Un cours complet en ligne (en anglais) et accompagné d’un ouvrage de
référence : http://www-nlp.stanford.edu/IR-book/. Certaines parties du
cours empruntent des exemples à ce livre.
La Recherche d’Information (RI, Information Retrieval, IR en anglais)
consiste à trouver des documents peu ou faiblement structurés, dans une grande
collection, en fonction d’un besoin d’information. Le domaine d’application
le plus connu est celui de la recherche « plein texte ». Étant donné une
collection de documents constitués essentiellement de texte, comment trouver les
plus pertinents en fonction d’un besoin exprimé par quelques mots-clés? La RI
développe des modèles pour interpréter les documents d’une part, le besoin
d’information d’autre part, en vue de faire correspondre les deux, mais aussi
des techniques pour calculer des réponses rapidement même en présence de
collections très volumineuses. Enfin, des systèmes (appelés « moteurs de
recherches ») fournissent des solutions sophistiquées prêtes à l’emploi.
La RI a pris une très grande importance, en raison notamment de l’émergence
de vastes sources de documents que l’on peut agréger et exploiter (le Web bien
sûr, mais aussi les systèmes d’information d’entreprise). Les techniques
utilisées ont également beaucoup progressé, avec des résultats spectaculaires.
La RI est maintenant omniprésente dans beaucoup d’environnements informatiques,
et notamment:
la recherche sur le Web, utilisée quotidiennement par des milliards d’utilisateurs;
la recherche de messages dans votre boîte mail;
la recherche de fichiers sur votre ordinateur (Spotlight);
la recherche de documents dans une base documentaire, publique ou privée.
Ce chapitre introduit ces différents aspects en se concentrant sur la recherche
d’information appliquée à des collections de documents structurés, comprenant
des parties textuelles importantes.
Comme le montre la définition assez imprécise donnée en préambule, la recherche
d’information se donne un objectif à la fois ambitieux et relativement vague.
Cela s’explique en partie par le contexte d’utilisation de ces systèmes. Avec
une base de données classique, on connaît le schéma des données, leur
organisation générale, avec des contraintes qui garantissent qu’elles ont une
certaine régularité. En RI, les données, ou « documents », sont souvent
hétérogènes, de provenances diverses, présentent des irrégularités et des
variations dues à l’absence de contrainte et de validation au moment de leur
création. De plus, un système de RI est souvent utilisé par des utilisateurs
non-experts. À la difficulté d’interpréter le contenu des documents et de le
décrire s’ajoute celle de comprendre le « besoin », exprimé souvent de manière
très partielle.
D’une certaine manière, la RI vise essentiellement à prendre en compte ces
difficultés pour proposer des réponses les plus pertinentes possibles. La notion
de pertinence est centrale ici: un document est pertinent s’il satisfait le
besoin exprimé. Quand on utilise SQL, on considère que la réponse est toujours
exacte car définie de manière mathématique (en fonction de l’état de la base). En
RI, on ne peut jamais considérer qu’un résultat, constitué d’un ensemble de
documents, est exact, mais on mesure son degré de pertinence (c’est-à-dire les
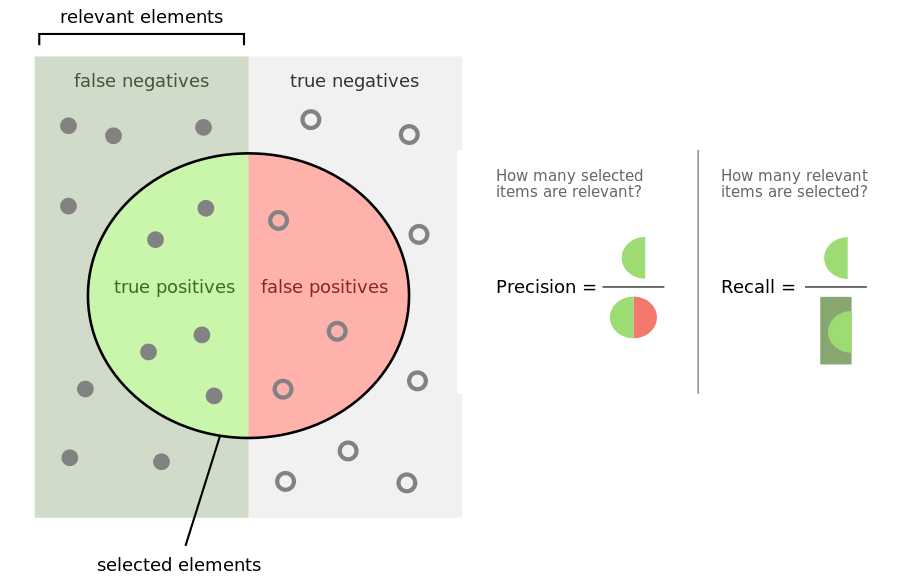
erreurs du système de recherche) en distinguant:
les faux positifs: ce sont les documents non pertinents inclus dans le
résultat; ils ont été sélectionnés à tort. En anglais, on parle de false
positive.
les faux négatifs: ce sont les documents pertinents qui ne sont pas
inclus dans le résultat. En anglais, on parle de false negative.
Les documents pertinents inclus dans le résultat sont appelés les vrais
positifs, les documents non pertinents non inclus dans le résultat sont
appelés les vrais négatifs. On le voit à ce qui vient d’être dit : on
emploie le terme positif pour désigner ce qui a été ramené dans le résultat de
recherche. À l’inverse, les documents qui sont négatifs ont été laissés de
côté par le moteur de recherche au moment de faire correspondre des documents
avec un besoin d’information. Et l’on désigne par vrai ce qui a été bien
classé (dans le résultat ou hors du résultat).
Deux indicateurs formels, basés sur ces notions, sont couramment employés
pour mesurer la qualité d’un système de RI.
La précision
La précision mesure la proportion des vrais positifs dans le résultat r.
Si on note respectivement \(t_p(r)\) et \(f_p(r)\) le nombre de vrais
et de faux positifs dans r (de taille \(|r|\)), alors
Une précision de 1 correspond à l’absence totale de faux positifs. Une
précision nulle indique un résultat ne contenant aucun document pertinent.
Le rappel
Le rappel mesure la proportion des documents pertinents qui sont inclus dans le résultat. Si on note \(f_n(r)\) le
nombre de documents faussement négatifs, alors le rappel est:
\[\frac{t_p(r)}{t_p(r) + f_n(r)}\]
Un rappel de 1 signifie que tous les documents pertinents apparaissent dans le résultat. Un rappel
de 0 signifie qu’il n’y a aucun document pertinent dans le résultat.
La Fig. 31 illustre (en anglais) ces concepts
pour bien distinguer les ensembles dont on parle pour chaque requête de
recherche et les mesures associées.
Ces deux indicateurs sont très difficiles à optimiser simultanément. Pour
augmenter le rappel, il suffit d’ajouter plus de documents dans le résultat, au
détriment de la précision. À l’extrême, un résultat qui contient toute la
collection interrogée a un rappel de 1, et une précision qui tend vers 0.
Inversement, si on fait le choix de ne garder dans le résultat que les documents
dont on est sûr de la pertinence, la précision s’améliore mais on augmente le
risque de faux négatifs (c’est-à-dire de ne pas garder des documents
pertinents), et donc d’un rappel dégradé.
L’évaluation d’un système de RI est une tâche complexe et fragile car elle repose
sur des enquêtes impliquant des utilisateurs. Reportez-vous à l’ouvrage de
référence cité au début du chapitre (et au matériel de cours associé) pour en
savoir plus.
Commençons par étudier une méthode simple de recherche pour trouver des
documents répondant à une recherche dite « plein texte » constituée d’un ensemble
de mots-clés. On va donner à cette recherche une définition assez restrictive
pour l’instant: il s’agit de trouver tous les documents contenant tous les
mots-clés. Prenons pour exemple l’ensemble (modeste) de documents ci-dessous.
Exemple Exemple-S1-1: des petits documents pour comprendre
Et ainsi de suite. Supposons que l’on recherche tous les documents parlant de
loups, de moutons mais pas de bergerie (c’est le besoin). Une solution simple
consiste à parcourir tous les documents et à tester la présence des mots-clés.
Ce n’est pas très satisfaisant car:
c’est potentiellement long, pas sur notre exemple bien sûr, mais en présence d’un ensemble volumineux de documents;
le critère « pas de bergerie » n’est pas facile à traiter;
les autres types de recherche (« le mot “loup” doit être près du mot “mouton” ») sont
difficiles;
quid si je veux classer par pertinence les documents trouvés?
On peut faire mieux en créant une structure compacte sur laquelle peuvent
s’effectuer les opérations de recherche. Les données sont organisées dans une
matrice (dite d’incidence) qui représente l’occurrence (ou non) de chaque mot
dans chaque document. On peut, au choix, représenter les mots en colonnes et les
documents en ligne, ou l’inverse. La première solution semble plus naturelle
(chaque fois que j’insère un nouveau document, j’ajoute une ligne dans la
matrice). Nous verrons plus loin que la seconde représentation, appelée matrice
inversée, est en fait beaucoup plus appropriée pour une recherche efficace.
Terme, vocabulaire.
Nous utilisons progressivement la notion de terme (token en anglais) qui
est un peu différente de celle de « mot ». Le vocabulaire, parfois appelé
dictionnaire, est l’ensemble des termes sur lesquels on peut poser une
requête. Ces notions seront développées plus loin.
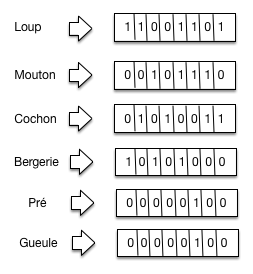
Commençons par montrer une matrice d’incidence avec les documents en ligne. On
se limite au vocabulaire suivant: {« loup », « mouton », « cochon », « bergerie »,
« pré », « gueule »}.
Cette structure est parfois utilisée dans les bases de données sous le nom
d’index bitmap. Elle permet de répondre à notre besoin de la manière suivante :
On prend les vecteurs d’incidence de chaque terme contenu dans la requête,
soit les colonnes dans notre représentation :
Loup: 11001101
Mouton: 00101110
Bergerie: 01010011
On fait un et (logique) sur les vecteurs de
Loup et Mouton et on obtient 00001100
Puis on fait un et du résultat avec le complément du vecteur de
Bergerie (01010111)
On obtient 00000100, d’où on déduit que la réponse est limitée au document
\(d_6\), puisque la 6e position est la seule où il y a un “1”.
Si on imagine maintenant des données à grande échelle, on s’aperçoit que cette
approche un peu naïve soulève quelques problèmes. Posons par exemple les
hypothèses suivantes:
Un million de documents, mille mots chacun en moyenne (ordre de grandeur
d’une encyclopédie en ligne bien connue)
Disons 6 octets par mot, soit 6 Go (pas très gros en fait!)
Disons 500 000 termes distincts (ordre de grandeur du nombre de mots dans
une langue comme l’anglais)
La matrice a 1 000 000 de lignes, 500 000 colonnes, donc \(500 \times 10^9\)
bits, soit 62 GO. Elle ne tient pas en mémoire de nombreuses machines, ce qui va
beaucoup compliquer les choses…. Comment faire mieux?
Une première remarque est que nous avons besoin des vecteurs pour les termes
(mots) pour effectuer des opérations logiques (and, or, not) et il
est donc préférable d’inverser la matrice pour disposer les termes en ligne
(la représentation est une question de convention: ce qui est important c’est
qu’au niveau de la structure de données, le vecteur d’incidence associé à un
terme soit stocké contigument en mémoire et donc accessible simplement et
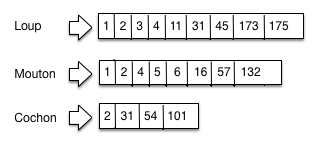
rapidement). On obtient la structure de la Fig. 32
pour notre petit ensemble de documents.
Seconde remarque: la matrice d’incidence est creuse. En effet, sur chaque
ligne, il y a au plus 1000 « 1 » (cas extrême où tous les termes du document sont
distincts). Donc, dans l’ensemble de la matrice, il n’y a au plus que
\(10^9\) positions avec des 1, soit un sur 500. Il est donc tout à fait
inutile de représenter les cellules avec des 0. On obtient une structure appelée
index inversé qui est essentiellement l’ensemble des lignes de la matrice
d’incidence, dans laquelle on ne représente que les cellules correspondant à au
moins une occurrence du terme (en ligne) dans le document (en colonne).
Important
Comme on ne représente plus l’ensemble des colonnes pour chaque ligne, il faut indiquer,
pour chaque cellule, à quelle colonne elle correspond. Pour cela, on place dans
les cellules l’identifiant du document (docId). De plus chaque liste est
triée sur l’identifiant du document.
La Fig. 33 montre un exemple d’index inversé pour trois
termes, pour une collection importante de documents consacrés à nos animaux
familiers. À chaque terme est associé une liste inverse.
On parle donc de cochon dans les documents 2, 31, 54 et 101 (notez que les
documents sont ordonnés — très important). Il est clair que la taille des
listes inverses varie en fonction de la fréquence d’un terme dans la collection.
La structure d’index inversé est utilisée dans tous les moteurs de recherche.
Elle présente d’excellentes propriétés pour une recherche efficace, avec en
particulier des possibilités importantes de compression des listes associées à
chaque terme.
Vocabulaire
Le dictionnaire (dictionary) est l’ensemble
des termes de l’index inversé; le répertoire est la structure qui
associe chaque terme à l’adresse de la liste inversée (posting list) associée au terme.
Enfin on ne parle plus de cellule (la matrice a disparu) mais d’entrée pour
désigner un élément d’une liste inverse.
En principe, le répertoire est toujours en mémoire, ce qui permet de trouver
très rapidement les listes impliquées dans la recherche. Les listes inverses
sont, autant que possible, en mémoire, sinon elles sont compressées et stockées
dans des fichiers (contigus) sur le disque.
Étant donné cette structure, recherchons les documents parlant de loup et de
mouton. On ne peut plus faire un et sur des tableaux de bits de taille fixe
puisque nous avons maintenant des listes de taille variable. L’algorithme
employé est une fusion ( »merge ») de liste triées. C’est une technique très
efficace qui consiste à parcourir en parallèle et séquentiellement des listes,
en une seule fois. Le parcours unique est permis par le tri des listes sur un
même critère (l’identifiant du document).
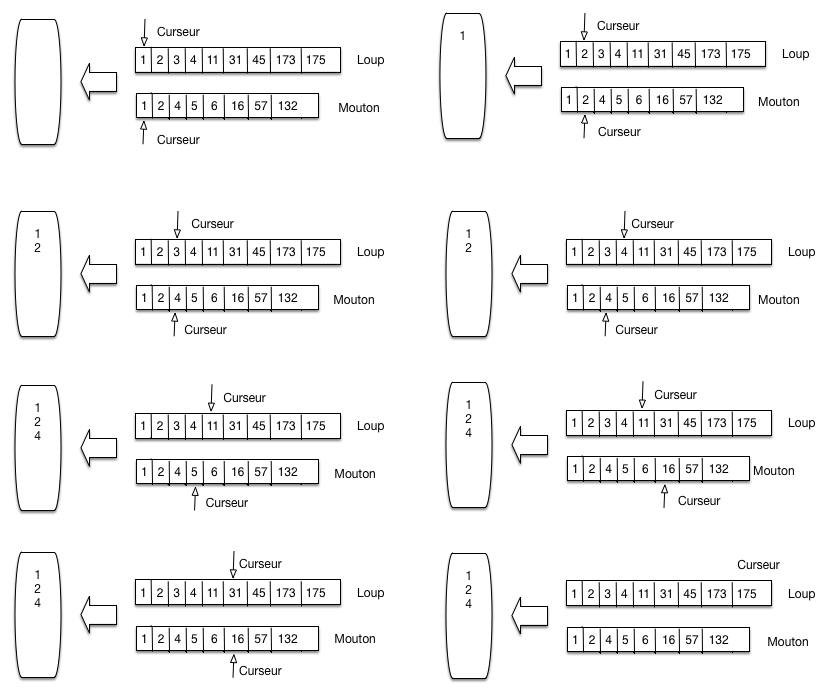
La Fig. 34 montre comment on traite la requête loupetmouton. On maintient deux curseurs, positionnés au départ au début de
chaque liste. L’algorithme compare les valeurs des docId contenues dans les
cellules pointées par les deux curseurs. On compare ces deux valeurs, puis:
(choix A) si elles sont égales, on a trouvé un document: on
place son identifiant dans le résultat, à gauche; on avance les deux curseurs d’un cran
(choix B) sinon, on avance le curseur pointant sur la cellule dont la valeur est la
plus petite, jusqu’à atteindre ou dépasser la valeur la plus grande.
Fig. 34 Parcours linéaire pour la fusion de listes triées¶
La Fig. 34 se lit de gauche à droite, de haut en bas.
On applique tout d’abord deux fois le choix A: les documents 1 et 2 parlent
de loup et de mouton. À la troisième étape, le curseur du haut (loup) pointe
sur le document 3, le pointeur du bas (mouton) sur le document 4. On applique
le choix B en déplaçant le curseur du haut jusqu’à la valeur 4.
Et ainsi de suite. Il est clair qu’un seul parcours suffit. La recherche est
linéaire, et l’efficacité est garantie par un parcours séquentiel d’une
structure (la liste) très compacte. De plus, il n’est pas nécessaire d’attendre
la fin du parcours de toutes les listes pour commencer à obtenir le résultat.
L’algorithme est résumé ci-dessous.
// Fusion de deux listes l1 et l2function Intersect($l1, $l2){ $résultat = []; // Début de la fusion des listes while ($l1 != null and $l2 != null) { if ($l1.docId == $l2.docId) { // On a trouvé un document contenant les deux termes $résultat += $l1.docId; // Avançons sur les deux listes $l1 = $l1.next; $l2 = $l2.next; } else if ($l1.docId < $l2.docId) { // Avançons sur l1 $l1 = $l1.next; } else { // Avançons sur l2 $l2 = $l2.next; } }}
C’est l’algorithme de base de la recherche d’information. Dans la version
présentée ici, on satisfait des requêtes dites booléennes: l’appartenance d’un
document au résultat est binaire, et il n’y a aucun classement par pertinence.
À partir de cette technique élémentaire, on peut commencer à raffiner, pour
aboutir aux techniques sophistiquées visant à capturer au mieux le besoin de
l’utilisateur, à trouver les documents qui satisfont ce besoin et à les classer
par pertinence. Pour en arriver là, tout un ensemble d’étapes que nous avons
ignorées dans la présentation abrégée qui précède sont nécessaires. Nous les
reprenons dans ce qui suit.
En présence d’un document textuel un tant soit peu complexe, on ne peut pas se
contenter de découper plus ou moins arbitrairement en mots sans se poser
quelques questions et appliquer un pré-traitement du texte. Les effets de ce
pré-traitement doivent être compris et maîtrisés: ils influent directement sur
la précision et le rappel. Quelques exemples simples pour s’en convaincre:
si on cherche les documents contenant le mot « loup », on s’attend généralement
à trouver ceux contenant « loups », « Loup », « louve »; il faut donc, quand on
conserve un document dans Elasticsearch, qu’il soit en mesure de mettre ces
différentes formes dans le même index inversé;
si on ne normalise pas (on conserve les majuscules et les pluriels), on va dégrader
le rappel, puisqu’un utilisateur saisissant le mot-clef « loup » ne trouvera
pas les documents dans lesquels ce terme apparaît seulement sous la forme « Loup » ou « loups »;
on le comprend immédiatement avec le cas de « loup / louve », il faut une
connaissance experte de la langue pour décider que « louve » et « loup » doivent
être associés, ce qui requiert une transformation qui dépend de la langue et
nécessite une analyse approfondie du contenu;
inversement, si on normalise (retrait des accents, par exemple) « cote »,
« côte », « côté », on va unifier des mots dont le sens est différent, et on va
diminuer la précision.
En fonction des caractéristiques des documents traités, des utilisateurs de
notre système de recherche, il faudra trouver un bon équilibre, aucune solution
n’étant parfaite. C’est de l’art et du réglage…
L’analyse se compose de plusieurs phases:
Tokenization: découpage du texte en « termes ».
Normalisation: identification de toutes les variantes d’écritures d’un
même terme et choix d’une règle de normalisation (que faire des majuscules? acronymes? apostrophes? accents?).
Stemming (« racinisation »): rendre la racine des mots pour éviter le biais des
variations autour d’un même sens (auditer, auditeur, audition, etc.)
Stop words (« mots vides »), comment éliminer les mots très courants qui ne rendent
pas compte de la signification propre du document?
Ce qui suit est une brève introduction, essentiellement destinée à comprendre
les outils prêts à l’emploi que nous utiliserons ensuite. Remarquons en
particulier que les étapes ci-dessus sont parfois décomposées en sous-étapes
plus fines avec des algorithmes spécifiques (par exemple, un pour les accents,
un autre pour les majuscules). L’ordre que nous donnons ci-dessus est un exemple,
il peut y avoir de légères variations. Enfin, notez bien que le texte
transformé dans une étape sert de texte d’entrée à la transformation suivante
(nous y reviendrons dans la partie pratique).
Un tokenizer prend en entrée un texte (une chaîne de caractères) et produit
une séquence de tokens. Il effectue donc un traitement purement lexical,
consistant typiquement à éliminer les espaces blancs, la ponctuation, les
liaisons, etc., et à identifier les « mots ». Des transformations peuvent
également intervenir (suppression des accents par exemple, ou normalisation des
acronymes - U.S.A. devient USA).
La tokenization est très fortement dépendante de la langue. La première chose à
faire est d’identifier cette dernière. En première approche on peut examiner le
jeu de caractères (Fig. 35).
Il s’agit respectivement du: Coréen, Japonais, Maldives, Malte, Islandais.
Ce n’est évidemment pas suffisant pour distinguer des langues utilisant le
même jeu de caractères. Une extension simple est d’identifier
les séquences de caractères fréquents, (n-grams).
Des bibliothèques fonctionnelles font ça très bien (e.g., Tika, http://tika.apache.org)
Une fois la langue identifiée, on divise le texte en tokens (« mots »).
Ce n’est pas du tout aussi facile qu’on le dirait!
Dans certaines langues (Chinois, Japonais), les mots ne sont pas séparés par des espaces.
Certaines langues s’écrivent de droite à gauche, de haut en bas.
Que faire (et de manière cohérente) des acronymes, élisions, nombres, unités, URL, email, etc.
Que faire des mots composés: les séparer en tokens ou les regrouper en un seul? Par exemple:
Anglais: hostname, host-name et host name, …
Français: Le Mans, aujourd’hui, pomme de terre, …
Allemand: Levensversicherungsgesellschaftsangestellter (employé d’une société d’assurance vie).
Pour les majuscules et la ponctuation, une solution simple est de
normaliser systématiquement (minuscules, pas de ponctuation). Ce qui
donnerait le résultat suivant pour notre petit jeu de données.
La racinisation consiste à confondre toutes les formes d’un même mot, ou de
mots apparentés, en une seule racine. Le stemming morphologique
retire les pluriels, marque de genre, conjugaisons, modes, etc.
Le stemming lexical fond les termes proches lexicalement:
« politique, politicien, police (?) » ou « université, universel, univers (?) ».
Ici, le choix influe clairement sur la précision et le rappel (plus d’unification
favorise le rappel au détriment de la précision).
La racinisation
est très dépendante de la langue et peut nécessiter une analyse linguistique
complexe. En anglais, geese est le pluriel de goose, mice de mouse;
les formes masculin / féminin en français n’ont parfois rien à voir (« loup / louve »)
mais aussi (« cheval / jument »: parle-t-on de la même chose?) Quelques
exemples célèbres montrent les difficultés d’interprétation:
« Les poules du couvent couvent »: où est le verbe, où est le substantif?
« La petite brise la glace »: idem.
Voici un résultat possible de la racinisation pour nos documents.
Il existe des procédures spécialisées pour chaque langue. En anglais,
l’algorithme Snowball de Martin Porter fait
référence et est toujours développé aujourd’hui. Il a connu des déclinaisons
dans de nombreuses langues, dont le français, par un travail collaboratif.
Un des filtres les plus courants consiste
à retire les mots porteurs d’une information faible
( »stop words » ou « mots vides ») afin de limiter le stockage.
Les articles: le, le, ce, etc.
Les verbes « fonctionnels »: être, avoir, faire, etc.
Les conjonctions: et, ou, etc.
et ainsi de suite.
Le choix est délicat car, d’une part, ne pas supprimer
les mots vides augmente l’espace de stockage nécessaire (et ce d’autant
plus que la liste associée à un mot très fréquent est très longue),
d’autre part les éliminer peut diminuer la pertinence des
recherches (« pomme de terre », « Let it be », « Stade de France »).
Parmi les autres filtres, citons en vrac:
Majuscules / minuscules. On peut tout mettre en minuscules, mais
on perd alors la distinction nom propre / nom commu,, par exemple Lyonnaise des Eaux, Société Générale, Windows, etc.
Acronymes.
CAT = cat ou Caterpillar Inc.? M.A.A.F ou MAAF ou Mutuelle … ?
Dates, chiffres.
Monday 24, August, 1572 – 24/08/1572 – 24 août 1572;
10000 ou 10,000.00 ou 10,000.00
Dans tous les cas, les même règles de transformation s’appliquent aux documents
ET à la requête. Voici, au final, pour chaque document la liste
des tokens après application de quelques règles simples.
Le mode d’interrogation classique en base de données consiste à
exprimer des critères de recherche et à produire en sortie les
données qui satisfont exactement ces critères. En d’autres termes,
dans le cas d’une base documentaire, on peut déterminer qu’un document
est ou n’est pas dans le résultat. Cette décision univoque correspond
au modèle de requêtes Booléennes présenté précécemment.
Notions de base: espace métrique, distance et similarité¶
Dans le cas typique
d’un document textuel, il est illusoire de vouloir effectuer une recherche
exacte en tentant de produire comme critère la chaîne de caractères
complète du document, voire même une sous-chaîne.
La même remarque s’applique
à des objets complexes ou multimédia (images, vidéos, etc.). La logique est alors
plutôt d’interpréter la requête comme un besoin, et d’identifier les
documents les plus « proches » du besoin.
En recherche d’information (RI), on raisonne donc plutôt en terme
de pertinence pour décider si un document fait ou non partie du résultat d’une recherche.
La formalisation de ces notions
de besoin et de pertinence est au centre des méthodes de RI.
En particulier, la formalisation de la pertinence consiste à en donner une
expression quantitative. Pour cela, l’approche classique consiste
à définir un espace métrique E doté d’une fonction de distance\(m_E\),
à définir une fonction \(f\) de l’espace des documents vers E; cette fonction s’applique également
à la requête q, vue comme un document;
enfin, on mesure la pertinence (ou similarité) entre
deux documents \(d_1\) et \(d_2\) comme l’inverse de la distance entre \(f(d_1)\)
et \(f(d_2)\).
\[sim(d, q) = \frac{1}{m_E(f(d_1), f(d_2))}\]
On obtient une mesure de la similarité, ou score, mesurant la proximité de deux documents
(ou, plus précisément, des vecteurs représentant ces documents). Il reste à interpréter
la requête \(q\) comme un document et à évaluer \(sim(f(d), f(q))\) pour chaque document d
afin d’évaluer la pertinence d’un document vis-à-vis du besoin
exprimé par la requête.
Avec cette approche, contrairement aux requêtes Booléennes, on ne peut souvent plus dire
de manière stricte qu’un document d n’appartient
pas au résultat d’une recherche. Il est plus correct de dire que d est plus ou
moins pertinent. Cela rend les résultats beaucoup plus riches, et offre à l’utilisateur
la possibilité d’éviter le « tout ou rien » de l’approche Booléenne.
Note
Reportez-vous au chapitre Recherche approchée pour une discussion
introductive sur les notions de faux et vrais positifs, de rappel et de précision.
La contrepartie de cette flexibilité est l’abondance des candidats potentiels
et la nécessité de les classer en fonction de leur pertinence/score. Le rôle d’un
moteur de recherche consiste donc (conceptuellement), pour chaque requête q,
à calculer le score \(s_i = sim(q, d_i)\) pour chaque document \(d_i\)
de la collection, à trier tous les documents par ordre décroissant des scores
et à présenter ce classement à l’utilisateur.
Important
Il faut ajouter une contrainte de temps: le résultat doit être
disponible en quelques dizièmes de secondes, même dans le cas de collections
comprenant des millions, des centaines de millions ou des milliards de documents (cas du Web).
La performance de la recherche s’appuie sur les structures d’index inversés
et des optimisations fines qui dépassent le cadre de ce cours:
reportez-vous, par exemple, au livre en ligne mentionné en début de chapitre.
En pratique, le calcul du score pour tous les documents n’est bien sûr pas
faisable (ni souhaitable d’ailleurs), et le moteur de recherche dispose de structures
de données qui vont lui permettre de déterminer rapidement les
documents ayant le meilleur score. Ces documents (disons les 10 ou 20 premiers, typiquement)
sont présentés à l’utilisateur, et le reste de la liste est calculé à la demande
si besoin est. Dans le cas d’une interface interactive (et si le classement
est réellement pertinent vis-à-vis du besoin), il est rare qu’un utilisateur aille au-delà de la seconde,
voire même de la première page.
Vocabulaire. En résumé, voici les points à retenir.
on effectue des calculs dans un espace métrique, le plus souvent un espace vectoriel;
pour chaque document, on produit un objet de l’espace métrique, appelé descripteur,
qui a le plus souvent la forme d’un vecteur (features vector);
on applique le même traitement à la requête q pour obtenir un descripteur \(v_q\);
le score est une mesure de la pertinence d’un document \(d_i\) par rapport au
besoin exprimé par la requête q;
le calcul du score s’appuie sur la mesure de la distance entre le descripteur de \(d_i\)
et celui de q.
Ces principes étant posés, voyons une application concrète (quoique simplifiée
pour l’instant, et peu satisfaisante en pratique) au cas de la recherche plein texte.
La méthode présentée ci-dessous n’est qu’une première approche,
à la fois très simplifiée et présentant de sévères défauts
par rapport à la méthode générale que nous présenterons ensuite.
Pour commencer, on suppose
connu l’ensemble \(V=\{t_1, t_2, \cdots, t_n\}\) de tous les termes utilisables pour la rédaction d’un
document et on définit E comme l’espace de tous les vecteurs
constitués de n coordonnées valant soit 0, soit 1 (soit,
en notation mathématique, \(E = \{0, 1\}^{n}\)). Ce sont nos descripteurs.
Par exemple, on considère que le vocabulaire est {« papa », « maman », « gateau », « chocolat », « haut », « bas »}.
Nos vecteurs sont donc constitués de 6 coordonnées valant soit 0, soit 1. Il faut alors
définir la fonction \(f\) qui associe un document d à son descripteur (vecteur) \(v = f(d)\).
Voici cette définition:
\[\begin{split}v[i] = \left\{
\begin{array}{ll}
1 \text{ si $d$ contient le terme $t_i$}\\
0 \text{ sinon}
\end{array}
\right.\end{split}\]
C’est exactement la représentation que nous avons adoptée jusqu’à présent. À chaque
document on associe une séquence (un vecteur) de 1 ou de 0 selon que le terme \(t_i\)
est présent ou non dans le document.
Prenons un premier exemple. Le document \(d_{maman}\):
"maman est en haut, qui fait du gateau"
sera représenté par le descripteur/vecteur \([0, 1, 1, 0, 1, 0]\). Je vous laisse
calculer le vecteur de ce second document \(d_{papa}\):
"papa est en bas, qui fait du chocolat"
Note
Remarquez que l’on choisit délibérément d’ignorer certains mots considérés
comme peu représentatifs du contenu du document. Ce sont les stop words (mots
inutiles) comme « est », « en », « qui », « fait », etc.
Note
Remarquez également que l’ordre des mots dans le document est ignoré
par cette représentation qui considère un texte comme un « sac de mots » (bag of words).
Si on prend un document contenant les deux phrases ci-dessus, on ne sait
plus distinguer si papa est en haut ou en bas, ou si maman
fait du gateau ou du chocolat.
Maintenant, contrairement à la recherche Booléenne
dans laquelle on vérifiait que, pour chaque terme requis, la position correspondante dans le vecteur
d’un document était à 1, on va appliquer une fonction de distance sur les vecteurs
afin d’obtenir une valeur entre 0 et 1 mesurant la pertinence.
Un candidat naturel est la distance Euclidienne dont nous rappelons la définition,
pour deux vecteurs \(v_1\) et \(v_2\).
\[\begin{split}sim(v_1, v_2) = \left\{
\begin{array}{ll}
\infty \text{ si $v^i_1=v^i_2$ pour tout $i$ }\\
\frac{1}{E(v_1, v_2)} \text{ sinon}
\end{array}
\right.\end{split}\]
On obtient une mesure de la similarité, ou score, mesurant la proximité de deux documents
(ou, plus précisément, des vecteurs représentant ces documents).
Il reste à interpréter
la requête comme un document et à évaluer \(sim(f(d), f(q))\) pour chaque document d
et la requête q pour évaluer la pertinence d’un document vis-à-vis du besoin
exprimé par la requête. La requête q par exemple:
"maman haut chocolat"
est donc transformée en un vecteur \(v_q = [0, 1, 0, 1, 1, 0]\). Pour le document
\(d_{maman}\), on obtient un score
de \(sim (v_q, d_{maman}) = \frac{1}{\sqrt{2}}\). À vous de calculer
\(sim (v_q, d_{papa})\) et de vérifier que ce score est moins elevé, ce qui correspond
à notre intuition. Notez quand même:
que « chocolat », un des mots-clés de q, n’apparaît pas dans le document \(d_{maman}\), malgré tout classé en tête;
qu’un seul terme est commun entre \(d_{papa}\) et q, et que le document est quand même (bien) classé;
qu’un document comme « bébémangesasoupe » obtiendrait un score non nul (lequel?) et serait donc lui aussi
classé (si on ne met pas de borne à la valeur du score).
Une différence concrète très sensible (illustrée ci-dessus) avec les requêtes Booléennes
est qu’il n’est pas nécessaire
qu’un document contienne tous les termes de la requête pour que son score soit
différent de 0.
Les limites de l’approche présentée jusqu’ici sont explorées dans des
exercices. La méthode beaucoup plus robuste détaillée dans la prochaine section
montrera aussi, par contraste, coment des facteurs comme la taille des documents,
la taille du vocabulaire, le nombre d’occurrences d’un terme dans un document
et la rareté de ce terme influent sur la précision du classement.
Nous reprenons maintenant un approche plus solide pour la recherche plein texte,
qui pour l’essentiel s’appuie sur les principes précédents, mais corrige les
gros inconvénients que vous avez dû découvrir en complétant les exercices.
La méthode présentée dans ce qui suit est maintenant bien établie et utilisée,
à quelques raffinements près, comme approche de base par tous les moteurs de recherche.
Résumons (une nouvelle fois):
les documents (textuels) sont vus comme des sacs de mots, l’ordre entre les mots étant
ignoré; on ne fera pas de différence entre un document qui dit que le mouton est
dans la gueule du loup et un autre qui prétend que le loup est dans la gueule du mouton (?);
quand on parle de « mots », il faut bien comprendre: les termes obtenus par application
d’un processus de simplification / normalisation lexicale déjà étudié;
un descripteur est associé à chaque document, dans un espace doté d’une fonction
de distance qui permet d’estimer la similarité entre deux documents;
enfin, la requête elle-même est vue comme un document, et placée donc dans le même espace;
on considère donc ici les requêtes exprimées comme une liste de mots, sans aucune construction
syntaxique complémentaire.
Ceci posé, nous nous concentrons sur la fonction de similarité.
Note
« mot » et « terme » sont utilisés comme des synonymes à partir de maintenant.
Dans l’approche très simplifiée présentée ci-dessus, nous avons traité les mots uniformément,
selon une approche Booléenne: 1 si le mot est présent dans le document, 0 sinon.
Pour obtenir des résultats de meilleure qualité, on va prendre en compte
les degrés de pertinence et d’information portés par un terme, selon deux principes:
plus un terme est présent dans un document, plus il est représentatif du contenu du document;
moins un terme est présent dans une collection, et plus une occurrence de terme est significative.
De plus, on va tenter d’éliminer le biais lié à la longueur variable
des documents. Il est clair que plus un document est long, et plus il contiendra
de mots et de répétitions d’un même mot. Si on n’introduit pas un élément correctif,
la longueur des documents a donc un impact fort sur le résultat d’une recherche et
d’un classement, ce qui n’est pas forcément souhaitable.
En tenant compte de ces facteurs, on aboutit à affecter un poids
à chaque mot dans un document, et à représenter ce dernier comme un vecteur
de paires (mot, poids), ce qui peut être considéré comme une représentation compacte
du contenu du document. La méthode devenue classique pour déterminer le poids est
de combiner la fréquence des termes et la fréquence inverse (des termes) dans
les documents, ce que l’on abrège par tf (term frequency)
et idf (inverse document frequency).
La fréquence d’un terme t dans un document d est le nombre d’occurrences de
t dans d.
\[\mathrm{tf}(t,d)= n_{t,d}\]
où \(n_{t,d}\) est le nombre d’occurrences de t” dans d. On
représente donc un document par la liste des termes associés à leur fréquence. Si
on prend une collection de documents, dans laquelle certains termes apparaissent
dans plusieurs documents (ce qui est le cas normal), on peut représenter
les tf par une matrice semblable à la matrice d’incidence déjà vue
dans la cas Booléen. Celle ci-dessous correspond à une collection de trois documents,
avec un vocabulaire constitué de 4 termes.
Il y a donc 44 termes dans le document d1, 60 dans le d2 et 70 dans le d3. Il est clair qu’il est difficile
de comparer dans l’absolu des fréquences de terme pour des documents de longueur très différentes, car
la probabilité qu’un terme apparaisse souvent augment avec la taille du document.
Pour s’affranchir de l’effet induit par la taille (qui amènerait à classer systématiquement en tête les
documents longs), on normalise donc les valeurs des tf. Une méthode simple est, par exemple,
de diviser chaque tf par le nombre total de termes dans le document, ce qui donnerait la
matrice suivante:
terme
d1
d2
d3
voiture
27/44
15/60
24/70
marais
3/44
20/60
0
serpent
0
25/60
29/70
baleine
14/44
0
17/70
Un calcul un peu plus sophistiqué consiste à considérer l’ensemble une colonne de la matrice
d’incidence comme un vecteur dans un espace multidimensionel. Dans notre exemple l’espace
est de dimension 4, chaque axe correspondant à l’un des termes. Le vecteur de d1
est (27, 3, 0, 14), celui de d2 (15,20, 25,0), etc.
Pour normaliser ces vecteurs, on va diviser leurs coordonnées par leur norme euclidienne.
Rappel: la norme d’un vecteur \(v = (x_1, x_2, \cdots, x_n)\) est
\[||v|| = \sqrt{x_1^2 + x_2^2 + \cdots + x_n^2}\]
La norme du vecteur d1 est donc:
\[\sqrt{27^2 + 3^2 + 14^2} = 30,56\]
Celle de d2:
\[\sqrt{15^2 + 20^2 + 25^2} = 35,35\]
Celle de d3:
\[\sqrt{24^2 + 29^2 + 17^2} = 41,3\]
On voit que le résultat est assez différent de la simple somme des tf. L’interprétation
des descripteurs de documents comme des vecteurs est à la base d’un calcul de similarité
basé sur les cosinus, que nous détaillons ci-dessous.
La fréquence inverse d’un terme dans les documents (inverse document
frequency, ou idf) mesure l’importance d’un terme par rapport à une
collection D de documents. Un terme qui apparaît rarement peut être considéré
comme plus caractéristique d’un document qu’un autre, très commun. On retrouve
l’idée des mots inutiles, avec un raffinement consistant à mesurer le degré
d’utilité.
L’idf d’un terme t est obtenu en divisant le nombre total de documents par
le nombre de documents contenant au moins une occurrence de t. De plus, on prend
le logarithme de cette fraction pour conserver cette valeur dans un intervalle
comparable à celui du tf.
Notez que si on ne prenait pas le logarithme, la valeur de l’idf pourrait
devenir très grande, et rendrait négligeable l’autre composante du poids d’un
terme. La base du logarithme est 10 en général, mais quelle que soit la base,
vous noterez que l’idf est nul dans le cas d’un terme apparaissant dans tous
les documents (c’est clair? sinon réfléchissez!).
Reprenons notre matrice ci-dessus en supposant que la collection se limite
aux trois documents. Alors
l’idf de « voiture » est 0, car il apparaît dans tous les documents. Intuitivement, « voiture »
est (pour la collection étudiée) tellement courant qu’il n’apporte rien comme critère de recherche.
l’idf de « marais », « serpent » et « baleine » est \(log(3/2)\)
Dans un cas plus réaliste, un terme qui apparaît 100 fois dans une collection d’un million de documents aura
un idf de \(log_{10}(1000000/100) = log_{10}(10000) = 4\) (en base 10). Un terme qui n’apparaît
que 10 fois aura un idf de \(log_{10}(1000000/10) = log_{10}(100000) = 5\). Une valeur d’idf plus élevée
indique le terme est relativement plus important car plus rare.
On peut combiner le tf (normalisé ou non) et l’idf pour obtenir le poids tf.idf d’un terme t dans un document.
C’est simplement le produit des deux valeurs précédentes:
À chaque document d nous associons un vecteur \(v_d\) dont chaque composante \(v_d[i]\)
contient le tf.idf du terme \(t_i\) pour d.
Si le tf n’est pas normalisé, les valeurs des tf.idf
seront d’autant plus élevées que le document est long. En terme de stockage (et pour anticiper un peu sur la
structure des index inversés), il est préférable de stocker
l’idf à part, dans une structure indexée par le terme,
la norme des vecteurs à part, dans une structure indexéee par les documents
et enfin de placer dans chaque cellule la valeur du tf.
On peut alors effectuer le produit tf.idf et la division par la norme au moment du calcul de la distance.
Nous avons donc des vecteurs représentant les documents. La requête
est elle aussi représentée par un vecteur dans lequel les coefficients
des mots sont à 1. Comment calculer la distance entre ces vecteurs?
Si on prend comme mesure la norme de la différence entre deux vecteurs comme nous l’avons fait
initialement, des anomalies sévères apparaissent car deux documents peuvent avoir des
contenus semblables mais des tailles très différentes. La distance Euclidienne n’est donc
pas un bon candidat.
On pourrait mesure la distance euclidienne entre les vecteurs normalisés.
Une mesure plus adaptée en pratique est la similarité cosinus. Commençons par quelques rappels,
en commençant par la formule du produit scalaire de deux vecteurs.
Quel est l’intérêt de prendre ce cosinus comme mesure de similarité? L’idée est que l’on compare
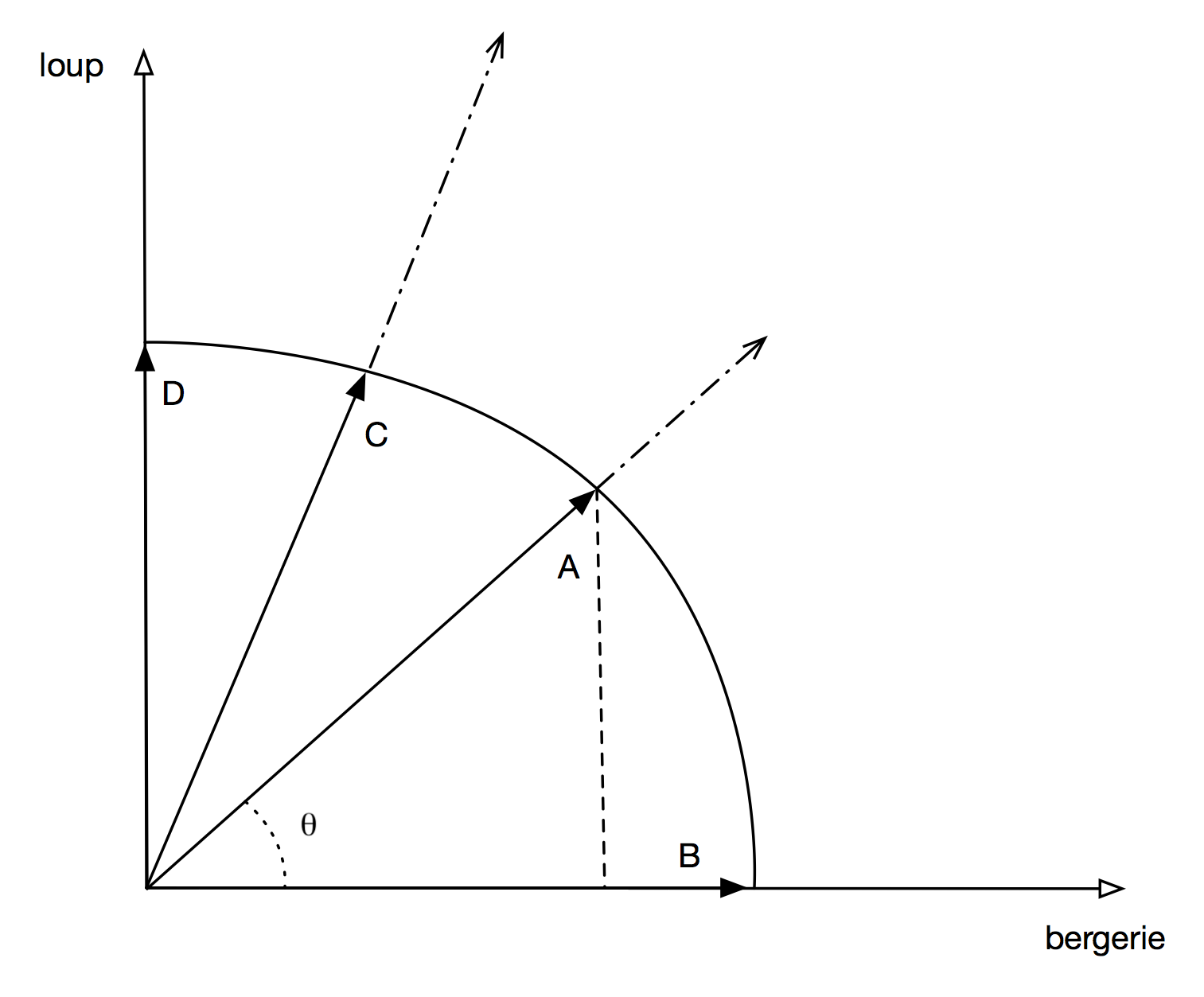
la direction de deux vecteurs, indépendamment de leurs longueurs. La Fig. 36
montre la représentation des vecteurs pour nos documents de l’exercice Ex-S3-1. Les
vecteurs en ligne pleine sont les vecteurs unitaires, normalisés, les lignes pointillées
montrant les vecteurs complets. Pour des raisons d’illustration,
l’espace est réduit à deux dimensions correspondant aux deux termes, « loup » et « bergerie ».
Il faut imaginer un espace vectoriel de dimension n, n étant le nombre
de termes dans la collection, et donc potentiellement très grand.
Les documents (B) et (D) contiennent respectivement une occurrence de « bergerie » et une de « loup »:
ils sont alignés avec les axes respectifs.
Le document (A) contient une occurrence de « loup »
et une de « bergerie » et fait donc un angle de 45 degrés avec l’abcisse: le cosinus de cet angle,
égal à \(\sqrt{2}/2\), représente la similarité entre A et B.
En ce qui concerne C,
« loup » est mentionné deux fois et « bergerie » une, d’où un angle plus important avec l’abcisse.
Le fait d’avoir comme dénominateur
dans la formule le produit des normes revient à normaliser le calcul en ne considérant que des
vecteurs de longueur unitaire. La mesure satisfait aussi des conditions satisfaisantes
intuitivement:
l’angle entre deux vecteurs de même direction est 0, le cosinus vaut 1;
l’angle entre deux vecteurs orthogonaux, donc « indépendants » (aucun terme en commun),
est 90 degrés, le cosinus vaut 0;
toutes les autres valeurs possibles (dans la mesure où les coefficients de nos vecteurs sont
positifs) varient continuement entre 0 et 1 avec la variation de l’angle entre 0 et 90 degrés.
Dernier atout: la similarité cosinus est très simple à calculer, et très rapide pour des vecteurs
comprenant de nombreuses composantes à 0, ce qui est le cas pour la représentation des documents.
Note
La similarité cosinus n’est pas une distance au sens strict du terme (l’inégalité triangulaire
n’est pas respectée), mais ses propriétés en font un excellent candidat.
Passons à la pratique sur notre exemple de trois documents représentés par la matrice
donnée précédemment. On va ignorer l’idf pour faire simple, et se contenter de prendre en compte
le tf.
Commençons par une requête simplissime: « voiture ». Cette requête est représentée dans l’espace
de dimension 4 de notre vocabulaire par le vecteur (1, 0, 0, 0), dont la norme est 1.
On pourrait croire qu’il suffit de prendre le classement des tf
du terme concerné, sans se lancer dans des calculs compliqués, auquel cas
d1 arriverait en tête juste devant d3. Erreur! Ce qui compte ce n’est pas
la fréquence d’un terme, mais sa proportion par rapport aux autres. Il faut appliquer le
calcul cosinus rigoureusement.
Calculons donc les cosinus. Pour d1, le cosinus vaut est le produit scalaire des
vecteurs (27, 3, 0, 14) et (1, 0, 0, 0), divisé par le produit de la norme de ces deux vecteurs:
Pour d2, le cosinus vaut : \(\frac{15 + 0 + 0 + 0}{1 \times 35,35} = 0,424\)
Pour d3, le cosinus vaut : \(\frac{24 + 0 +0 +0}{1,41 \times 41,3} = 0,58\)
Le classement est d1, d3, d2, et on voit que d1 l’emporte assez nettement sur d3 alors que
le nombre d’occurrences du terme « voiture » est à peu près le même dans les deux cas. Explication:
d1 parle essentiellement de voiture, le second terme le plus important, « baleine », ayant moins
d’occurrences. Dans d3 au contraire, « serpent » est le terme principal, « voiture » arrivant en second.
Le document d1 est donc plus pertinent pour la requête et doit être classé en premier.
Prenons un second exemple, « voiture » et « baleine ». Remarquons d’abord que les coefficients de la requête sont (1, 0, 0, 1) et
sa norme \(\sqrt{1+1} = 1,41\). Voici les calculs cosinus:
Pour d1, le cosinus vaut : \(\frac{27 + 14}{1,41 \times 30,56} = 0,95\)
Pour d2, le cosinus vaut : \(\frac{15 + 0}{1,41 \times 35,35} = 0,30\)
Pour d3, le cosinus vaut : \(\frac{24 + 17}{1,41 \times 41,3} = 0,70\)
L’ordre est donc d1, d3, d2. Le document d3 présente un meilleur équilibre
entre les composantes voiture et baleine, mais, contrairement
à d1, il a une autre composante forte pour serpent
ce qui diminue sa similarité.
Quelle méthode stupide donne toujours un rappel maximal?
Quelles sont les valeurs possibles pour la précision si je tire un seul document au hasard?
Si j’effectue un tirage aléatoire, que penser de l’évolution de la précision et du rappel
en fonction de la taille du tirage ?
Correction
Précision: 50 / 60
Rappel: 50 / 80
Ramener tous les documents
La précision est soit 1, soit 0.
Avec un tirage aléatoire, la relation entre espérance du rappel (plus précisément de
l’espérance du rappel) et
nombre de résultats est monotone croissante. La proportion pertinents / non pertinents
reste constante en espérance. Evidemment, plus l’échantillon est restreint, plus
cette hypothèse se fragilise, avec donc une variance qui augmente.
Exercice Ex-S1-2: précision et rappel, réfléchissons.
Soit un système qui affiche systématiquement 20 documents, ni plus ni moins, pour toutes les recherches. Indiquez
quel est la précision et le rappel dans les cas suivants:
Mon besoin de recherche correspond à un document unique de la collection, il est affiché parmi les 20.
Ma base contient 100 documents, je veux tous les obtenir, le système m’en renvoie 20.
Je fais une recherche dont je sais qu’elle devrait me ramener 30 documents. Parmi les
20 que renvoie le système, je n’en retrouve que 10 parmi ceux attendus.
Voici une autre mesure de qualité, que nous appellerons exactitude comme traduction de accuracy (exactitude).
Elle se définit comme la fraction du résultat qui est correcte (en comptant les
vrais positifs et vrais négatifs comme corrects). Donc,
Où p et n désignent les négatifs et positifs, t et f les vrais et faux, respectivement.
Cette mesure ne convient pas en recherche d’information. Pourquoi? Imaginez un système où seule une infime
partie des documents sont pertinents, quelle que soit la recherche.
Quelle serait l’exactitude dans ce cas?
Quelle méthode simple et stupide donnerait une exactitude proche de la perfection?
Correction
L’exactitude tend vers 1
Il suffit de renvoyer un résultat vide, quelle que soit la requête.
Faire un fichier Excel (ou l’équivalent) qui calcule la taille d’une
collection, la taille de la matrice d’incidence, et la densité de 1 dans
cette matrice, en fonction des paramètres suivants :
On sait faire une fusion pour une recherche de type ET. La recherche
de type OU est évidente (?). Montrer qu’un
algorithme similaire existe pour une recherche de type NOT (« les documents
qui parlent de loup mais pas de mouton »).
Exercice Ex-S3-1: premiers pas vers la recherche plein texte
Construisez la fonction qui associe chaque document à un vecteur dans \(\{0, 1\}^{5}\). Vous pouvez
représenter cette fonction sous forme d’une matrice d’incidence.
Calculer le score de chaque document par la distance Euclidienne
pour les recherches suivantes, et en déduire le classsement:
\(q_1\). « loup et pré »
\(q_2\). « loup et mouton »
\(q_3\). « bergerie »
\(q_4\). « gueule du loup »
Correction
Les vecteurs des documents
\(v(A) = [1, 0, 1, 0, 0]\)
\(v(B) = [0, 1, 1, 0, 0]\)
\(v(C) = [1, 1, 1, 0, 0]\)
\(v(D) = [1, 1, 0, 1, 1]\)
Les vecteurs des requêtes
\(v(q_1) = [1, 0, 0, 1, 0]\)
\(v(q_2) = [1, 1, 0, 0, 0]\)
\(v(q_3) = [0, 0, 1, 0, 0]\)
\(v(q_4) = [1, 0, 0, 0, 1]\)
En ce qui concerne les requêtes:
\(E(q_1, A) = \sqrt{2}; E(q_1, B) = \sqrt{4}; E(q_1, C) = \sqrt{3}; E(q_1, D) = \sqrt{2}\). A et D sont les plus pertinents,
suivi de C et enfin B. Notez que A de contient pas le mot « pré ». Pourquoi
obtient-il le même score que D?
\(E(q_2, A) = \sqrt{2}; E(q_2, B) = \sqrt{2}; E(q_2, C) = \sqrt{1}; E(q_2, D) = \sqrt{2}\).
\(E(q_3, A) = \sqrt{1}; E(q_3, B) = \sqrt{1}; E(q_3, C) = \sqrt{2}; E(q_3, D) = \sqrt{5}\).
\(E(q_4, A) = \sqrt{2}; E(q_4, B) = \sqrt{4}; E(q_4, C) = \sqrt{3}; E(q_4, D) = \sqrt{2}\). C’est
donc D qui l’emporte, mais à égalité avec A, ce ne correspond pas vraiment à l’intuition.
Exercice Ex-S3-2: à propos de la fonction de distance
Supposons que l’on prenne comme distance non pas la distance Euclidienne mais le carré
de cette distance. Est-ce que cela change le classement? Qu’est-ce que cela vous inspire?
Correction
On peut effectuer un calcul simplifié de la distance, tant que l’ordre est respecté. Ce
qui nous intéresse en fait, ce n’est pas le score proprement dit, mais l’ordre des scores.
Exercice Ex-S3-3: critique de la distance Euclidienne
La distance que nous avons utilisée mesure la différence entre la requête
et un document, par comparaison des termes un à un. Cela induit des inconvénients
qu’il est assez facile de mettre en évidence.
Supposons maintenant que le vocabulaire a une taille très grande. On fait une recherche avec 1 mot-clé.
quel est le score pour un document qui ne contient 99 termes et pas ce mot-clé?
quel est le score pour un document qui contient 101 termes et le mot-clé?
Conclusion? Le classement obtenu sera-t-il satisfaisant? Trouvez un cas où un document est bien classé
même s’il ne contient pas le mot-clé !
Correction
Distance de \(\sqrt{100}=10\) dans le premier cas; de \(\sqrt{100}\) dans le second également. Ils seront classés au même niveau,
ce qui ne va pas du tout!
Un document avec 50 termes sera mieux classé
que n’importe quel document de 100 termes contenant ou non le mot-clé. Cela nous met sur
la piste de ce qui ne va pas: la mesure que nous utilisons est fortement dépendante de la
taille du document, au détriment de sa pertinence.
Exercice Ex-S3-4: critique de l’hypothèse d’uniformité des termes
Enfin, dans notre approche très simplifiée, tous les termes ont la même importance. Calculez
le classement pour la requête:
\(q_5\). « bergerie et gueule »
et tentez d’expliquer le résultat. Est-il satisfaisant? Quel est le biais (pensez au raisonnement
sur la longueur du document dans l’exercice précédent).
Correction
Vecteur de la requête: \(v(q_5) = [0, 0, 1, 0, 1]]\)
Calcul des classements:
\(E(q_5, A) = \sqrt{2}; E(q_5, B) = \sqrt{2}; E(q_5, C) = \sqrt{3}; E(q_2, D) = \sqrt{4}\).
Tous les documents sont mieux classés que D, alors que « gueule » est un terme plus discriminant.
Je soumets une requête \(t_1, t_2, \cdots, t_n\).
Quel est le poids de chaque terme dans le vecteur représentant cette requête?
La normalisation de ce vecteur est elle importante pour le classement (justifier)?
Exercice Ex-S4-2: encore des voitures, des serpents et des baleines
Reprenons notre exemple des documents d1, d2 et d3,
calculez le classement pour les requêtes suivantes:
serpent
voiture et serpent
Exercice Ex-S4-3: pesons le loup, le mouton et la bergerie
Nous reprenons nos documents de l’exemple Ex-S3-1. Le
vocabulaire est toujours le suivant: {« loup », « mouton », « bergerie », « pré », « gueule »}.
Donnez, pour chaque document, le tf de chaque terme.
Donnez les idf des termes (ne pas prendre le logarithme, pour simplifier).
En déduire la matrice d’incidence montrant l’idf pour chaque
terme, le nombre de termes pour chaque document, et le tf pour chaque cellule.
et calculer le classement avec la distance cosinus, en ne prenant en compte
que le vecteur des tf.
Correction
Les normes:
A: \(\sqrt{1+ 1} = \sqrt{2}\)
B: \(\sqrt{1 + 1} = \sqrt{2}\)
C: \(\sqrt{2^2 + 1 + 1} = \sqrt{6}\)
D: \(\sqrt{2^2 + 1 + 1 + 1} = \sqrt{7}\)
Classement (on ne normalise pas la requête car cela n’influe pas sur le classement,
et du coup on a des cosinus supérieurs à 1):
loup et pré:
A: \(\frac{1 + 0 + 0 + 0 +0}{\sqrt{2}} = 0,707\)
B: \(\frac{0}{\sqrt{2}} = 0\)
C: \(\frac{2 + 0 + 0 + 0 +0}{\sqrt{6}} = 0,816\)
D: \(\frac{1 + 0 + 0 + 1 +0}{\sqrt{7}} = 0,755\)
Seul D contient les deux termes, mais il
en contient aussi beaucoup d’autres. Il est donc
dominé par C, qui parle fortement de loup mais par
de pré, et contient (un peu) moins de termes.
A est bien classé, même s’il ne contient
pas « pré », car (intuitivement)à il parle de « loup »
de manière forte, ne contenant que très peu de termes.
loup et mouton:
A: \(\frac{1 + 0 + 0 + 0 +0}{\sqrt{2}} = 0,707\)
B: \(\frac{0 + 1 + 0 + 0 +0}{\sqrt{2}} = 0,707\)
C: \(\frac{2 + 1 + 0 + 0 +0}{\sqrt{6}} = 1,22\)
D: \(\frac{1 + 2 + 0 + 0 +0}{\sqrt{7}} = 1,13\)
C et D sont à peu près à égalité, comme on peut le
prévoir intuitivement: ils parlent des deux
termes de manière un peu déséquilibrée,
par rapport à la requête. C l’emporte car sa norme est
plus petite, il est donc plus « concentré » sur
les termes de la requête.
bergerie:
A: \(\frac{1}{\sqrt{2}} = 0,707\)
B: \(\frac{1}{\sqrt{2}} = 0,707\)
C: \(\frac{1}{\sqrt{6}} = 0,4\)
D: \(\frac{0}{\sqrt{7}}\)
A et B arrivent à égalité: il parlent tous les deux
une fois de bergerie, et contiennent exactement
un autre terme.
gueule du loup:
A: \(\frac{1 + 0 + 0 + 0 +0}{\sqrt{2}} = 0,707\)
B: \(\frac{0}{\sqrt{2}} = 0\)
C: \(\frac{2 + 0 + 0 + 0 +0}{\sqrt{6}} = 0,816\)
D: \(\frac{1 + 0 + 0 + 0 +1}{\sqrt{7}} = 0,75\)
Même analyse que pour la première requête
Exercice Ex-S4-5: comparons les loups et les moutons
Reprenez une nouvelle fois les documents de l’exercice Ex-S1-1. Vous devriez
avoir la matrice des tf.idf calculée dans l’exercice Ex-S4-3.
classez les documents B, C, D par similarité cosinus décroissante
avec A;
calculez la similarité cosinus entre chaque paire de documents; peut-on
identifier 2 groupes évidents?
Panna cotta (pc): Mettre la crème, le sucre et la vanille dans une casserole et faire frémir. Ajouter
les 3 feuilles de gélatine préalablement trempées dans l’eau froide. Bien remuer
et verser la crème dans des coupelles. Laisser refroidir quelques heures.
Crème brulée (cb): Faire bouillir le lait, ajouter la crème et le sucre hors du feu. Ajouter les
jaunes d’œufs, mettre au four au bain marie et laisser cuire doucement
à 180C environ 10 minutes. Laisser refroidir puis mettre dessus du sucre roux et le
brûler avec un petit chalumeau.
Mousse au chocolat (mc): Faire ramollir le chocolat dans une terrine. Incorporer les jaunes et le sucre.
Puis, battre les blancs en neige ferme et les ajouter délicatement au
mélange à l’aide d’une spatule. Mettre au frais 1 heure ou 2 minimum.
À vous de jouer pour la création de l’index et les calculs de classement.
On prend pour vocabulaire les mots suivants : crème, sucre, œuf, gélatine. Tous
les autres mots sont ignorés.
Donnez la matrice d’incidence avec l’idf de chaque terme, et le tf de chaque paire (terme, document).
Donnez les normes de vecteurs représentant chaque document.
Donner les résultats classés par combinaison tf (on ignore l’idf) pour les requêtes suivantes
crème et sucre
crème et œuf
œuf et gélatine
Même chose mais en tenant compte de l’idf (sans appliquer le logarithme).
Commentez le résultat de la dernière requête. Est-il correct intuitivement? Que penser de l’indexation
du terme “œuf”, est-elle réprésentative du contenu des recettes?
Correction
Matrice d’incidence
Crème apparaît dans 2 documents sur 3, idf=3/2; sucre dans 3 sur 3 (idf=1),
œuf dans 1 sur 3 (idf=3) comme gélatine. On obtient:
pc
cb
mc
crème (3/2)
2
1
0
sucre (1)
1
2
1
œuf (3)
0
1
0
gélatine (3)
1
0
0
Les normes:
pc: \(\sqrt{2^2 + 1+ 1} = \sqrt{6}\)
cb: \(\sqrt{1 + 2^2 + 1} = \sqrt{6}\)
mc: \(\sqrt{1} = 1\)
Classement (on ne normalise pas la requête car cela n’influe pas sur le classement,
et du coup on a des cosinus supérieurs à 1):
crème et sucre:
pc: \(\frac{2+ 1}{\sqrt{6}}\)
cb: \(\frac{1 + 2}{\sqrt{6}}\)
mc: \(\frac{1}{1}\)
crème et œuf:
pc: \(\frac{2}{\sqrt{6}}\)
cb: \(\frac{1 + 1}{\sqrt{6}}\)
mc: \(\frac{0}{1}\)
œuf et gélatine:
pc: \(\frac{1}{\sqrt{6}}\)
cb: \(\frac{1}{\sqrt{6}}\)
mc: \(\frac{0}{1}\)
Etudions maintenant l’impact de l’idf. En prenant le logarithme, on obtient:
\(idf(\text{crème}) = log(1.5) = 0,176\)
\(idf(\text{sucre}) = log(1) = 0\)
\(idf(\text{œuf}) = log(3) = 0,477\)
\(idf(\text{gélatine}) = log(3) = 0,477\)
On remarque que l’IDF de “sucre” vaut zéro, ce qui revient à dire que ce terme
ne sert à rien dans une requête. Cela reflête le fait que “sucre” apparaît
dans tous les documents et que son pouvoir de discrimination est nul.
Ce qui nous donne la matrice des tf.idf suivante:
pc
cb
mc
crème
0,352
0,176
0
sucre
0
0
0
œuf
0
0,477
0
gélatine
0,477
0
0
Un inconvénient immédiat apparaît: le document mc a tous ses coefficients
à zéro et n’apparaîtra dans aucun résultat, même pour les requêtes sur le sucre.
Pour pallier ce défaut, on peut prendre pour l’idf non pas le log mais \(1+log\).
Celà fait partie des très nombreux petits réglages qui font la qualité d’un moteur de recherche.
Les normes des vecteurs:
pc: \(\sqrt{0,352^2 + 0,477^2} = 0,593\)
cb: \(\sqrt{0,176^2 + 0,477^2} = 0,508\)
La requête « œuf et gélatine » est représentée par le vecteur (0,477, 0,477). La similarité
cosinus (toujours en ignorant la norme de la requête qui est constante et ne change
pas le classement) est donc:
pc: \(\frac{0,477^2}{0,593}\)
cb: \(\frac{0,477^2}{0,508}\)
C’est donc la crème brulée qui l’emporte. Pourquoi? Parce que le terme
« œuf » commun entre la requête et le document est prépondérant dans la représentation
vectorielle de ce dernier.
En prenant en compte l’idf, il semble en effet que le document cb parle essentiellement
d’œuf, alors que le document pc parle à peu près à parts égales d’œuf et de crème.
Le document le plus spécifiquement liée à la requête vient donc en premier.
La pauvre mousse au chocolat n’apparaît pas dans le résultat,
alors qu’il faut vraiment des œufs pour la préparer.
Interprétation: clairement, il faut des œufs dans la mousse au chocolat, mais le mot “œuf”
lui-même n’apparaît pas, ce qui fausse les résultats. Le tf est à 0 pour le document mc,
et l’idf de “œuf” est surévalué (parce que le nombre de documents lui-même est
ridiculement petit).
Notre moteur de recherche souffre donc des limitations d’une approche purement lexicale
basée uniquement sur le tf.idf. Il mérite donc des améliorations, la plus séduiasante
étant la consrtruction de réseaux de termes de type word to vec pour tenter d’identifier
les concepts à apparier, plutôt que les termes.
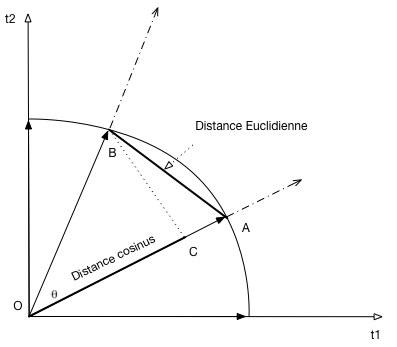
La figure Fig. 38 montre la distance Euclidienne, et la distance cosinus
entre les deux points A et B. Montrez qu’un classement par ordre décroissant
de la similarité cosinus et identique au classement par ordre croissant de
la distance Euclidienne! (Aide: montrez que la distance augmente quand le cosinus
diminue. Un peu de Pythagore peut aider).
Correction
Notons que: OBC et CBA sont deux triangles rectangles, par définition
du cosinus comme projection orthogonale. Par ailleurs, on ne considère pour les calculs
de similarité que les points situés dans le quadrant des coordonnées positives, et le cosinus
est donc une valeur positive entre 0 et 1.
Enfin, on sait que A et B sont sur le cercle trigonométrique. Donc:
\(|| OB || = 1\)
\(||OA || = 1 = ||OC || + || CA ||\)
C’est parti pour Pythagore, comme au collège. Nous avons:
\(|| AB ||^2 = || BC ||^2 + ||AC ||^2\)
\(|| OB ||^2 = 1 = || OC ||^2 + ||BC ||^2\), et donc \(||BC ||^2 = 1 - || OC ||^2\)
AB est la distance euclidienne, OC la distance cosinus comprise entre 0 et 1.
L’une augmente (de 0 à \(\sqrt{2}\)) quand l’autre diminue (de 1 à 0). C.Q.F.D.
La distance cosinus est plus efficace à calculer car il suffit de considérer
les indices des deux vecteurs pour lesquels les coordonnéess
sont toutes les deux non nulles, alors
que pour la distance euclidienne on doit prendre en compte ceux pour lesquelles
au moins une des coordonnées est non nulle.