le client Docker est l’utilitaire grâce auquel on transmet au moteur
les commandes de gestion de ces conteneurs.
Il peut s’agir soit de la ligne de commande (Docker CLI) ou du dashboard
intégré au Docker desktop.
Fig. 2 Le système hôte, le docker engine et les conteneurs¶
Un conteneur Docker peut donc être vu comme un sous-système autonome, mobilisant
très peu de ressources car l’essentiel des tâches système est délégué au système
dans lequel il est instancié. On dispose donc virtuellement d’un moyen
de multiplier à peu de frais des pseudo-machines dans lesquelles on pourait installer
« à la main » des logiciels divers et variés.
Docker va un peu plus loin en proposant des installations pré-configurées, empaquetées
de manière à pouvoir être placées très facilement dans un conteneur. On les appelle
des images. On peut ainsi trouver des images avec pré-configuration de serveurs de
données (Oracle, Postgres, MySQL), serveurs Web (Apache, njinx), serveurs NoSQL
(mongodb, cassandra), moteurs de recherche (ElasticSearch, Solr). L’installation
d’une image se fait très simplement, et soulage considérablement des tâches parfois
pénibles d’installation directe.
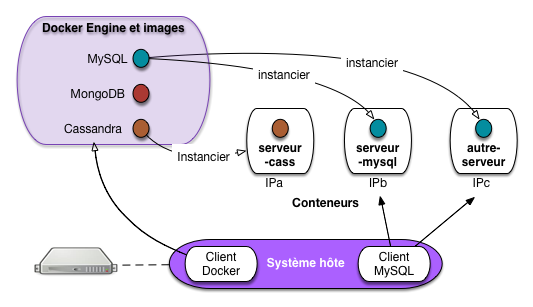
Fig. 3 Les images docker, constituant un pseudo système distribué¶
Une image se place dans un conteneur. On peut placer la même image dans plusieurs
conteneurs et obtenir ainsi un système distribué. Examinons la
Fig. 3 montrant une configuration complète.
Nous avons tous les composants à l’œuvre, essayons de bien comprendre.
Le système hôte exécute le Docker Engine, un processus qui gère les images
et instancie les conteneurs.
Docker a téléchargé (nous verrons comment plus tard) les images
de plusieurs systèmes de gestion de données: MySQL, MongoDB (un système
NoSQL que nous étudierons), et Cassandra.
Ces images ont été instanciées dans des conteneurs A, B et C. L’instanciation
consiste à installer l’image dans le conteneur et à l’exécuter. Nous avons
donc deux conteneurs avec l’image MySQL, et un troisième avec l’image Cassandra.
Chacun de ces conteneurs dispose de sa propre adresse IP. En supposant que
les ports par défaut sont utilisés, le premier serveur MySQL
est donc accessible à l’adresse IPb, sur le port 3306, le second
à l’adresse IPc, sur le même port.
Important
Le docker engine implante un système automatique
de « renvoi » qui « publie » le service d’un conteneur sur
le port correspondant du système hôte. Le premier
conteneur MySQL par exemple est aussi accessible sur le port 3306
de la machine hôte. Pour le second, ce n’est pas possible car le port
est déjà occupé, et il faut donc configurer manuellement ce renvoi:
nous verrons comment le faire.
L’ensemble constitue donc un système distribué virtuel, le tout s’exécutant
sur la machine-hôte
et gérable très facilement grâce aux utilitaires Docker. Nous avons par exemple dans
chaque conteneur un serveur MySQL. Maintenant, on peut se connecter à ces serveurs
à partir de la machine-hôte avec une application cliente (par exemple phpMyAdmin)
et tester le système distribué, ce que nous ferons tout au long du cours.
On peut instancier l’image de MongoDB dans 4 conteneurs et obtenir un cluster MongoDB
en quelques minutes. Evidemment, les performances globales ne dépasseront pas celle
de l’unique machine hébergeant Docker. Mais pour du développement ou de l’expérimentation,
c’est suffisant, et le gain en temps d’installation est considérable.
En résumé: avec Docker, on dispose d’une boîte à outils pour émuler des environnements
complexes avec une très grande facilité.
Dans ce qui suit, je vais illustrer les commandes avec l’utilitaire de commandes en ligne
en prenant l’exemple de ma machine Mac OS X. Ce
ne doit pas être fondamentalement différent sous les autres environnements.
Note
Vous préférerez sans doute à juste titre utiliser un outil graphique comme le
Docker desktop, décrit dans la prochaine section, mais avoir un aperçu de commandes transmises par ce dernier est toujours utile
pour comprendre ce qui se passe.
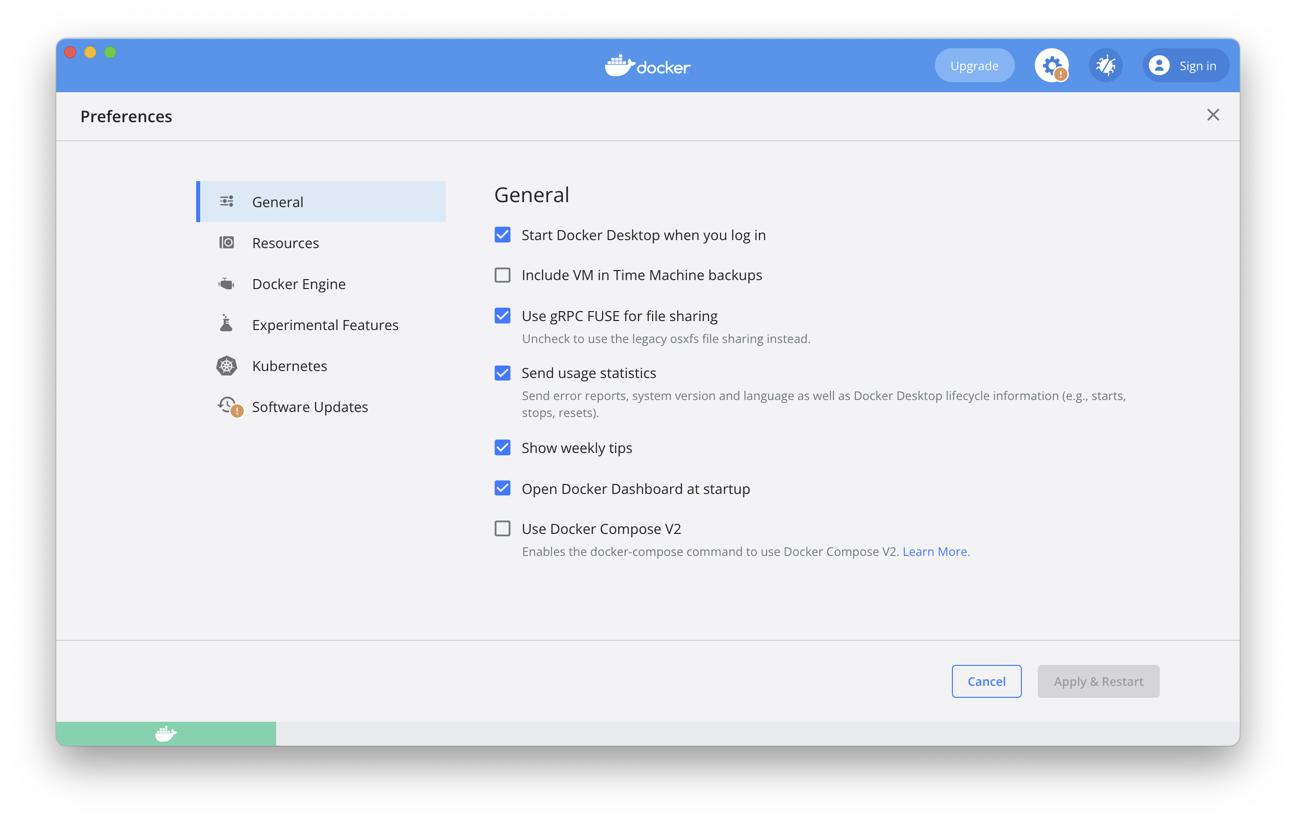
Sous Mac OS ou Windows, vous disposez du Docker Desktop qui vous permet de
lancer la machine virtuelle et
d’obtenir une interface graphique pour gérer votre docker engine.
La Fig. 4 montre
la fenêtre des paramètres.
Pour communiquer avec le moteur Docker, on peut
utiliser un programme client en ligne de commande nommé simplement docker.
L’image la plus simple est un Hello world, on l’instancie avec la commande suivante:
docker run hello-world
Le run est la commande d’instanciation d’une nouvelle image dans un conteneur Docker. Voici
ce que vous devriez obtenir à la première exécution.
docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
4276590986f6: Pull complete
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
Décryptons à nouveau. La machine Docker a cherché dans son répertoire local pour savoir si l’image
hello-world était déjà téléchargée. Ici, comme c’est notre première exécution, ce n’est pas le
cas (message Unabletofindimagelocally). Docker va donc télécharger l’image et l’instancier.
Le message HellofromDocker. s’affiche, et c’est tout.
L’utilité est plus que limitée, mais cela montre à toute petite
échelle le fonctionnement général: on choisit une image, on applique run et Docker se charge du reste.
La liste des images est disponible avec la commande:
docker images
Voici le type d’affichage obtenu:
REPOSITORY TAG IMAGE ID CREATED SIZE
docker101tutorial latest be967614122c 4 days ago 27.3MB
mysql latest e1d7dc9731da 12 days ago 544MB
python alpine 0f03316d4a27 13 days ago 42.7MB
nginx alpine 6f715d38cfe0 5 weeks ago 22.1MB
docker/getting-started latest 1f32459ef038 2 months ago 26.8MB
hello-world latest bf756fb1ae65 8 months ago 13.3kB
Une image est instanciée dans un conteneur avec la commande run.
docker run --name 'nom-conteneur' <options>
Les options dépendent de l’image: voir les sections suivantes pour des exemples.
La liste des conteneurs est disponible avec la commande:
docker ps -a
L’option -a permet de voir tous les conteneurs, quel que soit leur statut (en arrêt, ou
en cours d’exécution). On obtient l’affichage suivant:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d1c2291dc9f9 mysql:latest "docker-entrypoint.s…" 16 minutes ago Exited (1) 9 minutes ago mysql
ec5215871db3 hello-world "/hello" 19 minutes ago Exited (0) 19 minutes ago relaxed_mendeleev
Notez le premier champ, CONTAINERID qui nous indique l’identifiant par
lequel on peut transmettre des
instructions au conteneur. Voici les plus utiles, en supposant que le conteneur est d1c2291dc9f9.
Tout d’abord on peut
l’arrêter avec la commande stop.
docker stop d1c2291dc9f9
Arrêter un conteneur ne signifie pas qu’il n’existe plus, mais qu’il n’est plus actif.
On peut le relancer avec la commande start.
docker start mon-conteneur
Pour le supprimer, c’est la commande dockerrm. Pour inspecter la configuration système/réseau d’un conteneur,
Docker fournit la
commande inspect.
docker inspect mon-conteneur
On obtient un large document JSON. Parmi toutes les informations données,
l’adresse IP du coneneur est particulièrement intéressante. On l’obtient avec
Testons Docker avec un des services les plus simples qui soient: un serveur web,
Apache.
La démarche générale pour une installation
consiste à chercher l’image qui vous convient sur le site https://hub.docker.com qui donne
accès au catalogue des images Docker fournies par la communauté des utilisateurs.
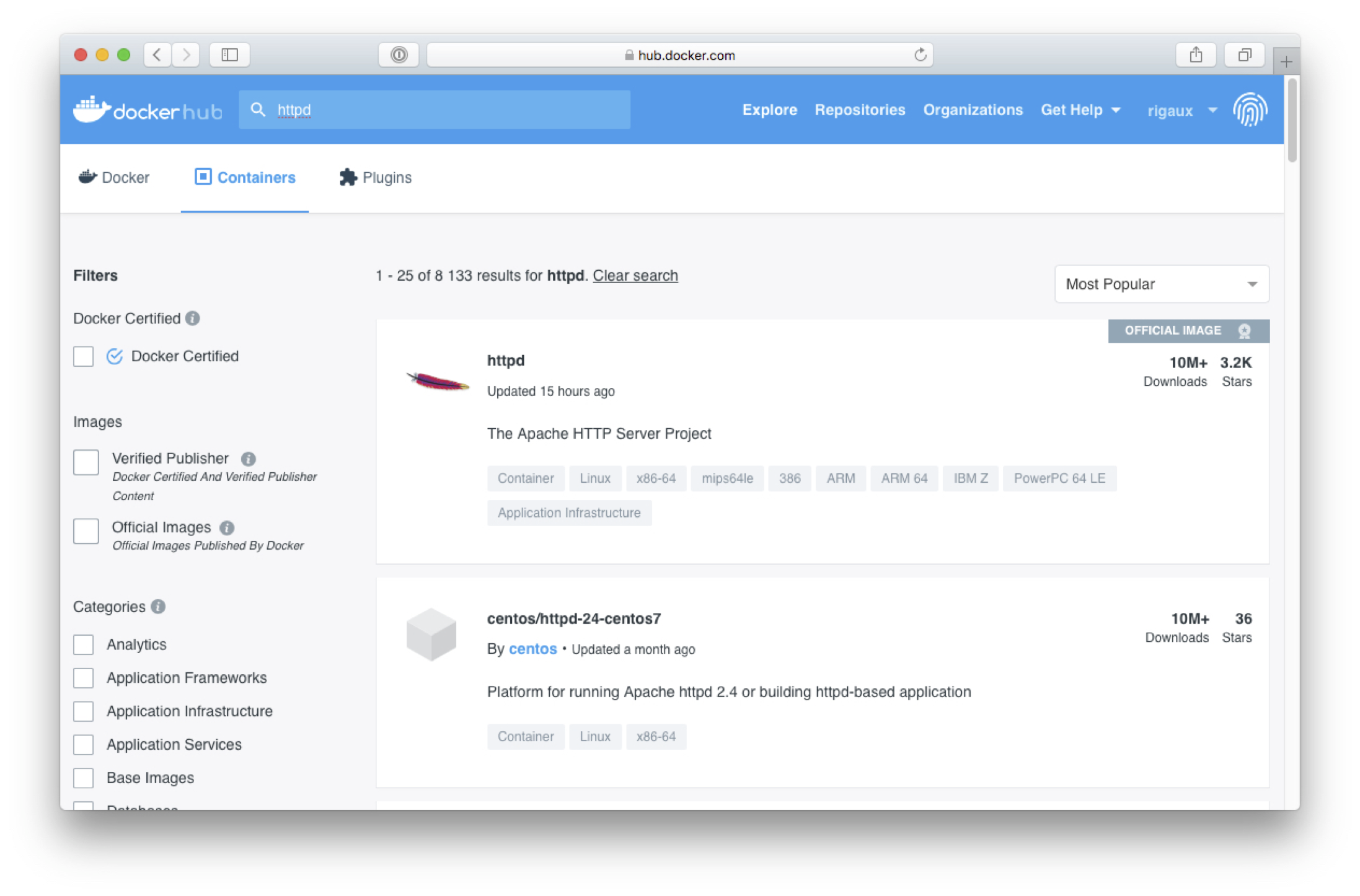
Faites une recherche avec le mot-clé « httpd » (correspondant aux images
du serveur web Apache). Comme on pouvait s’y attendre, de nombreuses images
sont disponibles.
La plus standard s’appelle tout simplement httpd (Fig. 5).
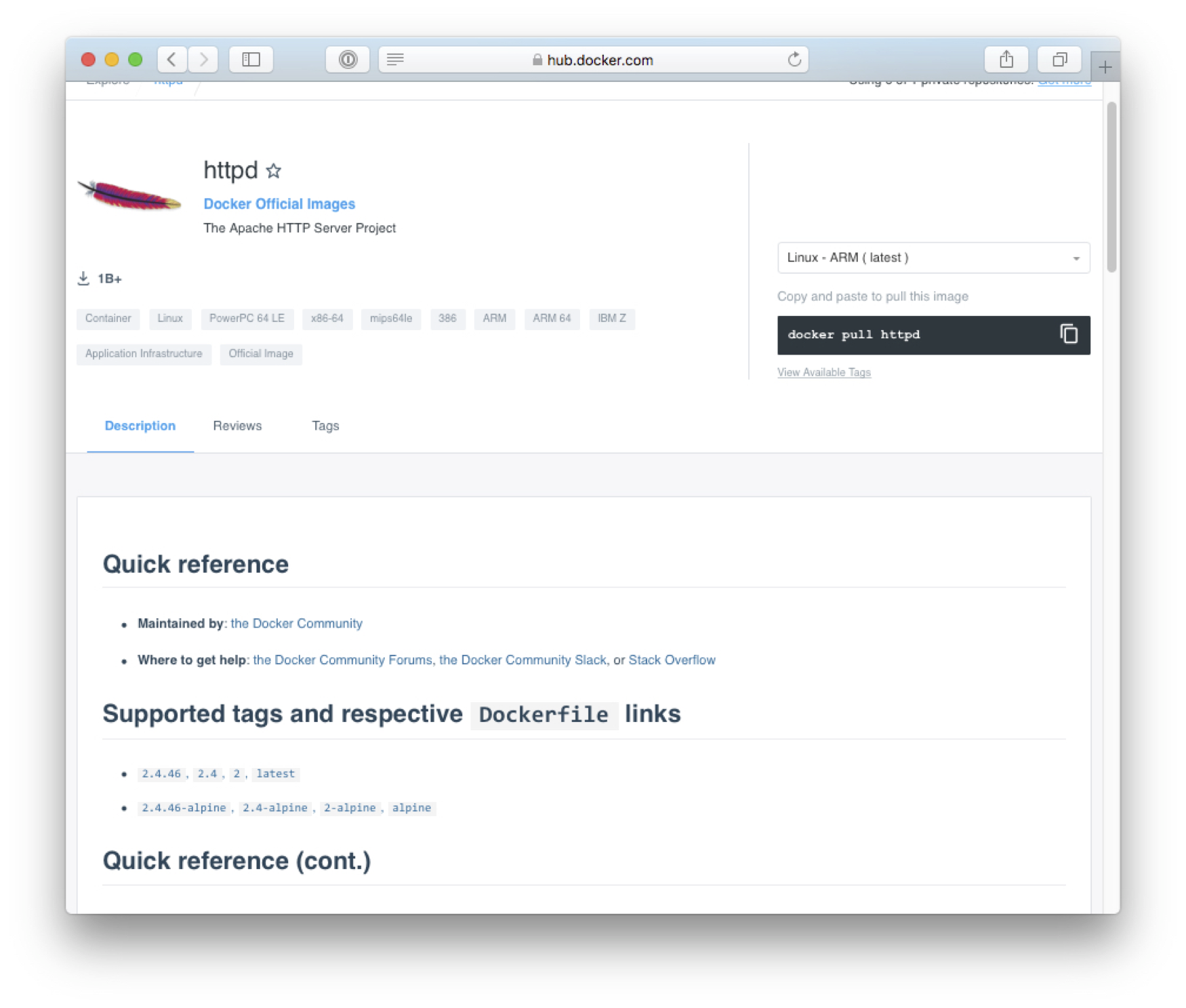
Choisissez une image, et cliquez sur le bouton Details pour
connaître les options d’installation. En prenant
l’image standard, on obtient la page de documentation illustrée par
la Fig. 6
Fig. 6 Documentation d’installation de l’image httpd¶
Vous avez deviné ce qui reste à faire. Installez l’image dans un conteneur sur votre machine avec
la commande suivante:
docker run --name serveur-web1 --detach httpd:latest
Voici les options choisies:
name est le nom du conteneur: il peut remplacer l’id du conteneur quand on veut l’arrêter / le relancer, etc.
--detach (ou -d) indique que le conteneur
est lancé en tâche de fond, ce qui évite de bloquer le terminal
on indique enfin l’image à utiliser, ainsi que la version: prenez latest (ou ne précisez rien)
sauf si vous avez de bonnes raisons de faire autrement.
La première fois, l’image doit être téléchargée, ce qui peut prendre un certain temps. Par la suite, le
lancement du conteneur instanciant l’image est quasi instantané.
C’est tout! Vous avez installé et lancé un serveur web. Vous pouvez le vérifier avec
la commande suivante qui donne la liste des conteneurs en cours d’exécution.
docker ps
Vous devriez obtenir le résultat suivant. Notez le port sur lequel
opn peut communiquer avec le service sur le conteneur, et le nom
du conteneur.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d02a690e0253 httpd:latest "httpd-foreground" 3 minutes ago Up 3 minutes 80/tcp serveur-web1
Le serveur web est donc accessible sur le port 80 du conteneur. Pour y accéder
il faut donc connaître l’adresse IP de ce dernier (c’est possile: voir ci-dessous).
Il existe une possibilité plus pratique: renvoyer le port du conteneur
vers la machine-hôte.
Docker fournit un mécanisme dit de publication pour indiquer sur quel
port se met en écoute un conteneur. On spécifie simplement avec l’option
--publish (ou -p) comment on associe un port du conteneur à un port du
système hôte. Exemple:
docker run --name serveur-web2 --publish 81:80 --detach httpd:latest
Ou plus simplement
docker run --name serveur-web2 -p 81:80 -d httpd
L’option -p indique que le port 80 du conteneur est renvoyé sur le port 81
de la machine hôte.
Plusieurs environnements graphiques existent pour interagir avec Docker.
Le tableau de bord
(dashboard) est l’interface « officielle » fournie avec l’outil Docker desktop,
mais vous pouvez en tester d’autre si vous le souhaitez.
En voici deux qui semblent intéressants.
En cliquant sur le nom de l’un des conteneurs disponibles, on dispose de toutes les options
associées.
Un paramètre important est le renvoi du port de l’image instanciée dans le conteneur
vers un port de la machine Docker. Ce renvoi permet
d’accéder avec une application de la machine-hôte à l’instance de l’image comme
si elle s’exécutait directement dans la machine Docker. Reportez-vous à
la section précédente pour des explications complémentaires sur l’option --publish.
Une fois que l’on a installé des services dans des conteneurs, il faut
disposer de programmes clients pour pouvoir dialoguer avec eux. Ces programmes
clients sont en général à installer directement sur la machine hôte.
Dans le cas d’un serveur web, ou en général de tout service qui communique
selon le protocole HTTP, un navigateur web fait parfaitement l’affaire.
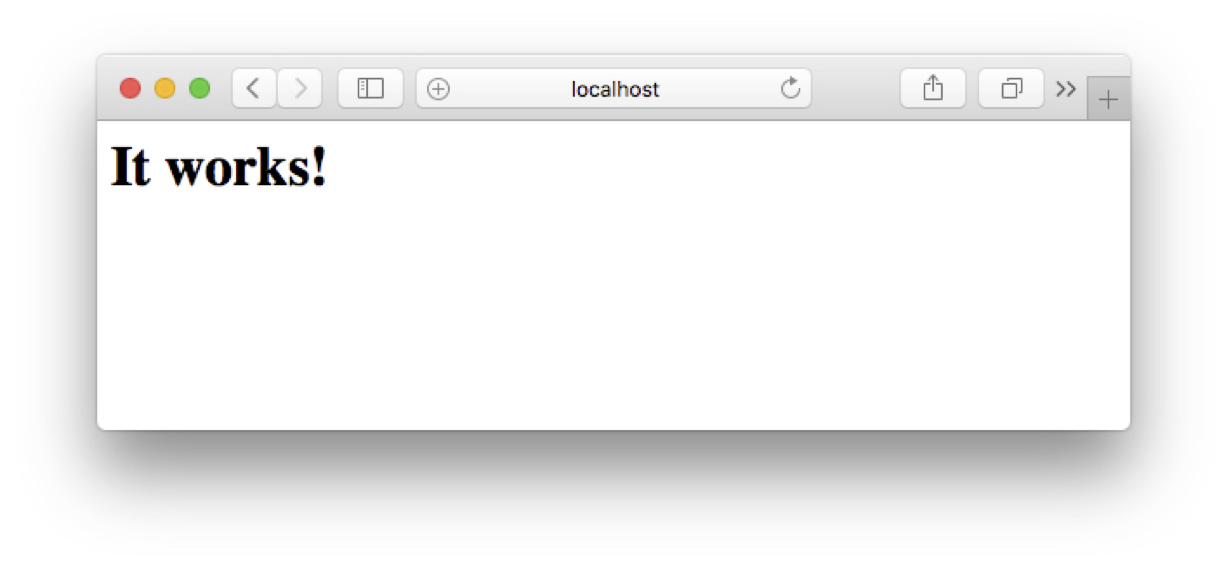
Avec votre navigateur préféré, essayer d’accéder aux adresses http://localhost:80
et http://localhost:81: les services web Docker que vous venez d’installer
devraient répondre par un message basique mais réconfortant.
Fig. 8 Accès au service avec le nom du serveur et le port¶
Ouf! Prenez le temps de bien comprendre, car une fois ces mécanismes assimilés,
nous serons libérés de tout souci pour créer nos systèmes distribués et
les expérimenter par la suite. Et je vous rassure: l’ensemble est
géré de manière plus conviviale avec le dashboard (ce qui ne dispense pas de comprendre
ce qui se passe).
Dans la suite de ce cours, nous seront amenés à expérimenter quelques systèmes
NoSQL. J’en ai sélectionné un petit nombre, sur des critères de popularité,
de représentativité des techniques étudiés, de variété. Tout ont en commun
de s’installer facilement avec Docker et de disposer d’une interface cliente
gratuite et raisonnablement simple.
Dans ce qui suit nous installons successivement CouchDB, MongoDB, Cassandra
et ElasticSearch avec Docker. Pour chaque système nous installons également
une application cliente, et nous chargeons un (petit) jeu de données que
je fournis sur le site https://deptfod.cnam.fr/bd/tp/datasets/. Vous êtes
invités à effectuer ces installations sur votre machine, de manière
à être prêts aux expérimentations qui suivront.
CouchDB est un système NoSQL qui gère des collections de documents JSON.
Vous pouvez installer CouchDB sur votre machine avec Docker, en exposant
le port 5984 sur
la machine hôte. Voici la commande d’installation.
Dans ce qui suit, on suppose que le serveur est accessible
à l’adresse http://localhost:5984.
CouchDB
est essentiellement un serveur Web étendu à la gestion de documents JSON. Comme tout
serveur Web, il parle le HTTP, et on peut donc y accéder avec un navigateur
qui fait office de client! Pour des interactions HTTP plus complexes, nous
utilliserons également l’utilitaire cURL en ligne de commande.
S’il n’est pas déjà installé dans votre environnement (toutes plateformes), il est fortement conseillé
de le faire dès maintenant: le site de référence est http://curl.haxx.se/.
Une première requête HTTP
permet de vérifier la disponibilité de ce serveur. Entrez l’adresse suivante
dans le navigateur: http://admin:admin@localhost:5984. Vous devriez obtenir
un document similaire au suivant:
Vous noterez qu’il faut indiquer dans l’URL le compte
d’accès (admin/admin) juste avant le nom du serveur.
Un serveur CouchDB gère un ensemble de bases de données. Créer une nouvelle base se traduit,
par la création d’une nouvelle ressource avec une requête HTTP PUT).
Voici donc la commande
avec cURL pour créer une base films.
curl -X PUT http://admin:admin@localhost:5984/films
{"ok":true}
Maintenant que la base est créée, et on peut obtenir sa représentation
avec une requête GET (navigateur ou cURL).
curl -X GET http://admin:admin@localhost:5984/films
Cette requête renvoie un document JSON décrivant la nouvelle base.
Pour finir, nous allons insérer dans notre base CouchDB un ensemble
de documents JSON représentant des films. Récupérez sur le site
http://deptfod.cnam.fr/bd/tp/datasets/ le fichier films_couchdb.json
au format spécifique d’insertion CouchDB. Il a la forme suivante
(nous reparlerons de JSON bientôt):
curl -X POST http://admin:admin@localhost:5984/films/_bulk_docs \
-d @films_couchdb.json -H "Content-Type: application/json"
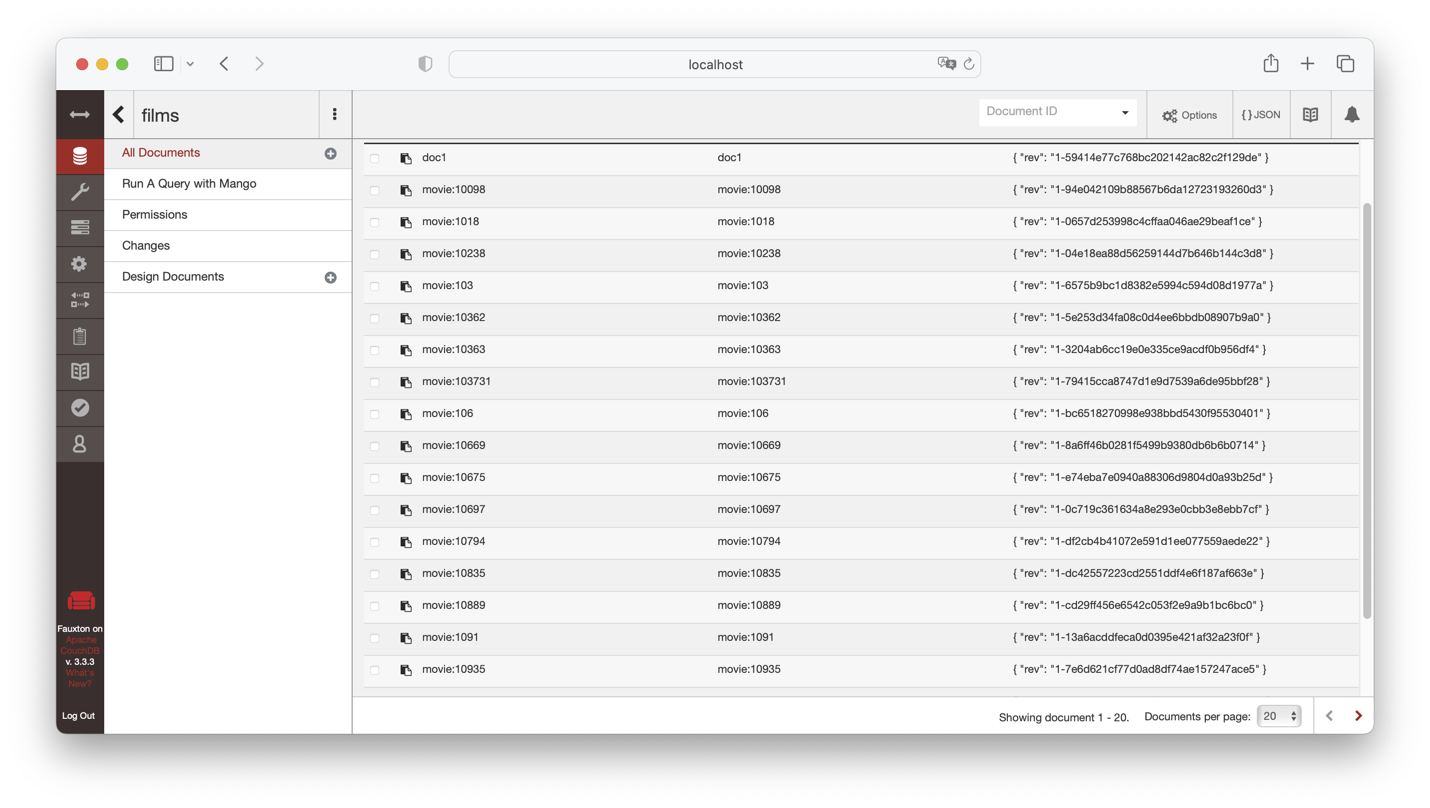
CouchDB fournit également une interface graphique intégrée
disponible à l’URL relative _utils (donc à l’adresse
complète http://localhost:5984/_utils dans notre cas). La
Fig. 9 montre l’aspect de cette interface graphique, très pratique,
avec la base que nous venons de créer.
Fig. 9 L’interface graphique (Fauxton) de CouchDB¶
Cassandra est un système de gestion de données à grande échelle conçu à l’origine (2007) par les ingénieurs de Facebook
pour répondre à des problématiques liées au stockage
et à l’utilisation de gros volumes de données. La communauté s’est
tellement investie dans le projet Cassandra que, au final, ce dernier a complètement divergé
de sa version originale. Facebook s’est alors résolu à accepter que le projet - en l’état -
ne correspondait plus précisément à leurs besoins, et que reprendre le développement à leur compte
ne rimerait à rien tant l’architecture avait évolué. Cassandra est donc resté porté par l’Apache Incubator.
Aujourd’hui, c’est la société Datastax qui assure la distribution et le support de Cassandra
qui reste un projet Open Source de la fondation Apache.
L’installation d’un conteneur Cassandra avec Docker se fait avec la commande suivante:
docker run --name mon-cassandra -p 3000:9042 -d cassandra:latest
On communique avec Cassandra via un langage, CQL, dont les
commandes doivent être transmises au port 9042 du conteneur. Dans l’instruction
ci-dessus, ce port est renvoyé sur le
port 3000 du système hôte avec l’option -p.
Il vous faut un client sur la machine hôte.
Des clients graphiques existent. Datastax propose des outils, dont
le Datastax Studio qui est assez agréable à utiliser mais dont
l’installation est lourde. Un « petit » utilitare graphique
assez complet DbVisualizer, disponible en version
gratuite à l’adresse https://www.dbvis.com/. Il permet classiquement
de créer des connexions, d’inspecter un schéma et de transmettre des
requêtes.
DbVisualizer peut être utilisé avec beaucoup de bases de données. Selon le système choisi,
il faut télécharger des connecteurs spécifiques (drivers). Cela se fait
de manière assez intuitive via DbVis lui-même. Dans le cas de Cassandra,
il faut prendre le driverCassandraDataStax.
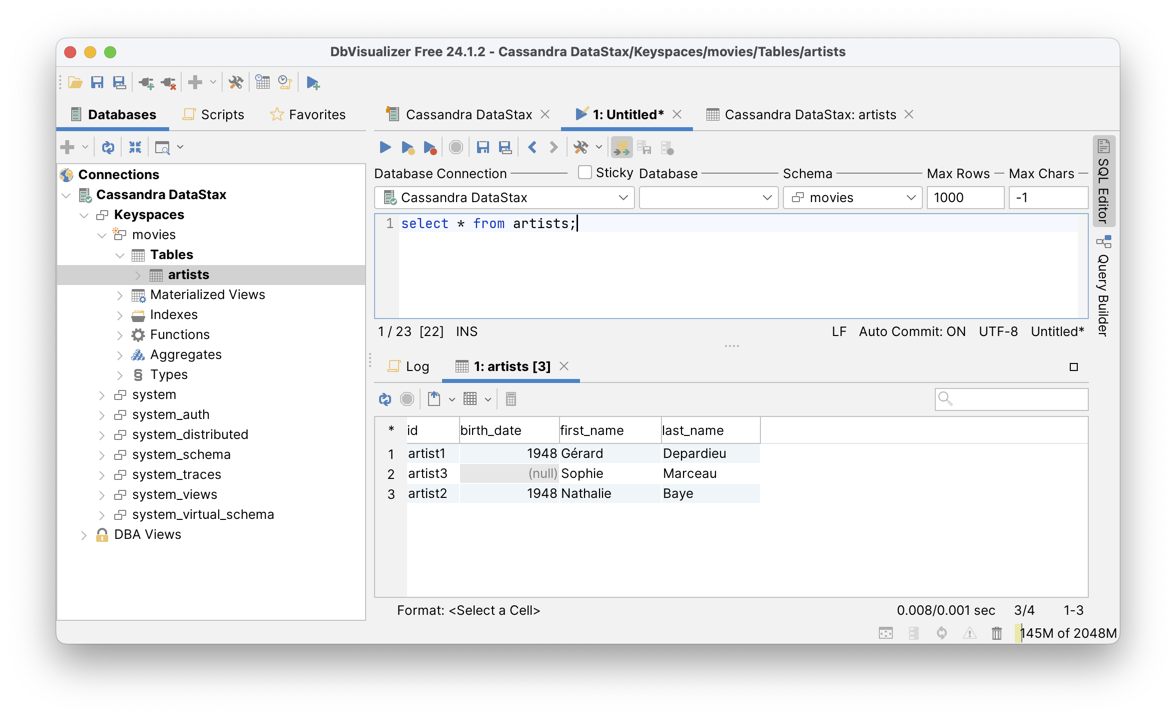
Fig. 10 Le client DbVisualizer accédant à Cassandra¶
La Fig. 10 montre l’interface, après création d’un keyspace,
de tables et de données. Le keyspace est le nom que Cassandra donne à une base de données.
Sous DbVisualizer, les keyspaces apparaissent à gauche de la
fenêtre principale (voir figure Fig. 10). Un clic bouton droit
permet d’ouvrir un formulaire de création d’un keyspace.
Note
Cassandra est fait pour fonctionner dans un environnement distribué. Pour créer
un keyspace, il faut donc préciser la stratégie de réplication à adopter. Nous verrons plus en détail
après comment tout ceci fonctionne.
Cassandra est assez proche en apparence d’un système relationnel, avec
création de tables, et insertion dans ces tables.
Cassandra va au-delà de la norme relationnelle en permettant des données
dénormalisées dans lesquelles certaines valeurs sont complexes (dictionnaires,
ensembles, etc.).
Il nous faut au préalable définir le typeartist de la manière suivante:
On crée alors une table utilisant ce type: le metteur en scène est une
instance du type artist, les acteurs un ensemble d’instance. Cela
donne le schéma suivant
Je vous laisse effectuer l’insertion de l’ensemble des films tels qu’ils sont fournis par
le site http://deptfod.cnam.fr/bd/tp/datasets/cassandra, avec tous les acteurs d’un film.
Il suffit de récupérer le fichier contenant l’ensemble des commandes d’insertion
et de l’exécuter comme un script dans DbVisualizer. Nous
nous en servirons pour l’interrogation CQL ensuite.
ElasticSearch est un moteur de recherche disponible sous licence libre
(Apache). Il repose sur Lucene (nous verrons plus bas ce que cela signifie).
Il a été développé à partir de 2004 et est aujourd’hui adossé à une
entreprise, Elastic.co.
Commençons par l’installation avec Docker. Voici une commande qui devrait fonctionner
sous tous les systèmes et mettre ElasticSearch en attente sur le port 9200.
docker run -d --name es1 -p 9200:9200 elasticsearch:8.13.0
Les versions d’ElasticSearch
ElasticSearch évolue rapidement. Pour éviter que les instructions qui suivent
ne deviennent rapidement obsolètes, j’indique le numéro de version dans
l’installation avec Docker (la 8.13.0, de mars 2024).
Quelques commandes supplémentaires sont nécesssaires. Un compte elastic
est créé, on lui attribue un mot de passe avec la commande suivante:
Toutes les interactions avec un serveur ElasticSearch passent par une interface
HTTP basée sur JSON. Vous
pouvez directement vous adresser au serveur HTTP en écoute
sur https://localhost:9200. Avec curl vous pouvez donc faire:
Vous devriez obtenir un document JSON semblable à
celui-ci:
{"name":"7a46670f6a9e","cluster_name":"docker-cluster","cluster_uuid":"89U3LpNhTh6Vr9UUOTZAjw","version":{"number":"8.13.0","...":"...","lucene_version":"9.1.1",},"tagline":"You Know, for Search"}
Pour une inspection confortable du serveur et des index ElasticSearch, nous
vous conseillons d’utiliser une interface d’administration: ElasticVue,
disponible sous toutes les plateformes.
Elle peut être téléchargée ici: https://elasticvue.com/.
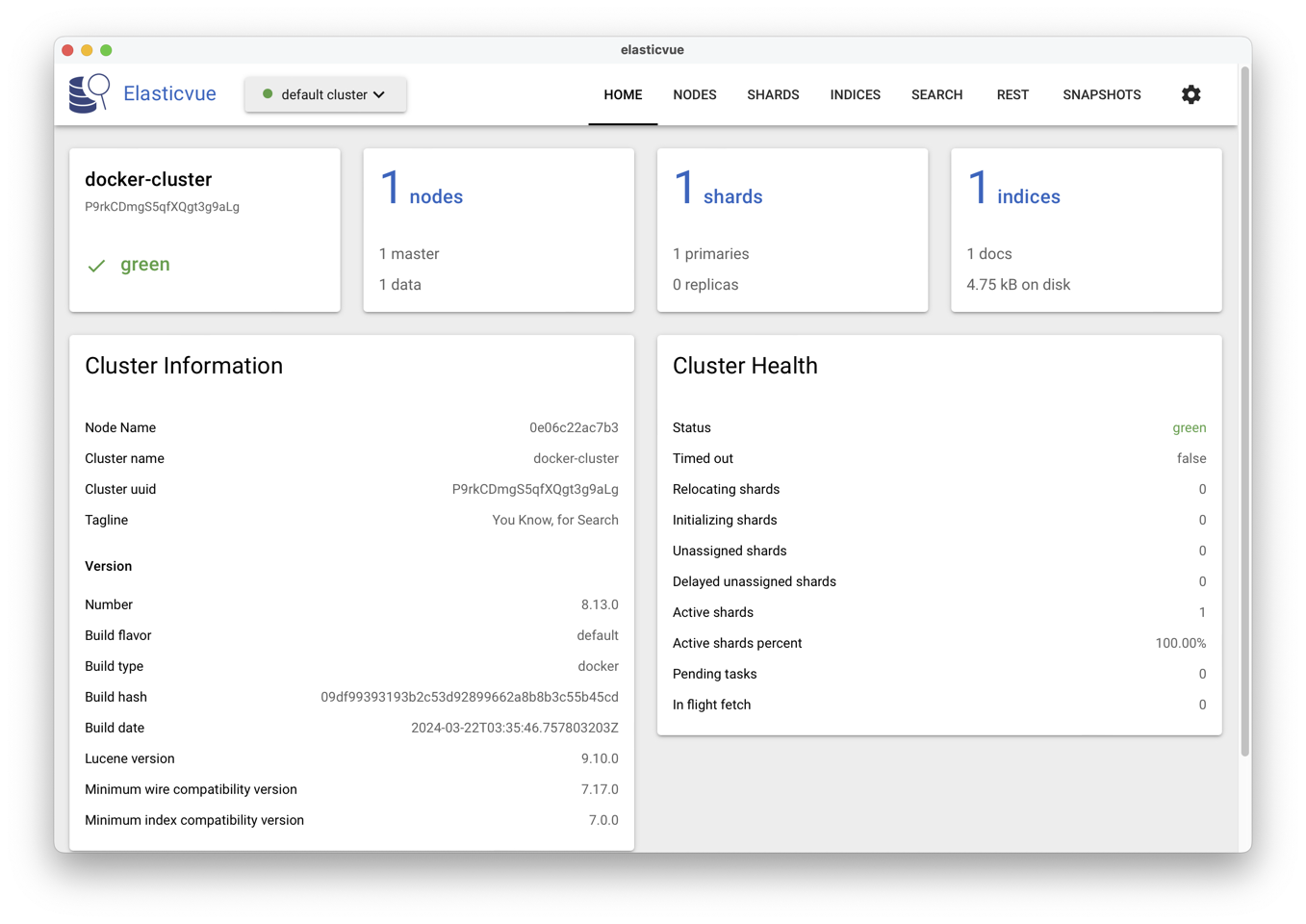
En lançant l’application, on peut se connecter au serveur https://localhost:9200
et on obtient l’interface de la figure Fig. 11.
La barre supérieure de l’interface propose des options REST
et SEARCH qui vont nous intéresser dans un premier temps.
Fig. 11 Le tableau de bord proposé par ElasticVue.¶
On ne parle pas de base de données dans ElasticSearch mais d’index.
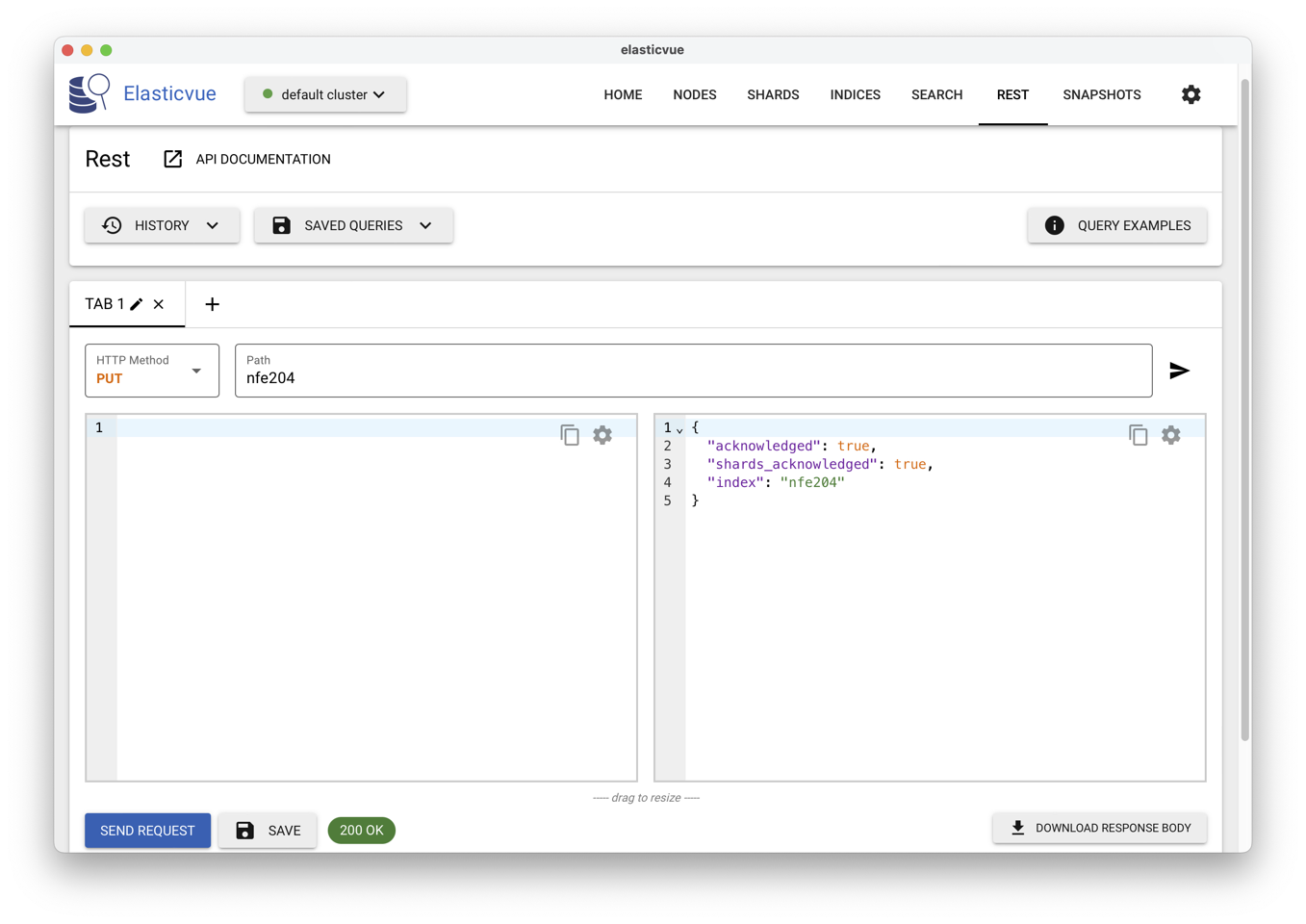
Pour créer un index nfe204-1 on envoie un PUT à l’adresse
https://localhost:9200/nfe204-1.
C’est facile avec la fenêtre REST d’ElasticVue: voir
Fig. 12.
Fig. 12 Utilisation d’ElasticVue pour transmettre des commandes REST¶
Le PUT crée un index à l’URL indiquée. Pour créer notre base de données,
nous allons utiliser une autre interface
d’Elasticsearch, appelée bulk (en grosses quantités), qui permet comme son
nom l’indique d’indexer de nombreux documents en une seule commande.
Récupérez notre collection de films, au format JSON adapté à l’insertion en masse
dans ElasticSearch, sur le site http://deptfod.cnam.fr/bd/tp/datasets/. Le fichier
se nomme films_esearch.json.
Vous pouvez l’ouvrir pour voir le format. Chaque document
« film » (sur une seule ligne) est précédé d’un petit document JSON qui précise l’index (movies),
et l’identifiant (1).
{"index":{"_index":"nfe204","_id":"movie"}}
On trouve ensuite les documents JSON proprement dits. Attention il ne doit pas y avoir de retour à la
ligne dans le codage JSON, ce qui est le cas dans le document que nous fournissons.
Ensuite, importez les documents dans Elasticsearch en le transmettant par
un POST à l’URL https://localhost:9200/_bulk/
Avec les paramètres spécifiés dans le fichier films_esearch.json, vous
devriez retrouver un index nfe204 maintenant présent dans l’interface, contenant
les données sur les films.
Installons maintenant MongoDB, un des systèmes NoSQL les plus populaires.
L’installation Docker se fait avec la commande suivante et instancie un conteneur
accessible à localhost:30001.
docker run --name mon-mongo -p 30001:27017 -d mongo
MongoDB fonctionne en mode classique client/serveur.
Le serveur mongod est en attente sur le port 27017 dans son conteneur, et
peut être redirigé vers un port de la machine Docker, comme le port 30001
dans la commande précédente.
En ce qui concerne les applications clientes, nous avons en gros deux possibilités:
l’interpréteur de commande mongo (qui suppose d’avoir installé MongoDB sur la machine hôte)
ou une application graphique plus agréable à utiliser.
Parmi ces dernières, Studio3T (http://studio3.com) me semble le meilleur
client graphique du moment; il existe une version gratuite, pour des utilisations non commerciales, qui ne vous expose
qu’à quelques courriels de relance de la part des auteurs du système (vous pouvez en profiter
pour les remercier gentiment).
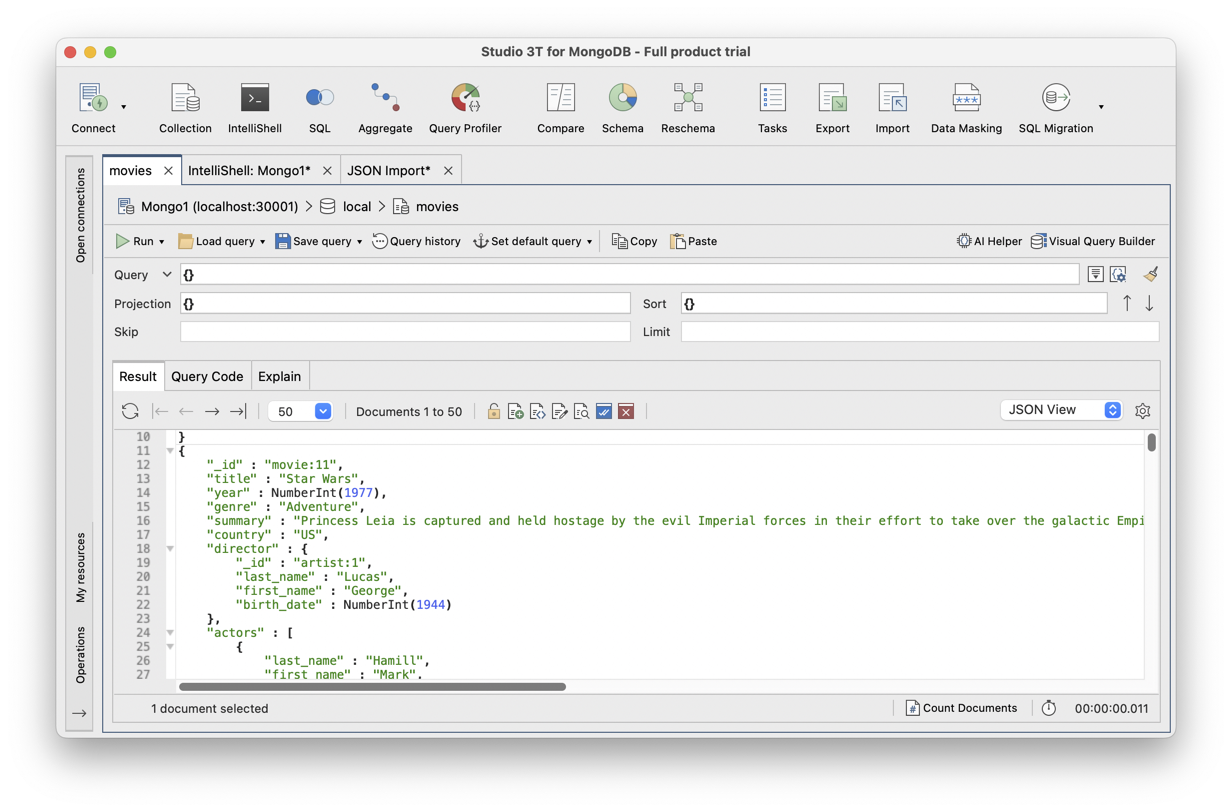
Studio3T propose
un interpréteur de commande intelligent (autocomplétion, exécution de scripts placés
dans des fichiers), des fonctionnalités d’import et d’export. La Fig. 13 montre l’interface en action.
Créons maintenant notre base des films, constituée de documents JSON ayant
la forme suivante:
{"_id":"movie:100","title":"The Social network","summary":"On a fall night in 2003, Harvard undergrad and programming genius Mark Zuckerberg sits down at his computer and heatedly begins working on a new idea. (...)","year":2010,"director":{"last_name":"Fincher","first_name":"David"},"actors":[{"first_name":"Jesse","last_name":"Eisenberg"},{"first_name":"Rooney","last_name":"Mara"}]}
Comme il serait fastidieux de les insérer un par un, nous allons utiliser Studio3T.
Un fichier conforme au format attendu est disponible
parmi les jeux de données de http://deptfod.cnam.fr/bd/tp/datasets/.
Vous pouvez le télécharger et l’utiliser
pour insérer directement les films dans la base avec l’utilitaire d’import de Studio3T.
Dans ces exercices vous devez mettre en action les principes de Docker vus ci-dessus, et vous
êtes également invités à découvrir l’outil dockercompose qui nous permet de configurer
une fois pour toutes un environnement distribué constitué de plusieurs serveurs.
Qu’est-ce qu’une machine Docker, où se trouve-t-elle, quel est son rôle?
À quoi sert le terminal Docker, et qu’est-ce qui caractérise un tel terminal?
Qu’est-ce que la machine hôte? Doit-elle forcément tourner sous Linux?
Une instance d’image est-elle placée dans un conteneur, dans la machine hôte ou
dans la machine Docker?
Peut-on instancier une image dans plusieurs conteneurs?
Si vous ne savez pas répondre, cela vaut la peine de relire ce qui précède, ou des ressources
complémentaires sur le Web. Vous serez plus à l’aise par la suite si vous avez une
idée claire de l’architecture et de ses concepts-clé.
Maintenant, effectuez les opérations ci-dessus sur votre machine. Installez Docker,
lancez le conteneur hello-world, affichez la liste des conteneurs, supprimez
le conteneur hello-world.
Après installation de Docker, créez un conteneur avec la dernière version de MySQL. Vous pouvez
utiliser la ligne de commande ou le dashboard.
Installez également un client MySQL sur votre machine (par exemple le
MySQL Workbench accessible à https://www.mysql.com/products/workbench/)
et connectez-vous à votre conteneur Docker.
Au lieu de lancer toujours la même ligne de commande, on peut créer un fichier de configuration
(dans un format qui s’appelle YAML) et l’exécuter avec l’utilitaire docker-compose. Voici un
exemple de base: sauvegardez-le dans un fichier mysql-compose.yml.
Vous pouvez alors lancer la création de votre conteneur avec la commande:
docker compose -f mysql-compose.yml up
Voici quelques exercices à faire:
Testez que vous pouvez bien accéder à votre conteneur avec le client MySQL (quel est le port d’accès
défini dans la configuration Yaml?)
Configurez votre conteneur MySQL pour définir un compte d’accès root avec un mot
de passe et donnez à la base le nom nfe204 (aide: lisez
la documentation associée au conteneur MySQL, laquelle
se trouve ici: https://hub.docker.com/_/mysql)
Configurez un ensemble de trois conteneurs MySQL. Vérifiez que vous pouvez vous connecter à chacun.
Arrêtez/redémarrez le conteneur (cherchez la commande docker-compose), enfin supprimez-le.
Même exercice, mais cette fois avec MongoDB, un système NoSQL très utilisé.
Les principes sont les mêmes: vous récupérez une image de MongoDB après voir
fouillé sur http://hub.docker.com, vous l’instanciez,
vous configurez le port d’accès, et vous testez l’accès avec un client à partir
de la machine-hôte.
Pour MongoDB, voici les deux principaux clients disponibles gratuitement: