Recherche exacte¶
Dans ce chapitre nous étudions quelques méthodes de recherche exacte, au sens de « recherche dont le contenu est défini de manière complète et univoque par la requête ». Cette notion de recherche exacte s’oppose à celle de recherche approchée que nous étudierons plus tard.
Etant donnée une recherche exacte q1 et un document d, on peut dire si d appartient ou non au résultat de q1. À l’inverse, si q2 est une recherche approchée, l’appartenance de d au résultat est plus ou moins forte. Conséquence,: tous les documents dans le résultat d’une recherche exacte sont aussi pertinents les uns que les autres, alors que pour une recherche exacte, on doit les classer par ordre de pertinence.
Nous commençons par la recherche basée sur les protocoles du Web. Ce dernier n’est pas vraiment une base de données mais c’est un système distribué de documents, et un cas-type de Big Data s’il en est. De plus, il s’agit d’une source d’information essentielle pour collecter des données, les agréger et les analyser.
Le Web s’appuie sur des protocoles bien connus (HTTP) qui ont été repris pour la définition de services (Web) dits REST. Nous utiliserons CouchDB pour illustrer l’organisation et la manipulation de documents basées sur REST.
Nous continuons ensuite notre exploration avec MongoDB et ElasticSearch. Le cas de Cassandra est étudié dans un chapitre à part, pour montrer comment la modélisation peut être influencée par les capacités du langage d’interrogation.
S1: HTTP, REST, et CouchDB¶
Supports complémentaires
Le Web est la plus grande base de documents ayant jamais existé! Même s’il est essentiellement constitué de documents très peu structurés et donc difficilement exploitables par une application informatique, les méthodes utilisées sont très instructives et se retrouvent dans des systèmes plus organisés. Dans cette section, l’accent est mis sur le protocole REST que nous retrouverons très fréquemment en étudiant les systèmes NoSQL. Les systèmes CouchDB et ElasticSearch qui s’appuient sur REST.
Web = ressources + URL + HTTP¶
Rappelons les principales caractéristiques du Web, vu comme un gigantesque système d’information orienté documents. Distinguons d’abord l’Internet, réseau connectant des machines, et le Web qui constitue une collection distribuée de ressources hébergés sur ces machines.
Le Web est (techniquement) essentiellement caractérisé par trois choses: la notion de ressource, l’adressage par des URL et le protocole HTTP.
Ressources¶
La notion de ressource est assez générale/générique. Elle désigne toute entité disposant d’une adresse sur le réseau, et fournissant des services. Un document est une forme de ressource: le service est dans ce cas le contenu du document lui-même. D’autres ressources fournissent des services au sens plus calculatoire du terme en effectuant sur demande des opérations produisant la représentation du résultat sous forme de ressource.
Il faut essentiellement voir une ressource comme un point adressable sur l’Internet avec lequel on peut échanger des messages. L’adressage se fait par une URL, l’échange par HTTP.
URLs¶
L’adresse d’une ressource est une URL, pour Universal Resource Location. C’est une chaîne de caractères qui encode toute l’information nécessaire pour trouver la ressource et lui envoyer des messages.
Note
Certaines ressources n’ont pas d’adresse sur le réseau, mais sont quand même identifiables de manière pérenne et unique par des URI (Universal Resource identifier).
Cet encodage prend la forme d’une chaîne de caractères formée selon des règles précises illustrées par l’URL fictive suivante:
https://www.example.com:443/chemin/vers/doc?nom=b3d&type=json#fragment
Ici, https est le protocole qui indique la méthode d’accès à la ressource.
Le seul protocole que nous verrons est HTTP (le s indique une variante
de HTTP comprenant un encryptage des échanges). L’hôte (hostname)
est www.example.com. Un des services du Web (le DNS) va convertir ce nom
d’hôte en adresse IP, ce qui permettra d’identifier la machine serveur qui
héberge la ressource.
Note
Quand on développe une application, on la teste
souvent localement en utilisant sa propre machine de développement
comme serveur. Le nom de l’hôte est alors localhost, qui
correspond à l’IP 127.0.0.1.
La machine serveur communique avec le réseau sur un ensemble de ports, chacun correspondant à l’un des services gérés par le serveur. Pour le service HTTP, le port est par défaut 80, mais on peut le préciser, comme sur l’exemple précédent, où il vaut 443. On trouve ensuite le chemin d’accès à la ressource, qui suit la syntaxe d’un chemin d’accès à un fichier dans un système de fichiers. Dans les sites simples, « statiques », ce chemin correspond de fait à un emplacement physique vers le fichier contenant la ressource. Dans des applications plus sophistiquées, les chemins sont virtuels et conçus pour refléter l’organisation logique des ressources offertes par l’application.
Après le point d’interrogation, on trouve la liste des paramètres (query string) éventuellement transmis à la ressource. Enfin, le fragment désigne une sous-partie du contenu de la ressource. Ces éléments sont optionnels.
Le protocole HTTP¶
HTTP, pour HyperText Transfer Protocol, est un protocole extrêmement simple, basé sur TCP/IP, initialement conçu pour échanger des documents hypertextes. HTTP définit le format des requêtes et des réponses. Voici par exemple une requête envoyée à un serveur Web:
GET /myResource HTTP/1.1
Host: www.example.com
Elle demande une ressource nommée myResource au serveur www.example.com.
Voici une possible réponse à cette requête:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
<html>
<head><title>myResource</title></head>
<body><p>Bonjour à tous!</p></body>
</html>
Un message HTTP est constitué de deux parties: l’entête et le corps, séparées par une ligne blanche. La réponse montre que l’entête contient des informations qualifiant le message. La première ligne par exemple indique qu’il s’agit d’un message codé selon la norme 1.1 de HTTP, et que le serveur a pu correctement répondre à la requête (code de retour 200). La seconde ligne de l’entête indique que le corps du message est un document HTML encodé en UTF-8.
Le programme client qui reçoit cette réponse traite le corps du message en fonction des informations contenues dans l’entête. Si le code HTTP est 200 par exemple, il procède à l’affichage. Un code 404 indique une ressource manquante, une code 500 indique une erreur sévère au niveau du serveur. Voir http://en.wikipedia.org/wiki/List_of_HTTP_status_codes pour une liste complète.
Le Web est initialement conçu comme un système d’échange de documents hypertextes se référençant les uns les autres, codés avec le langage HTML (ou XHTML dans le meilleur des cas). Ces documents s’affichent dans des navigateurs et sont donc conçus pour des utilisateurs humains. En revanche, ils sont très difficiles à traiter par des applications en raison de leur manque de structure et de l’abondance d’instructions relatives à l’affichage et pas à la description du contenu. Examinez une page HTML provenant de n’importe quel site un peu soigné et vous verrez que la part du contenu est négligeable par rapport à tous les CSS, javascript, images et instructions de mise en forme.
Une évolution importante du Web a donc consisté à étendre la notion de ressource à des services recevant et émettant des documents structurés transmis dans le corps du message HTTP. Vous connaissez déjà les formats utilisés pour représenter cette structure: JSON et XML, ce dernier étant clairement de moins en moins apprécié.
C’est cet aspect sur lequel nous allons nous concentrer: le Web des services est véritablement une forme de très grande base de documents structurés, présentant quelques fonctionnalités (rudimentaires) de gestion de données comparable aux opérations d’un SGBD classique. Les services basés sur l’architecture REST, présentée ci-dessous, sont la forme la plus courante rencontrée dans ce contexte.
L’architecture REST¶
REST est une forme de service Web dont le parti pris est de s’appuyer sur HTTP, ses opérations, la notion de ressource et l’adressage par URL. REST est donc très proche du Web, la principale distinction étant que REST est orienté vers l’appel à des services à base d’échanges par documents structurés, et se prête donc à des échanges de données entre applications. La Fig. 18 donne une vision des éléments essentiels d’une architecture REST.
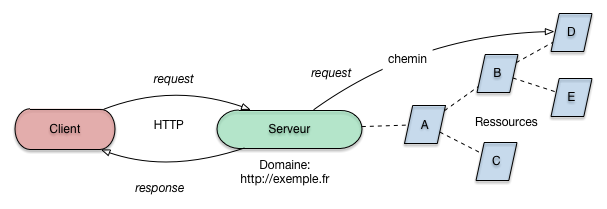
Fig. 18 Architecture REST: client, serveur, ressources, URL (domaine + chemin)¶
Avec HTTP, il est possible d’envoyer quatre principaux types de messages, ou méthodes, à une ressource web:
GETest une lecture de la ressource (ou plus précisément de sa représentation publique);
PUTest la création d’une ressource;
POSTest l’envoi d’un message à une ressource existante;
DELETEla destruction d’une ressource.
REST s’appuie sur un usage strict (le plus possible) de ces quatre méthodes. Ceux qui
ont déjà pratiqué la programmation Web admettront par exemple
qu’un développeur ne se pose pas toujours
nettement la question, en créant un formulaire, de la méthode GET ou POST à employer.
De plus le PUT (qui n’est pas connu des formulaires Web) est ignoré et le DELETE jamais utilisé.
La définition d’un service REST se doit d’être plus rigoureuse.
le
GET, en tant que lecture, ne doit jamais modifier l’état de la ressource (pas « d’effet de bord »); autrement dit, en l’absence d’autres opérations, des messagesGETenvoyés répétitivement à une même ressource ramèneront toujours le même document, et n’auront aucun effet sur l’environnement de la ressource ;le
PUTest une création, et l’URL a laquelle un messagePUTest transmis ne doit pas exister au préalable; dans une interprétation un peu plus souple, lePUTcrée ou remplace la ressource éventuellement existante par la nouvelle ressource transmise par le message;inversement,
POSTdoit s’adresser à une ressource existante associée à l’URL désignée par le message; cette méthode correspond à l’envoi d’un message à la ressource (vue comme un service) pour exécuter une action, avec potentiellement un changement d’état (par exemple la création d’une nouvelle ressource).
Les messages sont transmis en HTTP (voir ci-dessus) ce qui offre, entre autres avantages, de ne pas avoir à redéfinir un nouveau protocole. Le contenu du message est une information codée en XML ou en JSON (le plus souvent), soit ce que nous avons appelé jusqu’à présent un document.
quand le client émet une requête REST, le document contient les paramètres d’accès au service (par exemple les valeurs de la ressource à créer, ou bien le code de la requête à effectuer);
quand la ressource répond au client, le document contient l’information constituant le résultat du service; en cas d’erreur ou d’anomalie (droit d’accès insuffisant par exemple) un code d’erreur HTTP peut être utilisé.
Important
En toute rigueur, il faut bien distinguer la ressource et le document qui représente une information produite par la ressource.
On peut faire appel à un service REST avec n’importe
quel client HTTP, et notamment avec votre navigateur préféré: copiez l’URL
dans la fenêtre de navigation et consultez le résultat. Le navigateur a cependant l’inconvénient,
avec cette méthode, de ne transmettre que des messages GET. Un outil plus général, s’utilisant
en ligne de commande, est cURL. S’il n’est pas déjà installé dans votre environnement, il est fortement conseillé
de le faire dès maintenant: le site de référence est http://curl.haxx.se/.
Voici quelques exemples d’utilisation de cURL pour parler le HTTP avec un service REST.
Notre base de films est obtenue par appel à l’API REST de themoviedb.org. Voici
la requête qui cherche le film tt10404944.
https://api.themoviedb.org/3/find/tt10404944?api_key=8f479aa1cb024ffe0d95da8c4ee56fe7&external_source=imdb_id
Ce qui retourne le document suivant.
{
"adult": false,
"backdrop_path": "/vkIJ2QgcKMJRvi6pBW4Tr2kgLdy.jpg",
"id": 637534,
"title": "The Stronghold",
"original_language": "fr",
"original_title": "BAC Nord",
"overview": "A police brigade works in the dangerous northern neighborhoods of Marseille, where the level of crime is higher than anywhere else in France.",
"poster_path": "/nLanxl7Xhfbd5s8FxPy8jWZw4rv.jpg",
"media_type": "movie",
"genre_ids": [53, 28, 80],
"popularity": 21.929,
"release_date": "2021-08-18",
"video": false,
"vote_average": 7.426,
"vote_count": 1147
}
Notez le placement de paramètres dans l’URL, et notamment une clé d’accès, souvent requise pour utiliser des services. Autre exemple, l’API REST de Open Weather Map, un service fournissant des informations météorologiques (créez une clé API et ajoutez-la à l’URL pour obtenir une réponse complète).
curl -X GET api.openweathermap.org/data/2.5/weather?q=Paris
Et on obtient la réponse suivante (qui varie en fonction de la météo, évidemment).
{
"coord":{
"lon":2.35,
"lat":48.85
},
"weather":[
{
"id":800,
"main":"Clear",
"description":"Sky is Clear",
"icon":"01d"
}
],
"base":"cmc stations",
"main":{
"temp":271.139,
"temp_min":271.139,
"temp_max":271.139,
"pressure":1021.17,
"sea_level":1034.14,
"grnd_level":1021.17,
"humidity":87
},
"name":"Paris"
}
Même chose, mais en demandant une réponse codée en XML. Notez l’option -v qui permet d’afficher le détail des échanges
de messages HTTP gérés par cURL.
curl -X GET -v api.openweathermap.org/data/2.5/weather?q=Paris&mode=xml
Nous verrons ultérieurement des exemples de PUT et de POST pour créer des ressources et leur envoyer des messages
avec cURL.
Note
La méthode GET est utilisée par défaut par cURL, on peut donc l’omettre.
Nous nous en tenons là pour les principes essentiels de REST, qu’il faudrait compléter de nombreux détails mais qui nous suffiront à comprendre les interfaces (ou API) REST que nous allons rencontrer.
Important
Les méthodes d’accès aux documents sont représentatives des opérations de
type dictionnaire: toutes les données ont une adresse,
on peut accéder à la donnée par son adresse (get), insérer une donnée à une adresse (put),
détruire la donnée à une adresse (delete). De nombreux systèmes
NoSQL se contentent de ces opérations qui peuvent s’implanter très simplement et efficacement.
Pour être concret et rentrer au plus vite dans le cœur du sujet, nous présentons l’API de CouchDB qui est conçu comme un serveur de documents (JSON) basé sur REST.
L’API REST de CouchDB¶
CouchDB est essentiellement un serveur Web étendu à la gestion de documents JSON. Comme tout serveur Web, il parle le HTTP et manipule des ressources (Fig. 19).
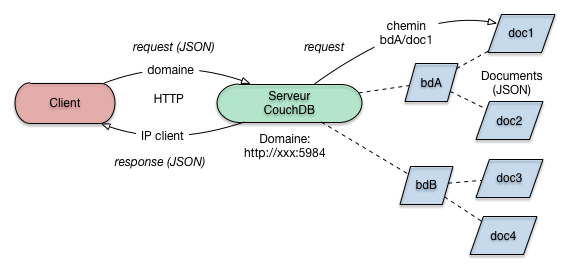
Fig. 19 Architecture (simplifiée) de CouchDB¶
Je vous revoie au chapitre Préliminaires: Docker pour l’installation de CouchDB, le chargement d’une base et l’interaction avec le serveur, soit via cUrl, soit via l’interface graphique disponible à http://admin:admin@localhost:5984/_utils
CouchDB adopte délibérément les principes et protocoles du Web. Une base de données et ses documents sont vus comme des ressources et on dialogue avec eux en HTTP, conformément au protocole REST.
Un serveur CouchDB gère un ensemble de bases de données. Créer une nouvelle base se traduit,
avec l’interface REST, par la création d’une nouvelle ressource. Voici donc la commande
avec cURL pour créer une base films (notez la méthode PUT pour créer une ressource).
curl -X PUT http://admin:admin@localhost:5984/films
{"ok":true}
Maintenant que la ressource est créée, et on peut obtenir sa représentation avec une requête GET.
curl -X GET http://admin:admin@localhost:5984/films
Cette requête renvoie un document JSON décrivant la nouvelle base.
{"update_seq":"0-g1AAAADfeJz6t",
"db_name":"films",
"sizes": {"file":17028,"external":0,"active":0},
"purge_seq":0,
"other":{"data_size":0},
"doc_del_count":0,
"doc_count":0,
"disk_size":17028,
"disk_format_version":6,
"compact_running":false,
"instance_start_time":"0"
}
Vous commencez sans doute à saisir la logique des interactions. Les entités gérées par le serveur (des bases de données, des documents, voire des fonctions) sont transposées sous forme de ressources Web auxquelles sont associées des URLs correspondant, autant que possible, à l’organisation logique de ces entités.
Pour insérer un nouveau document dans la base films, on
envoie donc un message PUT à l’URL qui va représenter le document. Cette URL
est de la forme http://localhost:5984/films/idDoc, où idDoc désigne l’identifiant
de la nouvelle ressource.
curl -X PUT http://admin:admin@localhost:5984/films/doc1 -d '{"key": "value"}'
{"ok":true,"id":"doc1","rev":"1-25eca"}
Que faire si on veut insérer des documents placés dans des fichiers?
Vous avez dû récupérer dans nos jeux de données des documents représentant
des films en JSON. Le
document film629.json par exemple représente le film Usual Suspects. Voici comment
on l’insère dans la base en lui attribuant l’identifiant us.
curl -X PUT http://admin:admin@localhost:5984/films/us -d @film629.json -H "Content-Type: application/json"
Cette commande cURL est un peu plus compliquée
car il faut créer un message HTTP
plus complexe que pour une simple lecture. On passe dans le corps du message HTTP le contenu
du fichier film629.json avec l’option -d et le préfixe @, et on indique que le
format du message est JSON
avec l’option -H. Voici la réponse de CouchDB.
{
"ok":true,
"id":"us",
"rev":"1-68d58b7e3904f702a75e0538d1c3015d"
}
Le nouveau document a un identifiant (celui que nous attribué par l’URL de la ressource) et un numéro de révision. L’identifiant doit être unique (pour une même base), et le numéro de révision indique le nombre de modifications apportées à la ressource depuis sa création.
Si vous essayez d’exécuter une seconde fois la création de la ressource, CouchDB proteste et renvoie un message d’erreur:
{
"error":"conflict",
"reason":"Document update conflict."
}
Un document existe déjà à cette URL.
Une autre façon d’insérer, intéressante pour illustrer les principes d’une API REST, et d’envoyer
non pas un PUT pour créer une nouvelle ressource (ce qui impose de choisir l’identifiant)
mais un POST à une ressource existante, ici la base de données, qui se charge alors de créer
la nouvelle ressource représentant le film, et de lui attribuer un identifiant.
Voici cette seconde option à l’œuvre pour créer un nouveau document en déléguant
la charge de la création à la ressource films.
curl -X POST http://admin:admin@localhost:5984/films -d @film629.json -H "Content-Type: application/json"
Voici la réponse de CouchDB:
{
"ok":true,
"id":"movie:629",
"rev":"1-68d58b7e3904f702a75e0538d1c3015d"
}
CouchDB a trouvé l’identifiant (conventionnellement nommé id) dans le document JSON et l’utilise.
Si aucun identifiant n’est trouvé,
une valeur arbitraire (une longue et obscure chaîne de caractère) est engendrée.
CouchDB est un système multi-versions: une nouvelle version du document est créée à chaque insertion.
Chaque document
est donc identifié par une paire (id, revision): notez l’attribut rev
dans le document ci-dessus. Dans certains cas, la version la plus récente est
implicitement concernée par une requête. C’est le cas quand on veut obtenir la ressource avec un simple GET.
curl -X GET http://admin:admin@localhost:5984/films/us
En revanche, pour supprimer un document, il faut indiquer explicitement quelle est la version à détruire en précisant le numéro de révision.
curl -X DELETE http://admin:admin@localhost:5984/films/us?rev=1-68d58b7e3904f702a75e0538d1c3015d
Nous en restons là pour l’instant. Cette courte session illustre assez bien
l’utilisation d’une API REST pour gérer
une collection de document à l’aide de quelques opérations basiques:
création, recherche, mise à jour, et destruction,
implantées par l’une des 4 méthodes HTTP. La notion de ressource, existante (et on lui envoie des messages avec
GET ou POST) ou à créer (avec un message PUT), associée à une URL correspondant à la logique de l’organisation
des données, est aussi à retenir.
Bien entendu il s’agit d’un langage très limité pour l’interrogation, puisqu’il n’offre que deux possibilités: accéder à un document si on connaît son identifiant, ou parcourir toute la collection. Nous verrons avec ElasticSearch une approche beaucoup plus puissante où REST est utilisé pour transmettre des requêtes dans un langage riche et complexe.
Quiz¶


Mise en pratique¶
Les propositions suivantes vous permettent de mettre en pratique les connaissances précédentes.
MEP MEP-S1-2: Documents et services Web
Soyons concret: vous construisez une application qui, pour une raison X ou Y, a besoin de données météo sur une région ou une ville donnée. Comment faire? la réponse est simple: trouver le service Web qui fournit ces données, et appeler ces services. Pour la première question, on peut par exemple prendrele site OpenweatherMap, dont les services sont décrits ici: http://openweathermap.org/api. Pour appeler ce service, comme vous pouvez le deviner, on passe par le protocole HTTP.
Application: utilisez les services de OpenWeatherMap pour récupérer les données météo pour Paris, Marseille, Lyon, ou toute ville de votre choix. Testez les formats JSON et XML.
MEP MEP-S1-3: comprendre les services géographiques de Google.
Google fournit (librement, jusqu’à une certaine limite) des services dits de géolocalisation: récupérer une carte, calculer un itinéraire, etc. Vous devriez être en mesure de comprendre les explications données ici: https://developers.google.com/maps/documentation/webservices/?hl=FR (regardez en particulier les instructions pour traiter les documents JSON et XML retournés).
Pour vérifier que vous avez bien compris: créez un formulaire HTML avec deux champs
dans lesquels on peut saisir les points de départ et d’arrivée d’un itinéraire (par exemple,
Paris - Lyon). Quand on valide ce formulaire, afficher le JSON ou XML (mieux, donner
le choix du format à l’utilisateur) retourné par le service Google (aide: il s’agit
du service directions).
MEP MEP-S1-4: explorer les services Web et l’Open data.
Le Web est une source immense de données structurées représentées en JSON ou en XML. Vous voulez connaître le programme d’une station de radio, accéder à une entre Wikipedia sous forme structurée, gérer des calendriers? On trouve à peu près tout sous forme de services.
Explorez ces API pour commencer à vous faire une idée du type de projet qui vous intéresse. Récupérez des données et regardez leur format.
Autre source de données: les données publiques. Allez voir par exemple sur
http ://data.enseignementsup-recherche.gouv.fr/
http://www.data.gov/ (Open data USA)
La société OpendatSoft (http://www.opendatasoft.fr) propose non seulement des jeux de données, mais de nombreux outils d’analyse et de visualisation.
Essayer d’imaginer une application qui combine plusieurs sources de données.
S2: ElasticSearch¶
Supports complémentaires
Dans cette section, nous allons passer au concret en introduisant les moteurs de recherche. Nous allons utiliser ici Elastic Search. Nous indexerons nos premiers documents, et commencerons à faire nos premières requêtes.
Nous allons nous appuyer entièrement sur les choix par défaut d’ElasticSearch pour nous concentrer sur son utilisation. La construction d’un moteur de recherche en production demande un peu plus de soin, nous en verrons au chapitre suivant les étapes nécessaires.
Architecture du système d’information avec un moteur de recherche¶
Un moteur de recherche comme ElasticSearch est une application spécialisée dans la recherche efficace appliquée à des collections de documents, ces collections étant en général stockée avec un autre système NoSQL. Pourquoi ne pas utiliser directement le moteur de recherche comme gestionnaire des documents ? La réponse est qu’un système comme ElasticSearch est entièrement consacré à la recherche (donc à la lecture) la plus efficace possible de documents. Il s’appuie pour cela sur des structures compactes, compressées, optimisées (les index inversés). En revanche, ce n’est pas nécessairement un très bon outil pour les autres fonctionnalités d’une base de données. Le stockage par exemple n’est ni aussi robuste ni aussi stable, et il faut parfois reconstruire l’index à partir de la base originale (on parlera de réindexer les documents).
Un système comme ElasticSearch n’est pas non plus très peformant pour des données souvent modifiées. Pour des raisons qui tiennent à la structure de ces index, les mises à jour sont coûteuses et s’effectuent difficilement en temps réel. La notion de mise à jour vaut ici aussi bien pour le contenu des documents (modification de la valeur d’un champ) que pour leur structure (ajout ou suppression d’un champ par exemple).
La pratique la plus courante consiste donc à utiliser un système de recherche comme un complément d’un serveur de base de données (relationnelle ou documentaire) et à lui confier les tâches de recherche que le serveur BD ne sait pas accomplir (soit, en gros, les recherches non structurées). Dans le cas des bases NoSQL, l’absence fréquente de tout langage de requête fait du moteur de recherche associé un outil indispensable.
Même en cas de présence d’un langage d’interrogation fourni par le système NoSQL, le moteur de recherche reste un candidat tout à fait valide pour satisfaire les recherches approchées avec classement des documents. En résumé, à part les deux inconvénients (reconstruction depuis une source extérieure, support faible des mises à jour), les moteurs de recherche sont des composants puissants aptes à satisfaire efficacement les besoins d’un système documentaire.
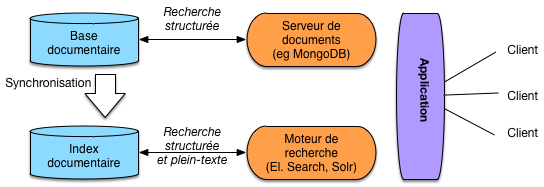
Fig. 20 Architecture d’une application avec moteur de recherche.¶
La Fig. 20 montre une architecture typique, en prenant pour exemple une base de données MongoDB (mais cela s’applique à tout autre SGBD). Les documents (applicatifs) sont donc dans la base qui fournit (pas toujours) des fonctionnalités de recherche structurées. On peut indexer la collection des documents applicatifs en extrayant des « champs » formant des documents (au sens d’ElasticSearch) fournis à l’index qui se charge de les organiser pour satisfaire efficacement des requêtes. L’application peut alors soit s’adresser au serveur MongoDB, soit au moteur de recherche.
Un scénario typique est celui d’une recherche par mot-clé dans un site, scénario que nous appelons recherche approchée et qui fait l’objet d’un prochain chapitre. En attendant voici une présentation limitée aux recherches exactes.
Interrogation¶
Une première méthode pour transmettre des recherches est de passer une expression en paramètre à l’URL à laquelle répond votre serveur ElasticSearch. La forme la plus simple d’expression est une liste de mots-clés. Voici quelques exemples d’URLs de recherche:
https://localhost:9200/nfe204/_search?q=alien
https://localhost:9200/nfe204/_search?q=alien,coppola
https://localhost:9200/nfe204/_search?q=alien,coppola,1994
Les dernières versions (à partir de la 8)
d’ElasticSearch ont introduit des mesures de sécurité qui compliquent
fortement l’accès direct au serveur en HTTPS. Mieux vaut donc utiliser
ElasticVue avec la fenêtre SEARCH qui se charge se constituer l’URL
de requête.
Une seconde méthode est de transmettre un document JSON décrivant la recherche. L’envoi
d’un document suppose que l’on utilise la méthode POST. Voici
par exemple un document avec une recherche sur trois mots-clé.
{
"query": {
"query_string" : {
"query" : "alien,coppola,1994"
}
}
}
La Fig. 21 montre l’exécution avec l’interface ElasticVue.
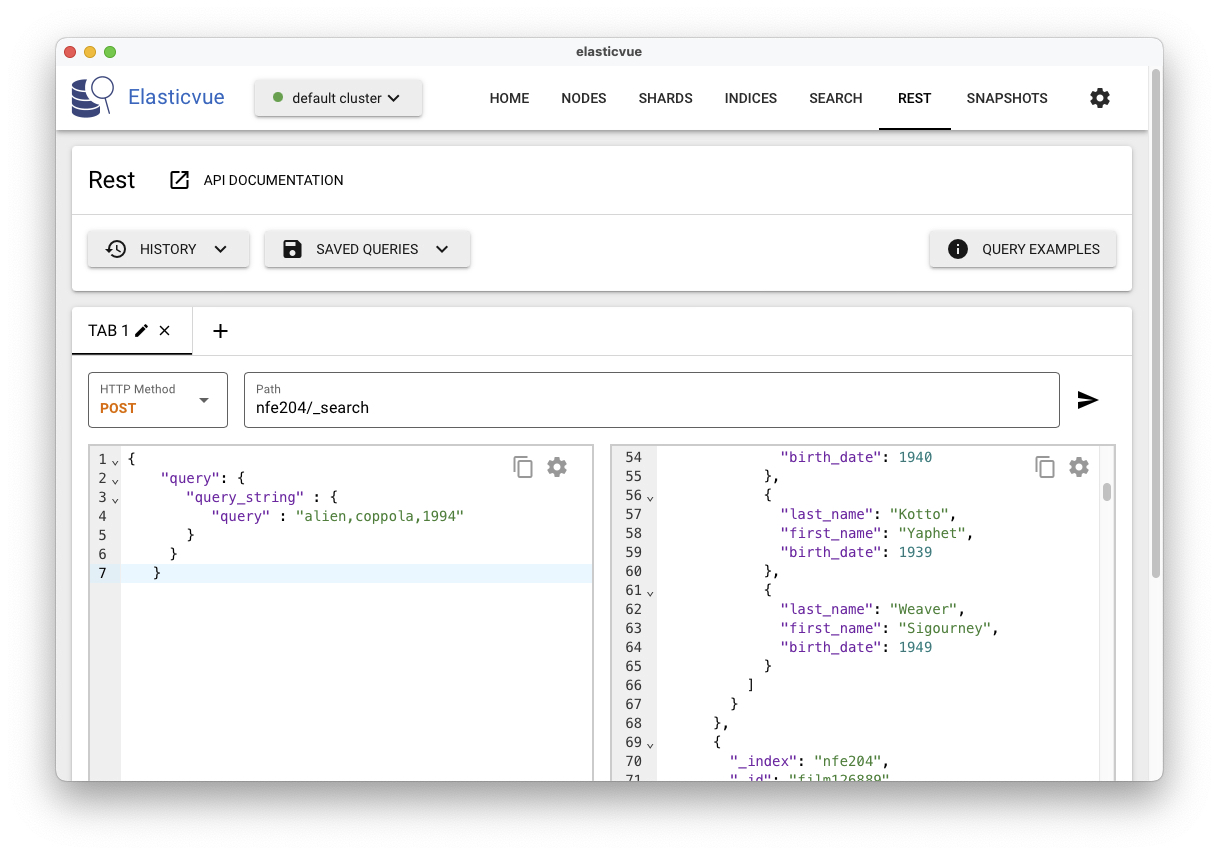
Fig. 21 L’interface ElasticVue avec recherches structurées¶
On voit clairement (mais partiellement) le résultat, produit sous la forme d’un
document JSON énumérant les documents trouvés dans un tableau hits. Notez
que le document indexé lui-même est présent, dans le champ _source,
correspondant à un comportement par défaut d’ElasticSearch: la totalité des documents
transmis à ElasticSearch y sont conservés sous leur forme « brute ». La
question de l’utilisation de deux systèmes qui semblent partiellement
redondants se pose. Nous revenons sur cette question plus loin.
Exprimer une recherche revient donc à envoyer à ElasticSearch
(utiliser la méthode POST) un document encodant la requête.
Le langage de recherche proposé par ElasticSearch, dit « DSL » pour Domain
Specific Language, est très riche. Pour vous donner juste un exemple,
voici comme on prend les 5 premiers documents d’une requête, en excluant la
source du résultat.
{
"from": 0,
"size": 5,
"_source": false,
"query": {
"query_string" : {
"query" : "matrix,2000,jamais"
}
}
}
Nous allons pour l’instant nous contenter d’une variante du language,
dite Query String, qui
correspond, essentiellement, au langage de base du système d’indexation
sous-jacent, Lucene (https://lucene.apache.org/). Toutes les
expressions données ci-dessous peuvent être entrées comme valeur du champ
query dans le document-recherche passé à l’interface REST.
Termes¶
La notion de base est celle de terme. Un terme est soit un mot, soit une séquence de mots (une phrase) placée entre apostrophes. La recherche:
Princess Leia
retourne tous les documents contenant soit « Princess », soit « Leia ». La recherche
"Princess Leia"
ramène les documents contenant les deux mots côte à côte (vous devez utiliser \ » pour intégrer un guillemet double dans une requête).
{
"query": {
"query_string" : {
"query" : "\"Princess Leia\""
}
}
}
Par défaut, la recherche s’effectue toujours sur tous les champs d’un document
indexé (ou , plus précisément, sur un champ _all dans lequel ElasticSearch
concatène toutes les chaînes de caractères). La syntaxe complète pour associer
le champ et le terme est:
champ:terme
Par exemple, pour ne chercher le mot-clé Alien que dans les titres des films, on peut
utiliser la syntaxe suivante :
{
"query": {
"query_string" : {
"query" : "title:alien"
}
}
}
Revenez au fichier JSON et à la structure de ses documents pour
voir que les données de chaque film sont imbriquées sous un champ fields.
Nous l’omettons dans la suite, pensez à l’ajouter.
Si on ne précise pas le champ, c’est celui par défaut qui est pris en compte. Les requêtes précédentes sont donc équivalentes à:
_all:"Princess Leia"
Les valeurs des termes (dans la requête) et le texte indexé sont tous deux soumis à des transformations que nous étudierons dans le chapitre suivant. Une transformation simple est de tout transcrire en minuscules. La requête:
_all:"PRINCESS LEIA"
devrait donc donner le même résultat, les majuscules étant converties en minuscules. La conception d’un index doit soigneusement indiquer les transformations à appliquer, car elles déterminent le résultat des recherches.
On peut spécifier un terme simple (pas une phrase) de manière incomplète
le “?” indique un caractère inconnue:
opti?aldésigneoptimal,optical, etc.le “*” indique n’importe quelle séquence de caractères (
opti*pour toute chaîne commençant paropti).
La valeur d’un terme peut-être indiquée de manière approximative en ajoutant le suffixe “-”, si l’on n’est pas sûr de l’orthographe par
exemple. Essayez de rechercher optimal, puis optimal-. La proximité des termes est établie par
une distance dite « distance d’édition » (nombre d’opérations d’éditions permettant de passer d’une valeur - optimal -
à une autre - optical).
Des recherches par intervalle sont possibles. Les crochets [] expriment des intervalles bornes comprises, les accolades {} des intervalles bornes non comprises. Voici comment on recherche tous les documents pour une année comprise entre 1990 et 2005:
year:[1990 TO 2005]
Connecteurs booléens¶
Les critères de recherche peuvent être combinés avec les connecteurs Booléens
AND, OR et NOT. Quelques exemples.
year:[1990 TO 2005] OR title:M*
year:[1990 TO 2005] AND NOT title:M*
Important
Attention à bien utiliser des majuscules pour les connecteurs Booléens.
Par défaut, un OR est appliqué, de sorte qu’une recherche sur plusieurs critères ramène l’union
des résultats sur chaque critère pris individuellement.
Venons-en maintenant à l’opérateur « + ». Utilisé comme préfixe d’un nom de champ, il indique que la valeur du champ doit être égale au terme. La recherche suivante:
+year:2000 title:matrix
recherche les documents dont l’année est 2000 (obligatoire) ou dont le titre
est matrix ou n’importe quel titre.
Quelle est alors la différence avec +year:2000? La réponse tient
dans le classement effectué par le moteur de recherche: les documents dont
le titre est matrix seront mieux classés que les autres. C’est une illustration,
parmi d’autres, de la différence entre « recherche d’information » et « interrogation
de bases de données ». Dans le premier cas, on cherche les documents les plus « proches »,
les plus « pertinents », et on classe par pertinence.
Requêtes structurées¶
Nous pouvons donc
transmettre des requêtes dans ElasticVue avec l’interface SEARCH,
mais également
en POST-ant un document JSON décrivant la requête.
Par exemple, votre première requête consiste à trouver les films « Star Wars » de
la base. Le document JSON à POST-er est le suivant:
{
"query": {
"match": {
"title": "Star Wars"
}
}
}
Elle est équivalente à la requête simplifiée, « à la Google »,
_search?q=title:Star+Wars.
Le résultat consiste en un ensemble de documents JSON contenant
le type, l’identifiant interne, le score et la source, cette dernière
étant le document transmis pour indexation, avant transformations.
On peut demander à ne pas obtenir toute la source (option '_source': false),
en sélectionnant en revanche certains champs
qui nous intéressent particulièrement (l’équivalent donc du
select en SQL). On ajoute pour cela un champ fields, ce
qui donne, si on souhaite obtenir seulement le titre:
{
"query": {
"match": {
"title": "Star Wars"
}
},
"fields": ["title"],
"_source": false
}
En utilisant ElasticVue, vous pouvez voir les titres et les scores (Fig. 22).
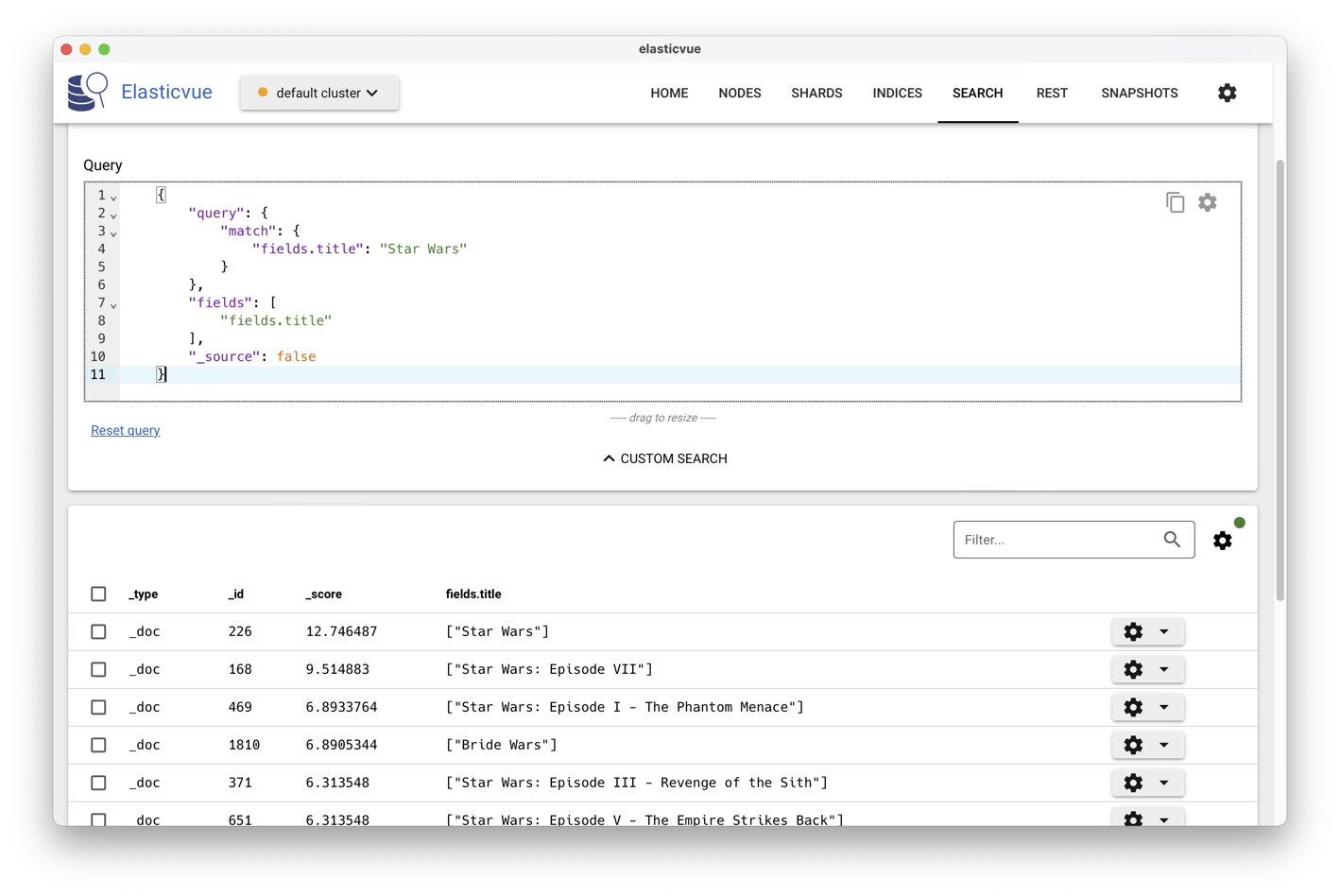
Fig. 22 Affichage des résultats avec les scores.¶
Nous n’allons pas explorer ici toutes les possibilités du DSL, mais essentiellement les recherches exactes. Les recherches plein-texte seront étudiées ultérieurement On les appelle Term-level queries dans la documentation que vous trouverez ici: https://www.elastic.co/guide/en/elasticsearch/reference/current/term-level-queries.html.
Pour effectuer les recherches structurées, on introduit un opérateur dans l’objet
query, exprimant une condition sur certains champs. On peut
par exemple demander les documents dans lesquels un certain champs existe
(ici, le champ summary):
{
"query": {
"exists": {"field": "summary"}
},
"fields": ["title"],
"_source": false
}
Important
Peut-on rechercher les documents pour lesquels un champ n’existe pas ? Oui bien sûr. Il faut utiliser pour celà les opérateurs de combinaison booléenne. Voir plus loin.
Nous n’allons présenter que quelques-uns des opérateurs (reportez-vous
à la documentation pour une présentation complète). L’opérateur
fuzzy permet de chercher les mots proches (syntaxiquement).
Très utile pour ne pas dépendre des fautes d’orthographe! Recherchons
le film Matrice.
{
"query": {
"fuzzy": {
"title": {
"value": "matrice"
}
}
},
"fields": ["title"],
"_source": false
}
On obtient bien un résultat (je vous laisse vérifier). Dans le même esprit on peut faire des recherches par préfixe ou par expression régulière.
Voyons maintenant les recherches par intervalle: la requête suivante retourne tous les films entre 2010 et 2020.
{
"query": {
"range": {
"year": {"gte": 2010, "lte": 2020}
}
},
"fields": ["title", "year"],
"_source": false
}
Il existe divers raffinements selon le type de donnée (et notamment pour les dates). Dans l’exemple ci-dessus, on effectue une recherche sur des entiers (l’année) ce qui est simple à exprimer et interpréter.
Qu’en est-il pour les champs de type text, les plus
courants. Ici, on a deux interprétations possibles: recherche
exacte et recherche approchée, cette dernière impliquant
un classement.
La recherche exacte est exprimée avec l’opérateur term.
Elle s’applique correctement pour des champs texte dont
la valeur est codifiée, par exemple le genre du film.
{
"query": {
"term": {
"genre": {"value": "drama"}
}
},
"fields": ["title"],
"_source": false
}
Mais, notez que nous utilisons le mot drama sans
majuscule, alors que dans le document indexé, c’est bien Drama.
Explication: la recherche exacte porte sur la valeur des champ après
les transformations décrites dans le chapitre Recherche approchée
(et notamment, ici, le placement de tous les caractères en minuscules).
Si on veut l’appliquer aux champs de type texte, il faut
donc « deviner » les transformations effectuées, ce qui n’est pas
toujours facile. Essayez par exemple de chercher Star Wars.
{
"query": {
"term": {
"title": {"value": "star wars"}
}
},
"fields": ["title"],
"_source": false
}
Même en utilisant des minuscules on ne trouve rien car un texte contenant
plusieurs mots est transformé en vecteur (une recherche avec star
en revanche trouve bien des films, mais beaucoup plus que désiré);
Pour les recherches exactes sur du texte, ElasticSearch n’est pas
très adapté, et en tout cas pas l’opérateur term. Je vous
laisse étudier des opérateurs qui étendent term:
terms et terms_set.
Quiz¶
Mise en pratique ElasticSearch¶
La documentation complète sur le DSL d’Elasticsearch se trouve en ligne à l’adresse : https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html. Vous aurez à vous y reporter dans ce qui suit.
Nous allons maintenant
utiliser une base de films plus large que celle que vue précédemment.
Récupérez le fichier suivant contenant environ 5000 films, au format JSON :
http://b3d.bdpedia.fr/files/big-movies-elastic.json. Même s’il
est assez volumineux, il reste possible de le copier/coller
dans ElasticVue pour le transmettre à l’URL _bulk
en mode POST. À défaut, la ligne de commande (pas très simple…)
devrait fonctionner.
curl -XPOST --cacert http_ca.crt -U elastic:mot_de_passe \
https://localhost:9200/_bulk/ --data-binary @big-movies-elastic.json
Dans l’interface ElasticVue, vous devriez voir apparaître un index appelé movies contenant 4850 films.
Les documents ont la structure suivante (notez bien que toutes
les données sont dans un champ imbriqué fields):
{
"fields": {
"directors": [
"Joseph Gordon-Levitt"
],
"release_date": "2013-01-18T00:00:00Z",
"rating": 7.4,
"genres": [
"Comedy",
"Drama"
],
"image_url": "http://ia.media-imdb.com/images/M/MVNTQ3OQ@@._V1_SX400_.jpg",
"plot": "A New Jersey guy dedicated to his family, friends, and church,
develops unrealistic expectations from watching porn and works to find
happ iness and intimacy with his potential true love.",
"title": "Don Jon",
"rank": 1,
"running_time_secs": 5400,
"actors": [
"Joseph Gordon-Levitt",
"Scarlett Johansson",
"Julianne Moore"
],
"year": 2013
},
"id": "tt2229499",
"type": "add"
}
Maintenant, proposez des requêtes pour les besoins d’information suivants.
Films “Star Wars” dont le réalisateur (directors) est “George Lucas” (requête booléenne)
Correction
Dans toutes les solutions vous pouvez ajouter un champ
fieldspour n’afficher que quelques données.{ "query": { "bool": { "must": [ { "match": { "fields.title": "Star Wars" } }, { "match": { "fields.directors": "George Lucas" } } ] } } }
Pour une recherche exacte on utilise
match_phrase:{ "query": { "bool": { "should": [ { "match_phrase": { "fields.title": "Star Wars" } }, { "match": { "fields.directors": "George Lucas" } } ] } } }
ou de manière très compacte:
_search?q=fields.title:Star+Wars directors:George+LucasFilms dans lesquels “Harrison Ford” a joué
Correction
{ "query": { "match": { "fields.actors": "Harrison Ford" } } }
ou
_search?q=fields.actors:Harrison+FordFilms dans lesquels “Harrison Ford” a joué dont le résumé (plot) contient “Jones”.
Correction
{"query":{ "bool": { "must": [ { "match": { "fields.actors": "Harrison Ford" }}, { "match": { "fields.plot": "Jones" }} ] }}}
_search?q=fields.actors=Harrison+Ford fields.plot:JonesFilms dans lesquels “Harrison Ford” a joué dont le résumé (plot) contient “Jones” mais sans le mot “Nazis”
Correction
{"query":{ "bool": { "must": [ { "match": { "fields.actors": "Harrison Ford" }}, { "match": { "fields.plot": "Jones" }} ], "must_not" : { "match" : {"fields.plot":"Nazis"}} }}}
_search?q=actors=Harrison+Ford plot:Jones -plot:NazisFilms de “James Cameron” dont le rang devrait être inférieur à 1000 (boolean + range query).
Correction
{"query":{ "bool": { "must": [ { "match": { "fields.directors": "James Cameron" }}, { "range": { "fields.rank": {"lt":1000 }}} ] }}}
Films de “Quentin Tarantino” dont la note (rating) doit être supérieure à 5, sans être un film d’action ni un drame.
Correction
{ "query": { "bool": { "must": [ { "match_phrase": { "fields.directors": "Quentin Tarantino" } }, { "range": { "fields.rating": { "gte": 5 } } } ], "must_not": [ { "match": { "fields.genres": "Action" } }, { "match": { "fields.genres": "Drama" } } ] } } }
Films de “J.J. Abrams” sortis (released) entre 2010 et 2015
Correction
{ "query": { "bool":{ "must": {"match": {"fields.directors": "J.J. Abrams"}}, "filter": { "range": { "fields.release_date": { "from": "2010-01-01", "to": "2015-12-31"} } } } } }
Proposez maintenant les requêtes d’agrégation permettant d’obtenir les statistiques suivantes.
Important
Certaines de ces requêtes sont assez difficiles. Ne les faites que si vous êtes très motivés pour maîtriser ElasticSearch. La solution sera publiée.
Donner la note (rating) moyenne des films.
Correction
{"size":0, "aggs" : { "note_moyenne" : { "avg" : {"field" : "fields.rating"} }}}
Donner la note (rating) moyenne, et le rang moyen des films de George Lucas.
Correction
{"size": 0,, "query" :{ "match" : {"fields.directors": {"query": "George Lucas", "operator": "and"}} } ,"aggs" : { "note_moyenne" : { "avg" : {"field" : "fields.rating"} }, "rang_moyen" : { "avg" : {"field" : "fields.rank"} } }}
Donnez la note (rating) moyenne des films par année. Attention, il y a ici une imbrication d’agrégats (on obtient par exemple 456 films en 2013 avec un rating moyen de 5.97).
Correction
{"size": 0, "aggs" : { "group_year" : { "terms" : { "field" : "fields.year" }, "aggs" : { "note_moyenne" : { "avg" : {"field" : "fields.rating"} }} }}}
Donner la note (rating) minimum, maximum et moyenne des films par année.
Correction
{"size": 0, "aggs" : { "group_year" : { "terms" : { "field" : "fields.year" }, "aggs" : { "note_moyenne" : {"avg" : {"field" : "fields.rating"}}, "note_min" : {"min" : {"field" : "fields.rating"}}, "note_max" : {"max" : {"field" : "fields.rating"}} } }}}
Donner le rang (rank) moyen des films par année et trier par ordre décroissant.
Correction
{"size": 0, "aggs" : { "group_year" : { "terms" : { "field" : "fields.year", "order" : { "rating_moyen" : "desc" } }, "aggs" : { "rating_moyen" : { "avg" : {"field" : "fields.rating"} }} }}}
Compter le nombre de films par tranche de note (0-1.9, 2-3.9, 4-5.9…). Indice :
group_range.Correction
{"size": 0, "aggs" : { "group_range" : { "range" : { "field" : "fields.rating", "ranges" : [ {"to" : 1.9}, {"from" : 2, "to" : 3.9}, {"from" : 4, "to" : 5.9}, {"from" : 6, "to" : 7.9}, {"from" : 8} ] } }}}
S3: le langage d’interrogation de MongoDB¶
Important
Cette section est conservée pour vous permettre d’aller plus loin mais elle ne fait plus partie du contenu « officiel » du cours. Elle ne sera pas présentée et ne fera l’objet d’aucune question à l’examen.
Supports complémentaires
Précisons tout d’abord que le langage de requête sur des collections est spécifique à MongoDB. Essentiellement,
c’est un langage de recherche dit « par motif » (pattern).
Il consiste à interroger une collection en donnant un objet (le « motif/pattern », en JSON) dont chaque
attribut est interprété comme une contrainte sur la
structure des objets à rechercher.
Voici des exemples, plus parlants que de longues explications. Nous travaillons sur la
base contenant les films complets, sans référence (donc, celle nommée movies
si vous avez suivi les instructions du chapitrte précédent).
L’apprentissage de ce langage n’est pas le sujet de cette session. Ce qui suit ne vise qu’à illustrer une approche délibérement différente de SQL pour tenter d’adapter l’interrogation de bases de données aux documents structurés. Une courte discussion est consacrée à l’opération de jointure, qui n’existe en pas en MongoDB mais qui peut être obtenue en programmant nous-mêmes l’algorithme.
Sélections¶
Commençons par la base: on veut parcourir toute une collection. On utilise
alors find() dans argument.
db.movies.find ()
S’il y a des millions de documents, cela risque de prendre du temps… D’ailleurs, comment savoir combien de documents comprend le résultat?
db.movies.countDocuments ()
Comme en SQL (étendu),
les options skip et limit permettent de « paginer » le résultat. La requête
suivante affiche 12 documents à partir du dixième inclus.
db.movies.find ().skip(9).limit(12)
Implicitement, cela suppose qu’il existe un ordre sur le parcours des documents. Par défaut, cet ordre est dicté par le stockage physique: MongoDB fournit les documents dans l’ordre où il les trouve (dans les fichiers). On peut trier explicitement, ce qui rend le résultat plus déterministe. La requête suivante trie les documents sur le titre du film, puis pagine le résultat.
db.movies.find ().sort({"title": 1}).skip(9).limit(12)
La spécification du tri repose sur un objet JSON, et ne prend en compte que les noms d’attribut sur lesquels s’effectue le tri. La valeur (ici, celle du titre) ne sert qu’à indiquer si on trie de manière ascendante (valeur 1) ou descendante (valeur -1).
Attention, trier n’est pas anodin. En particulier, tout tri implique que le système constitue l’intégralité du résultat au préalable, ce qui induit une latence (temps de réponse) potentiellement élevée. Sans tri, le système peut délivrer les documents au fur et à mesure qu’il les trouve.
Critères de recherche¶
Si on connaît l’identifiant, on effectue la recherche ainsi.
db.movies.find ({"_id": "movie:33"})
Une requête sur l’identifiant ramène (au plus) un seul document. Dans un tel cas, on
peut utiliser findOne.
db.movies.findOne ({"_id": "movie:33"})
Cette fonction renvoie toujours un document (au plus), alors que la fonction find renvoie
un curseur sur un ensemble de documents (même si c’est un singleton). La différence est
surtout importante quand on utilise une API pour accéder à MongoDB avec un
langage de programmation.
Sur le même modèle, on peut interroger n’importe quel attribut.
db.movies.find ({"title": "Alien"})
Ca marche bien pour des attributs atomiques (une seule valeur), mais comment faire pour interroger des objets ou des tableaux imbriqués? On utilise dans ce cas des chemins, un peu à la XPath, mais avec une syntaxe plus « orienté-objet ». Voici comment on recherche les films de Quentin Tarantino.
db.movies.find ({"director.last_name": "Tarantino"})
Et pour les acteurs, qui sont eux-mêmes dans un tableau? Ca fonctionne de la même manière.
db.movies.find ({"actors.last_name": "Tarantino"})
La requête s’interprète donc comme: « Tous les films dont l’un des acteurs se nomme Tarantino ».
Conformément aux principes du semi-structuré, on accepte sans protester la référence à des attributs ou des chemins qui n’existent pas. En fait, dire « ce chemin n’existe pas » n’a pas grand sens puisqu’il n’y a pas de schéma, pas de contrainte sur la structure des objets, et que donc tout chemin existe potentiellement: il suffit de le créer. La requête suivante ne ramène rien, mais ne génére pas d’erreur.
db.movies.find ({"actor.last_name": "Tarantino"})
Important
Contrairement à une base relationnelle, une base semi-structurée ne proteste pas quand on fait une faute de frappe sur des noms d’attributs.
Quelques raffinements permettent de dépasser la limite sur le prédicat d’égalité implicitement
utilisé ici pour comparer les critères donnés et les objets de la base. Pour les chaînes
de caractères, on peut introduire des expressions régulières. Tous les films dont
le titre commence par Re? Voici:
db.movies.find ({"title": /^Re/})
Pas d’apostrophes autour de l’expression régulière. On peut aussi effectuer des recherches par intervalle.
db.movies.find( {"year": { $gte: 2000, $lte: 2005 } })
Projections¶
Jusqu’à présent, les requêtes ramènent l’intégralité des objets satisfaisant les critères de recherche. On peut aussi faire des projections, en passant un second argument à la fonction find().
db.movies.find ({"director.last_name": "Tarantino"}, {"title": true, "actors": 'j'} )
Le second argument est un objet JSON dont les attributs sont ceux à conserver dans le résultat.
Notez que seules les clés du document JSON sont prises en compte (et correspondent
aux attributs à conserver). La valeur ne compte pas, pourvu qu’elle soit différente de 0 ou null.
Opérateurs ensemblistes¶
Les opérateurs du langage SQL in, not in, any et all se retrouvent
dans le langage d’interrogation. La différence, notable, est que SQL applique
ces opérateurs à des relations (elles-mêmes obtenues par des requêtes)
alors que dans le cas de MongoDB, ce sont des tableaux JSON. MongoDB ne
permet pas d’imbriquer des requêtes.
Voici un premier exemple: on cherche les films dans lesquels joue au moins un des artistes dans une liste (on suppose que l’on connaît l’identifiant).
db.movies.find({"actors._id": {$in: ["artist:34","artist:98","artist:1"]}})
Gardez cette recherche en mémoire: elle s’avèrera utile pour contourner
l’absence de jointure en MongoDB. Le in exprime le fait que l’une
des valeurs du premier tableau (actors._id)
doit être égale à l’une des valeurs de l’autre. Il correspond
implicitement, en SQL, à la clause ANY. Pour exprimer le fait que
toutes les valeurs de premier tableau se retrouvent dans le second
(en d’autres termes, une inclusion), on utilise la clause all.
db.movies.find({"director._id": {$all: ["artist:23","artist:147"]}})
Le not in correspond à l’opérateur $nin.
db.movies.find({"director._id": {$nin: ["artist:34","artist:98","artist:1"]}})
Comment trouver les films qui n’ont pas d’attribut summary?
db.movies.find({"summary": {$exists: false}}, {"title": 1})
Opérateurs Booléens¶
Par défaut, quand on exprime plusieurs critères, c’est une conjonction (and)
qui est appliquée. On peut l’indiquer explicitement. Voici la syntaxe
(les films tournés avec Leonardo DiCaprio en 1997):
db.movies.find({$and : [{"year": 1997}, {"actors.last_name": "DiCaprio"}]} )
L’opérateur and s’applique à un tableau de conditions. Bien entendu il
existe un opérateur or avec la même syntaxe. Les films
parus en 1997 ou avec Leonardo DiCaprio.
db.movies.find({$or : [{"year": 1997}, {"actors.last_name": "DiCaprio"}]} )
Voici pour l’essentiel en ce qui concerne les recherches portant sur une collection et consistant à sélectionner des documents. Grosso modo, on obtient la même expressivité que pour SQL dans ce cas. Que faire quand on doit croiser des informations présentes dans plusieurs collections? En relationnel, on effectue des jointures. Avec Mongo, il faut bricoler.
Jointures¶
La jointure, au sens de: associer des objets distincts, provenant en général de plusieurs collections, pour appliquer des critères de recherche croisés, n’existe pas en MongoDB. C’est une limitation importante du point de vue de la gestion de données. On peut considérer qu’elle est cohérente avec une approche documentaire dans laquelle les documents s’appuient sur la dénormalisation et sont supposés indépendants les uns des autres. Cela étant, on peut imaginer toutes sortes de situations où une jointure est quand même nécessaire dans une aplication de traitement de données.
Voyons comment nous pouvons contourner le problème. Nous allons supposer pour les besoins de la cause que la collection des films ne contient que les identifiants des artistes impliquées, et qu’une seconde collection contient les informations sur ces artistes (vous pouvez charger cette dernière collection à partir d’un fichier disponible sur le site).
Une première approche est de créer une vue qui assemble deux collections dans une troisième, virtuel. Cela suppose qu’on accepte de créer une vue pour chaque jointure…
La création de vue est la suivante:
db.createView( "full_movies", "movies", [
{
$lookup:
{
from: "artists",
localField: "director._id",
foreignField: "_id",
as: "metteur_en_scene"
}
}]
)
On crée une collection-vue full_movies qui étend chaque document de la collection
movies``en y intégrant un champ ``metteur_en_scene, lequel contient
le document de la collection artists correspondant à l’identifiant
director._id` (relisez encore une fois si ce n’est pas clair…).
On peut alors interroger la collection full_movies, qui implante à peu près
l’équivalent d’une jointure externe en relationnel.
db.full_movies.find()
L’autre approche consiste à effectuer la jointure côté client, comme illustré sur la Fig. 23. Cela revient essentiellement à appliquer l’algorithme de jointures par boucle imbriquées en stockant des données temporaires dans des structures de données sur le client, et en effectuant des échanges réseaux entre le client et le serveur, ce qui dans l’ensemble est très inefficace.
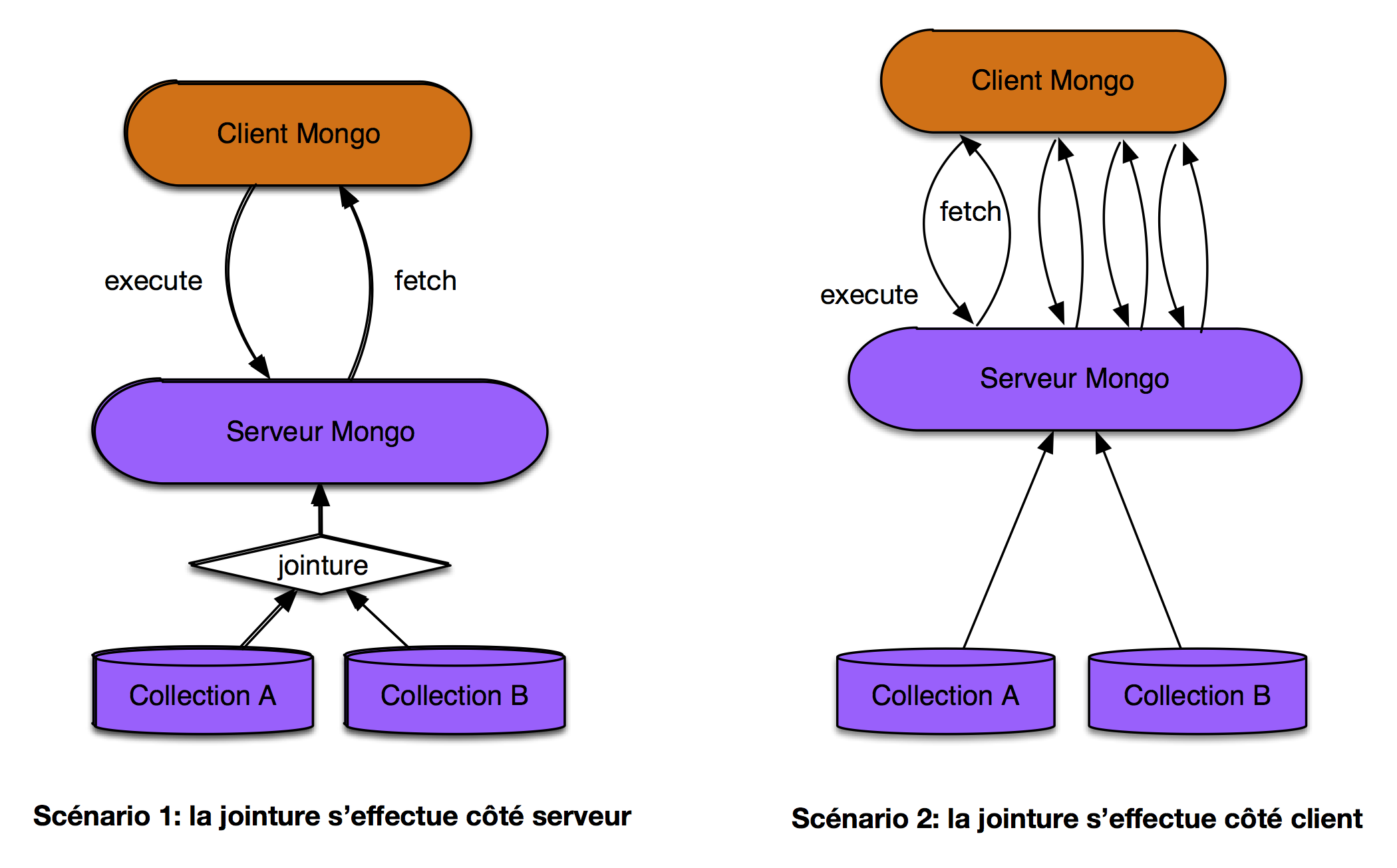
Fig. 23 Jointure côté serveur et côté client¶
Comme l’interpréteur mongo permet de programmer en Javascript, nous pouvons en fait
illustrer la méthode assez simplement. Considérons la requête: « Donnez tous les films dont
le directeur est Clint Eastwood ».
La première étape dans la jointure côté client consiste à chercher l’artiste Clint Eastwood et à le stocker dans l’espace mémoire du client (dans une variable, pour dire les choses simplement).
eastwood = db.artists.findOne({"first_name": "Clint", "last_name": "Eastwood"})
On dispose maintenant d’un objet eastwood. Une seconde requête va récupérer les films
dirigés par cet artiste.
db.movies.find({"director._id": eastwood['_id']}, {"title": 1})
Voilà le principe. Voyons maintenant plus généralement comment on effectue l’équivalent des jointures en SQL. Prenons la requête suivante:
select m.titre, a.* from Movie m, Artist a
where m.id_director = a.id
On veut donc les titres des films et le réalisateur. On va devoir coder, du côté client, un algorithme de jointure par boucles imbriquées. Le voici, sous le shell de MongoDB (et donc en programmation javascript).
var lesFilms = db.movies.find()
while (lesFilms.hasNext()) {
var film = lesFilms.next();
var mes = db.artists.findOne({"_id": film.director._id});
printjson(film.title);
printjson(mes);
}
On a donc une boucle, et une requête imbriquée, exécutée autant de fois qu’il y a de films. C’est exactement la méthode qui serait utilisée par le serveur si ce dernier implantait les jointures. L’exécuter du côté client induit un surcoût en programmation, et en échanges réseau entre le client et le serveur.
Mise en pratique¶
Voici quelques propositions d’exercices si vous souhaitez vous frotter concrètement à l’interrogation MongoDB. Les requêtes s’appliquent à la base des films.
tous les titres;
tous les titres des films parus après 2000;
le résumé de Spider-Man;
qui est le metteur en scène de Gladiator?
titre des films avec Kirsten Dunst;
quels films ont un résumé?
les films qui ne sont ni des drames ni des comédies.
affichez les titres des films et les noms des acteurs.
dans quels films Clint Eastwood est-il acteur mais pas réalisateur (aide: utilisez l’opérateur de comparaison
$ne).Difficile: Comment chercher les films dont le metteur en scène est aussi un acteur? Pas sûr que ce soit possible sans recourir à une auto-jointure, côté client…
Correction
db.movies.find({}, {"title": 1})db.movies.find({"year": {$gt: "2000"}}, {"title": 1, "year": 1})db.movies.find({"title": "Spider-Man"}, {"summary": 1})db.movies.find({"title": "Gladiator"}, {"director": 1})db.movies.find({"actors.last_name": "Dunst"}, {"title": 1})db.movies.find({"summary": {$exists: true}}, {"title": 1})NB: cette fonction regarde si le champ existe, pas s’il est vide ou non. Dans la base, il existe des films avec un résumé ayant pour valeur null. Afin de ne récupérer que les films ayant réellement un résumé, on peut ajouter
$ne:nulldb.movies.find({"summary": {$exists: true, $ne:null}}, {"title": 1})donne les films dont le champ résumé existe et dont la valeur du champ est différente de null.
db.movies.find({"genre": {$nin: ["Drame", "Comédie"]}}, {"title": 1, "genre": 1})db.movies.find({}, {"title": 1, "actors.first_name": 1, "actors.last_name": 1})db.movies.find({"actors.last_name": "Eastwood", "director.last_name": {$ne: "Eastwood"}}, {"title": 1})

Ce cours de Philippe Rigaux est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Table Of Contents
- Introduction
- Préliminaires: Docker
- Modélisation de bases NoSQL
- Recherche exacte
- Etude de cas: Cassandra
- Cassandra - Travaux Pratiques
- Recherche approchée
- ElasticSearch - Travaux pratiques
- Traitements par lot
- Pig : Travaux pratiques
- Le cloud, une nouvelle machine de calcul
- Systèmes NoSQL: la réplication
- Systèmes NoSQL: le partitionnement
- Etude de cas: Apache Spark
- Annales des examens
Recherche
Saisissez un ou plusieurs mots-clés.