Les examens de NFE204 durent 3 heures, les documents et autres soutiens
ne sont pas autorisés, à l’exception d’une calculatrice.
Le but de l’examen est de vérifier la bonne compréhension des concepts
et techniques vus en cours. Dans les rares cas où un langage informatique
est impliqué, nous n’évaluons pas les réponses par la syntaxe mais par la clarté,
la concision et la précision.
Première partie : recherche d’information (8 pts)¶
Voici quelques extraits d’un discours politique célèbre (un peu modifié pour les besoins de la cause).
Chaque extrait correspond à un document, numéroté \(a_i\).
(a1) Moi, président de la République, je ne serai pas le chef de la majorité,
je ne recevrai pas les parlementaires de la majorité à l’Elysée.
(a2) Moi, président de la République, je ne traiterai pas mon Premier ministre de collaborateur.
(a3) Moi, président de la République, les ministres de la majorité
ne pourraient pas cumuler leurs fonctions avec un mandat parlementaire ou local.
(a4) Moi, président de la République, il y aura un code de déontologie pour les ministres
et parlementaires qui ne pourraient pas rentrer dans un conflit d’intérêt.
Questions.
Rappeler la notion de stop word (ou « mot vide ») et donner la liste
de ceux que vous choisiriez dans les textes ci-dessus.
Outre ces mots vides, pouvez-vous identifier certains mots dont l’idf tend vers 0
(en appliquant le logarithme)? Lesquels?
Présentez la matrice d’incidence pour le vocabulaire suivant:
majorité, ministre, déontologie, parlementaire.
Vous indiquerez l’idf pour chaque terme (sans logarithme),
et le tf pour chaque paire (terme, document). Bien entendu, on suppose que les
termes ont été fait l’objet d’une normalisation syntaxique au préalable.
Donner les résultats classés par similarité cosinus basée sur les tf (on ignore l’idf) pour les requêtes suivantes.
majorité; expliquez le classement;
ministre; expliquez le classement du premier document;
déontologieetministre; qu’est-ce
qui changerait si on prenait en compte l’idf?
majoritéetministre; qu’obtiendrait-t-on avec une requête Booléenne? Commentaire?
Calculez la similarité cosinus entre a3 et a4; puis entre a3 et a1. Qui est le plus proche de a3?
Un système d’observation spatiale capte des signaux en provenance de planètes
situées dans de lointaines galaxies. Ces signaux sont stockés dans une
collection Signaux de la forme Signaux (idPlanète, date, contenu).
Le but est de déterminer si ces signaux peuvent être émis par une intelligence extra-terrestre.
Pour cela les scientifiques ont mis au point les fonctions suivantes:
Fonction de structure: \(f_S(c): Bool\), prend un contenu en entrée, et renvoie true
si le contenu présente une certaine structure, false sinon.
Fonction de détecteur d’Aliens: \(f_D(<c>): real\), prend une liste de contenus
structurés en entrée, et renvoie
un indicateur entre 0 et 1 indiquant la probabilité que ces contenus
soient écrits en langage extra-terrrestre, et donc la présence d’Aliens!
Bien entendu, il y a beaucoup de signaux: c’est du Big Data.
Questions.
Ecrire un programme Pig latin qui produit, pour chaque planète, l’indicateur de présence d’Aliens
par analyse des contenus provenant de la planète.
Donnez un programme MapReduce qui permettrait d’exécuter ce programme Pig en distribué
(indiquez la fonction de Map, la fonction de Reduce, dans le langage ou pseudo-code qui vous convient).
Ecrire un programme Pig latin qui produit, pour chaque planète et pour chaque jour,
le rapport entre contenus structurés et non structurés reçus de cette planète.
En recherche d’information, qu’est-ce que le rappel? qu’est-ce que la précision?
Deux techniques fondamentales vues en cours sont la réplication et le partitionnement.
Rappelez brièvement leur définition, et indiquez leurs rôles respectifs.
Sont-elles complémentaires? Redondantes?
Qu’est-ce qu’une architecture multi-nœuds, quels sont ses avantages et inconvénients?
Vous avez 500 TOs de données, et vous pouvez acheter des serveurs pour votre cloud
avec chacun 32 GO de mémoire et
10 TOs de disque. Le coût unitaire d’un serveur eest de 500 Euros.
Quelle est la configuration de votre grappe de serveurs la moins coûteuse (financièrement) et combien de temps prend
au minimum la lecture complète de la collection avec cette solution?
Même situation: quelle est la configuration qui assure le maximum d’efficacité, et quel est son coût financier?
Rappelez le principe de l’éclatement d’un fragment dans le partitionnement par intervalle.
Première partie : recherche d’information (8 pts)¶
Voici notre base documentaire:
d1: Le loup et les trois petits cochons.
d2: Spider Cochon, Spider Cochon, il peut marcher au plafond. Est-ce qu’il
peut faire une toile? Bien sûr que non, c’est un cochon.
d3: Un loup a mangé un mouton, les autres moutons sont restés dans la bergerie.
d4: Il y a trois moutons dans le pré, et un autre dans la gueule du loup.
d5: L’histoire extraordinaire des trois petits loups et du grand méchant cochon.
On va se limiter au vocabulaire loup, mouton, cochon.
Donnez la matrice d’incidence booléenne (seulement 0 ou 1)
avec les termes en ligne (NB: on suppose
une phase préalable de normalisation qui élimine les pluriels, majuscules, etc.)
Expliquez par quelle technique, avec cette matrice d’incidence, on peut
répondre à la requête booléenne « loup et cochon mais pas mouton ».
Quel est le résultat?
Maintenant donnez une matrice d’incidence contenant les tf,
et un tableau donnant les idf (sans le log), pour les trois termes précédents.
Donner les résultats classés par similarité cosinus basée sur les tf
(on ignore l’idf) pour les requêtes suivantes.
cochon;
loup et mouton;
loup et cochon.
On ajoute le document d6: « Shaun le mouton: une nuit
de cochon ».
Quel est son score pour la requête « loup et mouton »,
quel autre document a le même score et qu’est-ce qui change
si on prend en compte l’idf?
Pour la requête « loup et cochon » et les documents d1 et d5,
qu’est-ce qui change si on ne met pas de restriction
sur le vocabulaire (tous les mots sont indexés)?
Une organisation terroriste, le Spectre, envisage de commettre un attentat
dans une station de métro. Heureusement, le MI5 dispose d’une base de données d’échanges
téléphoniques et ses experts ont mis au point un décryptage qui identifie
la probabilité qu’un message provienne du Spectre d’une part, et fasse
référence à une station de métro d’autre part.
Après décryptage, les messages obtenus ont la forme suivante:
Il y en a des milliards: vous avez quelques heures pour trouver la solution.
Spécifier les deux fonctions du programme MapReduce qui
va identifier la station-cible la plus probable. Ce programme doit sélectionner
les messages émis par le Spectre avec une probabilité de plus de 70%, et produire,
pour chaque station le nombre de tels messages où elle est mentionnée.
Quel est le programme Pig qui exprime ce traitement MapReduce?
On veut connaître les 5 mots les plus couramment employés par
chaque émetteur dans le contenu de ses messages. Expliquez, avec la formalisation
de votre choix, comment obtenir cette information (vous avez le droit
d’utiliser un opérateur de tri).
En recherche d’information, que signifient les termes « faux positifs »
et « faux négatifs »?
Je soumets une requête \(t_1, t_2, \cdots, t_n\).
Quel est le poids de chaque terme dans le vecteur représentant cette requête?
La normalisation de ce vecteur est elle importante pour le classement (justifier)?
Donnez trois bonnes raisons de choisir un système relationnel plutôt
qu’un système NoSQL pour gérer vos données.
Donnez trois bonnes raisons de choisir un système NoSQL plutôt
qu’un système relationnel pour gérer vos données.
Rappeler la règle du quorum
(majorité des votants) en cas de partitionnement de réseau, et justifiez-la.
Dans un traitement MapReduce, peut-on toujours se contenter d’un seul
reducer? Avantages? Inconvénients?
Une application s’abonne à un flux de nouvelles dont voici un échantillon.
<myrssversion="2.0"><channel><item><title>Angela et nous</title><description>Un nouveau sommet entre la France et l'Allemagne
est prévu en Allemagne la semaine prochaine pour relancer l'UE.
</description><links><link>lemonde.fr</link><link>lesechos.fr</link></links></item><item><title>L'Union en crise</title><description> L'Allemagne, la France, l'Italie doivent à nouveau se
réunir pour étudier les demandes de la Grèce.
</description><links><link>lefigaro.fr</link></links></item><item><title>Alexis à l'action</title><description>Le nouveau premier ministre de la Grèce
a prononcé son discours d'investiture.
</description><links><link>libe.fr</link></links></item><item><title>Nos cousins transalpins</title><description>La France et l'Italie partagent plus qu'une frontière
commune: le point de vue de l'Italie.
</description><links><link>courrier.org</link></links></item></channel></myrss>
Chaque nouvelle (item) résume donc un sujet et propose des liens
vers des médias où le sujet est développé. Les quatre éléments
item seront désignés respectivement par
d1, d2, d3 et d4.
Donnez la forme arborescente de ce document (ne recopiez
pas tous les textes: la structure du document suffit).
Proposez un format JSON pour représenter le même contenu (idem: la structure suffit).
Dans une base relationnelle, comment modéliser
l’information contenue dans ce document?
Quelle est l’expression XPath pour obtenir tous les éléments link?
Quelle est l’expression XPath pour obtenir
les titres des items dont l’un des link est lemonde.fr?
Deuxième partie : recherche d’information (6 pts)¶
On veut indexer les nouvelles reçues de manière à pouvoir les rechercher
en fonction d’un pays. Le vocabulaire auquel on se restreint est donc celui
des noms de pays (Allemagne, France, Grèce, Italie).
Donnez une matrice d’incidence contenant les tf pour les quatre pays,
et un tableau donnant les idf (sans appliquer le log). Mettez les noms de pays
en ligne, et les documents en colonne.
Donner les résultats classés par similarité cosinus basée sur les tf
(on ignore l’idf) pour les requêtes suivantes. Expliquez brièvement le classement.
Italie;
Allemagne et France ;
France et Grèce.
Reprenons la dernière requête, « France et Grèce » et les documents d2 et d3.
Qu’est-ce que la prise en compte de l’idf changerait au classement?
Voici quelques analyses à exprimer avec MapReduce et Pig.
On veut compter le nombre de nouvelles consacrées
à la Grèce publiées par chaque média. Décrivez le programme MapReduce
(fonctions de Map et de Reduce) qui produit le résultat souhaité.
Donnez le pseudo-code de chaque
fonction, ou indiquez par un texte clair son déroulement.
Vous disposez d’une fonction contains(:math:`texte, :math:`mot) qui renvoie vrai
si :math:`texte contient :math:`mot.
Quel est le programme Pig qui exprime ce traitement MapReduce?
Exercice corrigé: documents structurés et MapReduce (8 pts)¶
Note
Ce premier exercice (légèrement modifié et étendu)
est corrigé entièrement. Les autres exercices
consistaient en un énoncé classique de recherche d’information (8 points)
et 4 brèves questions de cours (4 points).
Le service informatique du Cnam a décidé de représenter ses données sous forme de documents
structurés pour faciliter les processus analytiques. Voici un exemple de documents
centrés sur les étudiant.e.s et incluant les Unités d’Enseignement (UE) suivies
par chacun.e.
Sachant que ces documents sont produits à partir d’une base relationnelle,
reconstituez le schéma de cette base et indiquez le contenu des tables correspondant
aux documents ci-dessus.
Il y a clairement une table Inscription(id,nomannée) et une table Note(idInscription,ue,note).
Il y a probablement aussi une table UE mais elle n’est pas strictement nécessaire pour produire
le document ci-dessus.
Question 3: MapReduce et la notion de document « autonome »¶
Question
On veut implanter, par un processus MapReduce, le calcul de la moyenne des notes d’un étudiant.
Quelle est la représentation la plus appropriée parmi les trois précédentes
(une en relationnel, deux en documents structurés), et pourquoi?
La première représentation est très bien adaptée à MapReduce, puisque chaque document
contient l’intégralité des informations nécessaires au calcul. Si on prend
le document pour Jean Dujardin par exemple, il suffit de prendre le
tableau des UE et de calculer la moyenne. Donc, pas besoin de jointure, pas
besoin de regroupement. Le calcul peut se faire intégralement dans la
fonction de Map, et la fonction de Reduce n’a rien à faire.
C’est l’iiustration de la notion de document autonome: pas besoin d’utiliser
des références à d’autres documents (ce qui mène à des jointures en relationnel) ou de distribuer
l’information nécsesaire dans plusieurs documents (ce qui mène à des regroupements en MapReduce).
Si on a choisit de construire les documents structurés en les centrant sur le UEs,
il y a beaucoup plus de travail, comme le montre la question suivante.
Question 4: MapReduce, outil de restructuration/regroupement¶
Question
Spécifiez le calcul du nombre d’étudiants par UE, en MapReduce,
en prenant en entrée des documents centrés sur les étudiants (exemple donné ci-dessus).
Cette fois, il va falloir utiliser toutes les capacités du modèle MapReduce
pour obtenir le résultat voulu. Comme suggéré par la question précédente,
la représentation centrée sur les UE serait beaucoup plus appropriée
pour disposer d’un document autonome contenant toutes les informations
nécessaires. C’est exactement ce que l’on va faire avec MapReduce:
transformer la représentation centrée sur les étudiants en représentation
centrée sur les UEs, le reste est un jeu d’enfant.
Une fonction de Map produit des paires (clé, valeur). La première
question à se poser c’est: quelle est la clé que je choisis de produire?
Rappelons que la clé est une sorte d’étiquette que l’on pose sur
chaque valeur et qui va permettre de les regrouper.
Ici, on veut regrouper par UE pour pouvoir compter tous les étudiants inscrits.
On va donc émettre une paire intermédiaire pour chaque UE mentionnée dans
un document en entrée. Voici le pseudo-code.
function fonctionMap (:math:`doc)# doc est un document centré étudiant{# On parcourt les UEs du tableau UEsfor[:math:`ue in :math:`doc.UEs]do
emit (:math:`ue.id, :math:`doc.nom)done
Quand on traite le premier document de notre exemple, on obtient donc
trois paires intermédiaires:
Un institut chargé d’analyser l’opinion publique collecte des articles parus dans
la presse en ligne, ainsi que les commentaires déposés par les internautes sur ces articles.
Ces informations sont stockées dans une base relationnelle, puis
mises à disposition des analystes sous la forme de documents JSON dont voici
deux exemples.
{"_id":978,"_source":"lemonde.fr","date":"07/02/2017","titre":"Le président Trump décide d'interdire l'entrée de tout étranger aux USA","contenu":"Suite à un décret paru ....","commentaires":[{"internaute":"chocho@monsite.com","note":5,"commentaire":"Les décisions du nouveau président sont inquiétantes ...",{"internaute":"alain@dugenou.com","note":2,"commentaire":"Arrêtons de critiquer ce grand homme..."]{"_id":54,"source":"nimportequoi.fr","date":"07/02/2017","titre":"La consommation de pétrole aide à lutter contre le réchauffement","contenu":"Contrairement à ce qu'affirment les media officiels ....","commentaires":[{"internaute":"alain@dugenou.com","note":5,"commentaire":"Enfin un site qui n'a pas peur de dire la vérité ..."]
Les notes vont de 1 à 5, 1 exprimant un fort désacord avec le contenu de l’article, et 5 un accord complet.
À votre avis, quel est le schéma de la base relationnelle d’où proviennent
ces documents? Montrez comment les informations des documents ci-dessus
peuvent être représentés avec ce schéma (ne recopiez pas tous les textes, donnez
les tables avec quelques lignes montrant la répartition des données).
On collecte des informations sur les internautes (année de naissance, adresse). Où
les placer dans la base relationnelle? Dans le document JSON?
On veut maintenant obtenir une représentation JSON centrée sur les internautes
et pas sur les sources d’information. Décrivez le processus Map/Reduce qui transforme
une collection de documents formatés comme les exemples ci-dessus, en une
collection de documents dont chacun donne les commentaires déposés
par un internaute particulier.
Deuxième partie : recherche d’information (4 pts)¶
On veut indexer les articles pour pouvoir les analyser en fonction des candidats qu’ils
mentionnent. On s’intéresse en particulier à 4 candidats:
Clinton, Trump, Sanders et Bush.
Voici 4 extraits d’articles (ce sont nos documents \(d_1\), \(d_2\), \(d_3\), \(d_4\)).
L’affrontement entre Trump et Clinton bat son plein. Clinton a-t-elle encore une chance?
Tous ces candidats, Clinton, Trump, Sanders et Bush, semblent encore en mesure de l’emporter.
La surprise, c’est Sanders, personne ne l’attendait à ce niveau.
Ce que Bush pense de Trump? A peu de choses près ce que ce dernier pense de Bush.
Questions:
Donnez une matrice d’incidence contenant les tf pour les quatre candidats,
et un tableau donnant les idf (sans appliquer le \(\log\)). Mettez les noms de candidats
en ligne, et les documents en colonne.
Réponse:
d1
d2
d3
d4
Clinton (2)
2
1
0
0
Trump (4/3)
1
1
0
1
Sanders (2)
0
1
1
0
Bush (2)
0
1
0
2
Donner les résultats classés par similarité cosinus basée sur les tf
(on ignore l’idf) pour les requêtes suivantes. Expliquez brièvement le classement.
Bush
Trump et Clinton
Trump et Sanders
Réponse:
Les normes
\(||d_1|| = \sqrt{4+ 1} = \sqrt{5}\)
\(||d_2|| = \sqrt{1+1+1+1} = 2\)
\(||d_3|| = \sqrt{1}\)
\(||d_4|| = \sqrt{1+4}=\sqrt{5}\)
Les cosinus (requête non normalisée).
Bush: d2 : \(\frac{1}{2}=0,5\) ; d4 : \(\frac{2}{\sqrt{5}} \simeq 0,89\) ; d4 est premier car il mentionne deux fois Bush.
d1 est premier comme on pouvait s’y attendre: il parle exclusivement
de Trump et Clinton. Viennent ensuite d2 puis d4.
Trump et Sanders
d1 : \(\frac{1}{\sqrt{5}}\)
d2 : \(\frac{2}{2}\)
d3 : \(\frac{1}{1}\)
d4 : \(\frac{1}{\sqrt{5}}\)
d2 et d3 arrivent à égalité. Intuitivement, il parlent tous les deux « à moitié »
de Trump et Sanders. d1 et d4 parlent de Trump ou de Sanders et aussi des autres
candidats.
Reprenons la requête, « Trump et Clinton » et le premier document du classement.
Quelle légère modification de ce document lui donnerait une mesure cosinus encore plus
élevée? Expliquez pourquoi.
Réponse: Il suffit d’ajouter une fois la mention de Trump.
Je fais une recherche sur « Sanders ». Pouvez-vous indiquer le classement sans faire aucun calcul?
Expliquez.
Réponse: Sanders apparaît dans les documents d2 et d3, et d3 ne parle que de lui alors que d@
parle de tous les candidats. D’où le classement.
On considère un système Cassandra avec un facteur de réplication F= 3 (donc, 3 copies
d’un même document).
Appelons W le nombre d’acquittements reçus pour une écriture, R le
nombre d’acquittements reçus pour une lecture.
Décrivez brièvement les caractéristiques des configurations suivantes:
R=1, W=3
R=1,W=1
Réponse: La première configuration assure des écritures synchrones, et se contente d’une lecture
qui va prendre indifféremment l’une des trois versions. La lecture est cohérente.
La seconde privilégie l’efficacité. On aquitte après une seule écriture, on lit une seule copie
(peut-être pas la plus récente).
Quelle est la formule sur R, W et F qui assure la cohérence immédiate (par opposition
à la cohérence à terme) du système? Expliquez brièvement.
Toujours sur nos documents donnés en début d’énoncé (première partie): on veut analyser, pour la
source « lemonde.fr », le nombre de commentaires ayant obtenus respectivement 1, 2, 3, 4 ou 5.
Décrivez la modélisation MapReduce de ce calcul. Donnez le pseudo-code de chaque fonction, ou
indiquez par un texte clair son déroulement.
Donnez la forme de la chaîne de traitement (workflow), avec des opérateurs Pig ou Spark,
qui implante ce calcul.
Pour cette partie, nous allons nous pencher sur le petit tutoriel proposé par la documentation en ligne de
Cassandra, et consacré à la modélisation des données dans un contexte BigData. L’application (très simplifiée)
est un service de musique en ligne, avec le modèle de données de la figure Fig. 109.
On a donc des chansons, chacune écrite par un artiste, et des playlists, qui consistent
en une liste ordonnée de chansons.
Commencer par proposer le schéma relationnel correspondant à ce modèle. Il est sans
doute nécessaire d’ajouter des identifiants. Donnez les commandes SQL de création des tables. (1 pt).
Le tutoriel Cassandra nous explique qu’il faut concevoir le schéma Cassandra en fonction
des access patterns, autrement dit des requêtes que l’on s’attend à devoir effectuer. Voici
les deux access patterns envisagés:
Find all song titles
Find all songs titles of a particular playlist
Lesquels de ces access patterns posent potentiellement problème avec un système relationnel
dans un contexte BigData et pourquoi ? Vous pouvez donner les requêtes SQL correspondantes
pour clarifier votre réponse (1 pt).
Réponse: le premier implique un parcours séquentiel de la table Song: à priori
un système relationnel peut faire ça très bien. La seconde implique une jointure: les
systèmes relationnels font ça très bien aussi mais ça ne passe pas forcément à très grande
échelle. C’est en tout cas l’argument des systèmes NoSQL.
Le tutoriel Cassandra nous propose alors de créer une unique table
Discutez des avantages et inconvénients en répondant aux questions suivantes: combien faut-il d’insertions
(au pire) pour ajouter une chanson à une playlist, en relationnel et dans Cassandra? Que peut-on dire
des requêtes qui affichent une playlist, respectivement en relationnel et dans Cassandra (donnez
la requête si nécessaire)? Combien de lignes dois-je mettre à jour quand l’âge d’un artiste change,
en relationnel et en Cassandra? Conclusion? (2 pts)
Réponse: Il faut (au pire, c’est à dire si la chanson, l’artiste, la playlist
n’existent pas au préalable) 4 insertions en relationnel, une seule avec Cassandra.
Pour la recherche, jointures indispensables en relationnel. Pour les mises à jour en revanche,
en relationnel, il suffit juste de mettre à jour la ligne de l’artiste dans la table Artist.
En Cassandra il faudra mettre à jour toutes les lignes contenant l’artiste dans la table Playlists.
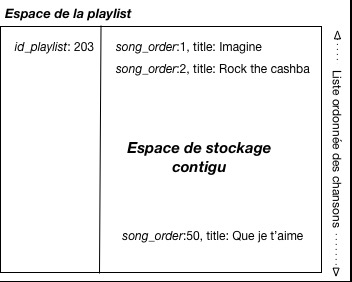
Vous remarquez que l’identifiant de la table est composite (compound en anglais):
(id_playlist,song_order). Voici
ce que nous dit le tutoriel:
« A compound primary key consists of the partition key and the clustering key.
The partition key determines which node stores the data. Rows for a partition key are stored in order based
on the clustering key. »
Sur la base de cette explication, quelles affirmations sont vraies parmi les suivantes:
Une chanson est stockée sur un seul serveur (vrai/faux)?
Les chansons d’une même playlist sont toutes sur un seul serveur (vrai/faux)?
Les chansons stockées sur un serveur sont triées sur leur identifiant (vrai/faux)?
Les chansons d’une même playlist sont stockées les unes après les autres (vrai/faux)?
Réponse: réponses 2 et 4. L’identifiant de la playlist définit le serveur
de stockage. De plus, les chansons d’une même playlist sont stockées dans l’ordre
et contigument. Cf. Fig. 110.
Faites un petit dessin illustrant les caractéristiques du stockage des playlists
dans un système Cassandra distribué (2 pts).
Fig. 110 Le stockage optimal d’une playlist dans Cassandra¶
Pour finir, reprenez les access patterns donnés initialement. Lesquels
vont pouvoir être évalués très efficacement avec cette organisation des données, lesquels
posent des problèmes potentiels de cohérence (1 pt)?
Réponse: réponses 2 et 4. L’access patterns qui peut être évalué facilement est
« find all songs titles of a particular playlist » car il suffit d’avoir
id_playlist pour afficher les chansons. L’évaluation de l’autre pattern
est plus difficile et surtout plus longue car il faut parcourir
tous les enregistrements et ensuite retirer les doublons pour
pouvoir afficher toutes les chansons de la base
Deuxième partie : recherche d’information (5 pts)¶
On veut maintenant équiper notre système d’une fonction de recherche plein texte.
Un premier essai avec le langage CQL de Cassandra est évalué à partir d’un jeu de tests. On obtient les indicateurs
du tableau suivant:
Pertinent
Non pertinent
Positif
200
50
Négatif
100
1800
Sur 250 chansons ramenées dans le résultat, 200 sont pertinentes, 50 ne le sont pas, et il en manque en revanche 100 qui
seraient pertinentes.
Quel est le rappel de votre système? Quelle est sa précision? (1 pt)
Correction
Précision : proportion de vrais positifs. Rappel : proportion de documents pertinents dans le résultat
Précision = 200 / (200 + 50)
Rappel = 200 / (200 + 100)
Essayons de faire mieux en associant Cassandra à ElasticSearch pour pouvoir faire de la recherche avec classement.
Voici quelques extraits de grandes chansons françaises.
Y a vraiment qu’l’amour qui vaille la peine
Que je t’aime, que je t’aime, que je t’aime
Dix ans de chaînes sans voir le jour, c’était ma peine forçat de l’amour
C’est (c’est) pas la peine c’est (c’est) (c’est) pas la peine
On va considérer que la phase d’indexation unifie les termes « amour » et « aime ». Sans faire de calcul,
expliquez le résultat attendu (classement compris) pour les recherches suivantes (2 pts)
amour
peine
peine et aime
Correction
Avec l’hypothèse que la fréquence des termes (Term frequency) possède un poids pour
la similarité de la requête. Les phrases dont aucun mot ne correspond à la requête
ne sont pas concernés par le classement.
Requête « Amour » : Classement proposé - Phrase 2 car « Amour » est présent 3 fois, suivi du même score pour Phrase 1 et Phrase 3
Requête « Peine » : Classement proposé - Phrase 4 car « Peine »
est présent 2 fois, suivi de Phrase 1 et Phrase 3. La phrase 3 est
plus longue donc moins spécifique au mot « peine »: elle sera certainement
classée en dernier.
Requête « Amour » et « Peine » : Classement proposé - Phrase 1 et phrase 3 car
possèdent les 2 mots de la requête; puis Phrase 2 car possède 2 fois le terme « Amour », et enfin Phrase 4 car possède 2 fois « Peine ».
Un de vos collègues n’a pas suivi le cours NFE204 et vous affirme que la similarité cosinus entre un vecteur-document v
et un vecteur-requête q est définie par la formule suivante:
\[cos {\theta} = \sum_{i=1}^n v[i] \times q[i]\]
Où \(x[i]\) désigne le nombre d’occurrences du i*ème terme dans un vecteur *x.
Expliquez pourquoi
votre collègue a tort, et prouvez en prenant un des exemples de recherche ci-dessus que le résultat avec cette formule serait
différent de celui attendu (2 pts).
Correction
Le calcul de la similarité cosinus correspond à la valeur de la projection des
vecteurs « normalisé ». C’est donc la proximité des vecteurs qui est recherché
avec le calcul de la similarité Cosinus. Plus les vecteurs sont proches,
plus la similarité calculé sera importante.
Le nombre d’occurences de chaque terme (fréquence dans un document et dans
l’ensemble des documents) permet de construire les vecteurs descripteurs.
Dans le cas de la présence multiple d’un terme, celui-ci aurait un poids plus important.
Avec l’exemple de la requête « Amour » et « Peine », la phrase 2 obtiendrait le plus
le poids dans le classement avec la formule, car « Amour » est présent 3 fois.
Troisième partie : Comprendre MapReduce tu devras (5 pts)¶
À une époque très lointaine, en pleine guerre intergalactique, deux Jedis
isolés ne peuvent communiquer que par des messages cryptés. Le protocole de cryptage est le suivant:
le vrai message est mélangé à Nfaux messages, N étant très très grand pour déjouer
des services de décryptage de l’Empire.
Les messages sont tous découpés en mots,
et l’ensemble est
transmis en vrac sous la forme suivante:
{"idMessage":"Xh9788&&","mot":"force"
Les Jedi disposent d’une fonction secrète \(f()\) qui prend l’identifiant d’un message et
renvoie vrai ou faux.
Vous devez fournir à Maître Y. le programme MapReduce qui reconstituera le contenu
des vrais messages envoyés par
Obiwan K. à partir d’un flux massifs de documents ayant la forme précédente. On accepte
pour l’instant que les mots d’un message ne soient pas dans l’ordre.
Donnez ce programme sous la forme que vous voulez, pourvu que ce soit clair (1 pt).
Correction
Le programme « fonction secrète », va donc prendre tous les couples (clé, mots)
{"idMessage":"Xh9788&&","mot":"force" en entrée, afin de concaténer
les paires(k,[v]) par une fonction reducer. Le reducer va concatener
les mots sans ordre particulier.
La fonction Map réalise le filtrage :
Fmap(d)
si ffiltre(d.idMessage) alors emit(‘motsDuMessage’,d.mot)
Quel est à votre avis (expliquez) le degré maximal
de parallélisme que l’on peut obtenir pour ce traitement (2 pts)?
Correction
Le degré maximal de parallélisme est limité par le nombre de groupes
transmis à la phase de Reduce. Ici il n’y a qu’un seul groupe
donc aucun parallélisme possible.
Notez que, même après reconstitution, les mots d’un message sont dans n’importe quel ordre.
Maître Y. a la faculté unique de lire et d’écrire des messages dans n’importe quel ordre,
mais comment remettre dans l’ordre les mots des
messages reçus par Obiwan K.? Proposez une extension de la forme des messages et
du programme MapReduce pour que chaque message soit reconstitué dans l’ordre (2 pts).
Puis le reducer va recevoir les paires :
{« idMessage »: « Xh9788&& », {« place »: « 1 », « mot »: « la »,
puis va les ordonner en fonction de leur « place », pour
enfin reconstrituer la phrase. Le reducer devra également
combiner plusieurs fonctions. Ordonner les valeurs, puis concaténer les mots.
Quatrième partie : questions de cours (3 pts)
Dans quelle architecture distribuée peut-on aboutir à des écritures conflictuelles? Donnez un exemple.
Que signifie, pour une structure de partitionnement, être dynamique. Avons-nous
étudié un système où le partitionnement n’était pas dynamique?
Quel est le principe de la reprise sur panne dans Spark?
En période d’épidémie, nous voulons construire un système de prévention. Ce système
doit être informé rapidement des nouvelles infections détectées, retrouver
et informer rapidement les personnes ayant rencontré récemment une personne
infectée, et détecter enfin les foyers infectieux (clusters).
On s’appuie sur une application installée sur les téléphones mobiles. Elle fonctionne
par bluetooth: quand deux personnes équipées de l’application sont proches
l’une de l’autre, l’une d’entre elles (suivant un protocole d’accord)
envoie au serveur un message de contact dont voici trois exemples:
Ce message contient donc un identifiant unique, les pseudonymes
des deux personnes et la date de la rencontre. Un pseudonyme
est une clé chiffrée identifiant une unique personne. Pour des raisons
de sécurité, un nouveau pseudo est généré régulièrement et chaque application
conserve localement la liste des pseudos engendrés.
Les messages de contact (mais pas les listes de pseudos) sont stockés sur un serveur central
dans une base \(DB_1\).
Questions
\(DB_1\) est asymétrique (un pseudo est stocké parfois dans le champ
pseudo1, parfois dans le champ pseudo2) et redondante
puisque chaque contact apparaît plusieurs fois si deux personnes se sont
rencontrées souvent dans la journée (cf. les exemples ci-dessus).
Proposez un traitement de type MapReduce qui produit, à partir
de la base \(DB_1\), une base \(DB_2\) des rencontres quotidiennes
contenant un document par pseudo et par jour, avec la liste
des contacts effectués ce jour-là. Pour les
exemples précédents, on devrait obtenir en ce qui concerne jojoXYZ:
Vous disposez d’une fonction groupby() qui prend un ensemble de valeurs et produit
une liste contenant chaque valeur et son nombre d’occurrences.
Par exemple \(groupby (x, y, x, z, y, x) = [(x,3), (y,2), (z,1)]\).
Attention à l’asymétrie de représentation des pseudos dans les messages.
Voici quatre documents. les deux premiers sont stockés sur le serveur \(S_1\),
le troisième sur le serveur \(S_2\), et le dernier sur le serveur \(S_3\).
Inspirez-vous de la figure Fig. 63.
pour montrer le déroulement du traitement MapReduce avec deux reducers.
Initialement la base \(DB_2\) est relationnelle: quel est son schéma pour pouvoir
représenter correctement le contenu des documents des rencontres quotidiennes?
Vérifiez que votre schéma est correct en donnant le contenu
des tables pour la rencontre du pseudo « jojoXYZ » le 30 juin (document ci-dessus).
Maintenant \(DB_2\) est une base NoSQL documentaire
et les rencontres sont stockées dans une collection Rencontres.
Quand une personne est infectée, elle transmet au
serveur la liste de ses pseudos. Voici par exemple la liste
des pseudos conservés sur mon application mobile:
Tous les jours on stocke les listes dans une collection Infections.
Donnez la chaîne de traitement qui construit la collection de tous les pseudos qui ont
été en contact avec une personne infectée.
Pour spécifier les chaînes de traitement, donner les fonctions de Map et de
Reduce, en javascript, en Pig, en pseudo-code, au pire en langage naturel en étant le plus précis possible.
Correction
Appelons ce traitement Rencontres. Voici la fonction de Map. La clé
est constituée de deux champs, et il faut bien penser à emettre deux messages
pour corriger l’asymétrie des messages de rencontre.
En effectuant la jointure entre pseudosInfectés et Rencontre
on obtient les contacts à prévenir.
contactsAPrevenir =join Rencontre by "pseudo" , pseudosInfectés by "pseudoInfecté";
Deuxième partie : recherche d’information (5 pts)¶
La base des rencontres peut être représentée
comme une matrice dans laquelle chaque vecteur horizontal représente les
rencontres effectuées par une personne dans le passé avec ses contacts.
Nous considérons la matrice suivante. Notez qu’elle est symétrique
et que nous plaçons sur la diagonale le nombre total de contacts
effectués par une personne.
tat37HG
xuyh57
jojoXYZ
Ubbdyu
tat37HG
5
1
1
3
xuyh57
1
3
2
0
jojoXYZ
1
2
3
0
Ubbdyu
3
0
0
3
On veut étudier les foyers infectieux en appliquant des méthodes vues en cours NFE204,
et une ébauche de classification kMeans.
Donnez les normes des vecteurs.
On soupçonne que jojoXYZ et Ubbdyu sont à l’origine de
deux foyers \(C_1\) et \(C_2\). Donnez une mesure de distance basée
sur la similarité cosinus entre ces deux pseudos, entre
jojoXYZ et xuyh57 et finalement entre
Ubbdyu et tat37HG.
En déduire la composition des deux foyers.
Outre la fonction cosinus, on dispose d’une fonction centroid(G) qui calcule le centroïde
d’un ensemble de vecteurs G.
Quelle chaîne de traitement scalable permet de produire la classification
de tous les pseudos dans l’un des deux foyers et d’obtenir
les nouveaux centroïdes?
La chaîne de traitement précédente doit être répétée
jusqu’à convergence pour obtenir un kMeans complet. Si on travaille
avec Spark, quelles informations devraient être conservées dans
un RDD persistant selon vous?
La matrice doit être dans un RDD persistant. À chaque étape il
faut également conserver les centroïdes en mémoire RAM.
Troisième partie : analyse à grande échelle (5 pts)¶
On veut maintenant contrôler la propagation du virus grâce aux informations
recueillies. On prend la matrice des rencontres suivantes (la même
que précédemment mais
cette fois la diagonale est à 0 puisqu’on s’intéresse à la transmission
d’une personne à l’autre).
tat37HG
xuyh57
jojoXYZ
Ubbdyu
tat37HG
0
1
1
3
xuyh57
1
0
2
0
jojoXYZ
1
2
0
0
Ubbdyu
3
0
0
0
Faisons quelques hypothèses simplificatrices:
le nombre de rencontres de chaque pseudo avec un contact
représente la probabilité de rencontrer chacun des contacts.
Par exemple, le premier document ci-dessus nous dit que jojoXYZ
a deux fois plus de chances de rencontrer xuyh57 que
de rencontrer tat37HG.
La liste des contacts est fixe.
Chaque personne fait exactement une rencontre par jour.
En résumé, chaque personne rencontre exactement un de ses 3 contacts, chaque jour,
avec une probabilité proportionnelle à la fréquence antérieure des rencontres avec
ces mêmes contacts.
Donnez la matrice des probabilités de contact obtenue à partir de la
matrice des rencontres
Dessinez le graphe en étiquetant les arêtes par leur probabilité.
On reçoit l’information que jojoXYZ est infecté: quelle
est la probabilité que Ubbdyu le soit également deux jours plus tard?
Si l’une des personnes de notre groupe est infectée,
expliquez comment on calcule les probabilités d’infection de chaque personne n jours plus tard. Donnez
l’exemple de la première étape.
Correction
Voici la matrice de transition. La somme des termes sur
chaque ligne doit être égale à 1.
tat37HG
xuyh57
jojoXYZ
Ubbdyu
tat37HG
0
1/5
1/5
3/5
xuyh57
1/3
0
2/3
0
jojoXYZ
1/3
2/3
0
0
Ubbdyu
1
0
0
0
Voir figure reseausocial
On part avec le vecteur \((0, 0, 1, 0)\) représentant
le fait que jojoXYZ est infecté. On multiplie
par chaque vecteur de transition et on obtient la
probabilité \(\frac{1}{3}\) d’infecter tat37HG, \(\frac{2}{3}\)
d’infecter xuyh57
Seconde étape : le vecteur est \((1/3, 2/3, 0, 0)\). Si on part
de tat37HG, ça nous laisse une probabilité \(\frac{3}{15}\)
d’infecter Ubbdyu.
C’est exactement PageRank: on multiplie le vecteur et la matrice
jusqu’à convergence (garantie).
Voici également un tout petit échantillon de la base.
id
nom
idPère
idMère
102
Charles IX
87
41
65
Laurent de Médicis
87
Henri II
34
34
François Ier
97
Marguerite de Valois
87
41
41
Catherine de Médicis
65
43
François II
87
41
Proposez une représentation sous forme de document structuré (JSON ou XML)
de l’entité Charles IX et de ses ascendants.
Que proposeriez-vous pour ajouter dans cette représentation la fratrie de Charles IX?
Discutez brièvement des avantages et inconvénients de votre solution.
Proposez une représentation sous forme de document structuré (JSON ou XML)
de l’entité François 1er et de ses descendants.
Conclusion: Vers quel type de base NoSQL vous tourneriez-vous et pour quelle raison?
Nous disposons d’une matrice M de dimension \(N \times N\)
représentant les liens entres les \(N\) pages du Web, chaque lien étant
qualifié par un facteur d’importance (ou « poids »). La matrice est représentée par une
collection math:C dans laquelle chaque document est de la forme
{« id »: &23, « lig »: i, « col »: j, « poids »: \(m_{ij}\), et
représente un lien entre la page \(P_i\) et la page \(P_j\) de poids \(m_{ij}\)
Exemple: voici une matrice \(M\) avec \(N=4\). La première cellule de la seconde ligne
est donc représentée par
un document {« id »: &t5x, « lig »: 2, « col »: 1, « poids »: 7
On estime qu’il y a environ \(N=10^{10}\) pages sur le Web, avec 15 liens par
page en moyenne. Quelle est la taille de la collection \(C\), en TO, en supposant que chaque document
a une taille de 16 octets?
Nos serveurs ont 2 disques de 1 TO chacun et chaque document est répliqué 2 fois (donc trois versions en tout).
Combien affectez-vous de serveurs au système de stokage?
Chaque ligne \(L_i\) de \(M\) peut être vue comme un vecteur décrivant la page \(P_i\). Spécifiez le
traitement MapReduce qui calcule la norme de ces vecteurs à partir des documents de la collection \(C\).
Nous voulons calculer le produit de la matrice avec un vecteur \(V(v_1, v_2, \cdots v_N)\) de dimension \(N\).
Le résultat est un autre vecteur \(W\) tel que:
\[w_i = \Sigma_{j=1}^N m_{ij} \times v_j\]
On suppose pour le moment que \(V\) tient en mémoire RAM
et est accessible comme variable statique par toutes les fonctions de Map ou de Reduce.
Spécifiez le traitement MapReduce qui implante ce calcul.
Maintenant, on suppose que \(V\) ne tient plus en mémoire RAM. Proposez
une méthode de partitionnement de la collection \(C\) et de \(V\) qui permette d’effectuer
le calcul distribué de \(M \times V\) avec MapReduce sans jamais avoir à lire
le vecteur sur le disque.
Donnez le critère de partitionnement et la technique (par intervalle ou par hachage).
Supposons qu’on puisse stocker au plus deux (2) coordonnées d’un vecteur
dans la mémoire d’un serveur. Inspirez-vous de la figure http://b3d.bdpedia.fr/calculdistr.html#mr-execution-ex
pour montrer le déroulement du traitement distribué précédent en choisissant le nombre minimal de serveurs
permettant de conserver le vecteur en mémoire RAM.
Pour illustrer le calcul, prenez la matrice \(4\times4\) donnée en exemple, et le vecteur \(V = [4,3,2,1]\).
Expliquez pour finir comment calculer la similarité cosinus entre \(V\) et les \(L_i\).
Les articles de recherche universitaires sont maintenant gérés dans des dépôts
d’archive, comme HAL en France. Posons-nous quelques questions sur le fonctionnement
d’une telle archive.
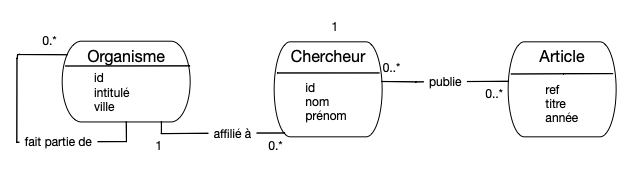
Un modèle très sommaire du dépôt est donné dans la figure ci-dessous.
Les chercheurs
publient des articles (qui peuvent avoir plusieurs co-auteurs) et sont emph{affiliés à des organismes
de recherche. Ces organismes sont hiérarchiquement structurés : un chercheur peut être
attaché à une équipe (organisme de base), qui fait partie d’un laboratoire (organisme
parent) qui lui-même fait partie d’un établissement (par exemple le Cnam), etc.
Voici également un tout petit échantillon de la base relationnelle.
ref
titre
année
hal-875
Music modeling
2018
hal-293
Recommendations on Twitter
2019
La table Article
id
nom
affiliation
nt
Travers
DVRC
pr
Rigaux
Vertigo
rfs
Fournier-S’niehotta
Vertigo
cdm
du Mouza
ISID
La table Chercheur
refArticle
idAuteur
hal-875
nt
hal-293
nt
hal-875
pr
hal-875
rfs
hal-293
cdm
La table Auteur
Proposez un format de document JSON représentant toutes les informations
relatives à l’article hal-875 présentes dans les trois tables ci-dessus (représentation A).
Correction
On part de la ligne relationnelle hal-875 puis on
« navigue » dans la base pour trouver les informations
liées à l’article, soit les auteurs.
Proposez un document JSON représentant toutes les
informations relatives à l’organisme Vertigo présentes dans 3 tables ci-dessus
(représentation B).
Correction
On sait peu de choses sur Vertigo, à part son intitulé.
On développe donc la liste des chercheurs, puis,
pour chaque chercheur, de ses articles, ce qui introduit
une redondance importante.
Expliquez le calcul MapReduce permettant de produire les documents
B à partir des documents A.
Important : pour spécifier les calculs MapReduce, donner les fonctions de Map
et de Reduce, en javascript,
en pseudo-code, au pire en langage naturel en étant le plus précis possible.
Correction
Dans un document de type A, reçu par la fonction de Map,
on doit aller chercher dans les auteurs de l’article
l’affiliation, et émettre une paire dont
cette affiliation est la clé.
function fonctionMap ($doc)# doc est un document de type Article{# On parcourt les auteursfor[$cin$doc.auteurs]do
emit ($c.affiliation, $doc)done
Remarques: on va faire autant de emit qu’il
y a d’auteurs dans l’article. Et pour chaque
emit on va envoyer comme valeur de la
paire intermédiaire l’ensemble de l’article, à charge
pour la fonction de reduce d’en extraire les informations
nécessaires aux documents de type B. C’est un choix paresseux:
ces articles vont transiter sur le réseau pendant le
shuffle, avec un coût important.
La fonction de Reduce reçoit donc un nom d’organisme,
et la liste des articles dont l’un des auteurs
est affilié à l’organisme. Il reste à reconstituer
le document B. Le schéma est donné ci-dessous
(on n’en demande pas plus)
function fonctionReduce ($organisme, $articles){# On parcourt les articles et leurs auteurs# pour ne garder que ceux affiliésdocument={"organisme": $organismefor[$ain$articles]dofor[$cin$a.auteurs]doif$c.affiliation ==$organismethen# On a trouvé un chercheur de l'organisme
document.ajout ($c)donedonereturn$document
Maintenant on prend en compte la table décrivant la hiérarchie des organismes,
dont voici un échantillon.
id
intitulé
ville
idParent
Vertigo
Données et apprentissage
Paris
cedric
DVRC
Systèmes intelligents
Nanterre
De Vinci
ISID
Systèmes d’information
Paris
cedric
cedric
Centre informatique
Paris
Cnam
Dessinez cette hiérarchie, et proposez une modélisation JSON pour ajouter l’information
sur les organismes dans la représentation B. Illustrez cette modélisation
sur le document « Vertigo » de la seconde question.
Correction
La modélisation JSON se prête bien aux structures
hiérarchiques. Ici, on obtiendrait des documents de la
forme suivante:
Les références bibliographiques sont gérées depuis des dizaines d’années dans
un format texte dit Bibtex. Voici par exemple
un document Bibtex représentant un article.
@article{frt-02435620,
TITLE = {{Modeling Music as Synchronized Time Series,
AUTHOR = {Fournier-S'niehotta, Raphael and Rigaux, Philippe and Travers, Nicolas,
URL = {https://hal-cnam.archives-ouvertes.fr/hal-02435620,
JOURNAL = {{Information Systems,
PUBLISHER = {{Elsevier,
VOLUME = {73,
PAGES = {35-49,
YEAR = {2018,
Comment qualifieriez-vous ce format par rapport à JSON ? Voyez-vous
des inconvénients, des avantages, à cette représentation ?
Correction
On voit que Bibtex est un version un peu primitive de JSON
ou XML, avec notamment une gestion peu robuste
des structures imbriquées. Les auteurs par exemple
seraient modélisés comme un tableau dans JSON,
et sont ici dans une chaîne de caractères,
les éléments étant conventionnellement séparés par des
and. Mais on retrouve quelques idées
importantes comme la flexibilité du schéma
et la sérialisation textuelle qui facilite les échanges.
Deuxième partie : recherche d’information (7 pts)¶
Les articles ont des résumés, et on va construire un index sur ces résumés à des fins
de classification et d’analyse. Voici un extrait des résumés de 5 articles
\(A_1, ..., A_5\).
\(A_1\) : Cet article compare les stratégies d’optimisation des échanges réseaux entre processeurs
\(A_2\) : Un orchestre moderne doit savoir maîtriser une harmonie atonale
\(A_3\) : Comparaison entre les propriétés des réseaux filaires et des réseaux optiques
\(A_4\) : Pourquoi un processeur quantique ne peut surmonter un processeur standard qu’en présence d’un réseau performant
\(A_5\) Mozart est-il mieux servi par un orchestre de chambre ou un orchestre philarmonique?
On va se limiter au vocabulaire (harmonie, processeur, réseau, orchestre).
(NB: on suppose
une phase préalable de normalisation qui élimine les pluriels, majuscules, etc.)
Donnez une matrice d’incidence contenant les tf,
et un tableau donnant les idf (sans le \(\log\)), pour les termes précédents. Placez
les termes en ligne, les résumés en colonne.
Correction
A1
A2
A3
A4
A5
harmonie 5/1
0
1
0
0
0
processeur 5/2
1
0
0
2
0
réseau 5/3
1
0
2
1
0
orchestre 5/2
0
1
0
0
2
Donnez les normes des vecteurs représentant ces résumés.
Correction
\(||A_1|| = \sqrt{2}\);
\(||A_2|| = \sqrt{2}\);
\(||A_3|| = \sqrt{2}\);
\(||A_4|| = \sqrt{5}\)
\(||A_5|| = \sqrt{4}\)
Dans un espace vectoriel à deux dimensions avec « processeur » en abcisse
et « réseau » en ordonnée, placez les vecteurs représentant nos documents.
Donner les résultats classés par similarité cosinus basée sur les tf
(on ignore l’idf) pour les requêtes suivantes. Detaillez les calculs.
processeur et réseau
harmonie et orchestre
Correction
Calculs cosinus standards.
Sans calcul, indiquez quel document est classé en tête pour la requête
avec le seul mot « réseau », et expliquez pourquoi.
Correction
C’est bien sûr le A3. Comme la requête, il parle de réseau
ET uniquement de réseaux. Les deux vecteurs sont
donc co linéaires.
Voici quelques aspects d’Elastic Search qui devraient vous être familiers,
et d’autres qui n’ont pas été abordés en cours
La documentation nous dit :
When you index a document, it is stored on a single
primary shard determined by a simple formula : \(shard = hash(id) \%\ \rm{number\_of\_primary\_shards}\)
Voici la configuration initiale de votre cluster
ElasticSearch pour les questions qui suivent
(rappel: réplica = \(n\) signifie \(n+1\) copies d’un document).
Nombre de fragments ({shards) : 3
Nombre de réplicas : 2
Et je crée un index. Chacune des questions ci-dessous vaut
1 point. Une brève explication sera appréciée.
Est-ce que mon cluster peut être constitué d’un seul nœud (un seul serveur) ?
Correction
Oui, mais l’index sera en situation périlleuse puisqu’il manquera deux serveurs pour
héberger les réplicas. Autre réponse : non car il faut stocker les réplicas
sur des serveurs distincts.
Est-ce que je peux augmenter le nombre de shards sans récréer l’index ?
Correction
Non, c’est du hachage statique, toute affectation à un fragment est définitive, sauf à reconstituer l’index.
Est-ce que je peux augmenter le nombre de réplicas ?
Correction
Oui, aucun problème, à condition d’avoir assez de serveurs sinon ça n’a pas vraiment de sens.
Est-ce que je peux ajouter des nœuds à mon cluster ?
Correction
Oui, ça peut améliorer la distribution des fragments.
Si oui, à partir de quand est-ce que ça ne sert plus à rien d’ajouter des
nœuds, en prenant en compte la configuration initiale ?
Correction
Quand on a un fragment par serveur, ça ne sert à rien d’en ajouter.
Donc \(3*(2+1)=9\) serveurs.
Un dernier point à gagner. Un de vos collègues vous affirme qu’il vaut mieux
créer un index avec beaucoup de shards, pour anticiper la croissance future. Voici
un argument contre ce choix, issu de la documentation.
Term statistics, used to calculate relevance, are per shard. Having a small amount of
data in many shards leads to poor relevance.
Nous avons vu que dans un système comme cassandra, on pouvait régler des paramètres
\(W \) (acquittements en lecture).
Ce réglage correspond à la recherche d’un compromis, mais entre quelles propriétés ?
Reprenez le théorème CAP et donnez des réponses argumentées aux questions suivantes :
Si \(W \), quelle(s) propriété(s) est/sont sacrifiée(s) avec une faible valeur de \(R\) ?
Et avec la valeur de \(R\) maximale ?
Correction
Si \(R\) est faible, on sacrifie la cohérence car on augmente la probabilité de lire une valeur obsolète.
En augmentant \(R\) on améliore la cohérence, mais on diminue la disponibilité et la tolérance.
Si \(W\) est fixé à la valeur maximale, le choix de \(R\)
influe-t-il sur les propriétés CAP ?
Correction
Non, si on a réussi à faire l’écriture aevc tous les acquittements, toute lecture ramène une valeur cohérente,
la disponibilité et la tolérance sont aussi maximales.
Nous approchons des jeux olympiques de Paris 2024, événement majeur,
mais source probable de désordres importants. Les organisateurs
décident de mettre en place un système de co-voiturage à destination
des sites, afin d’éviter les encombrements.
On pense au départ qu’une base relationnelle sera suffisante, et on
adopte le modèle suivant (très simplifié bien sûr). Les clés
primaires sont en gras, les clés étrangères en
italiques.
Personne (id, nom, domicile)
Site (id, nom)
Trajet (id, idConducteur, *idSite, date)
Passager (idTrajet, idPassager)
Voici également un tout petit échantillon de la base.
On s’aperçoit rapidement que cette représentation impose
beaucoup de jointures et ne passe pas à l’échelle.
On décide de remplacer la base relationnelle par une base Cassandra.
Voici une première table Cassandra pour représenter les trajets.
Donnez l’exemple d’un document JSON correspondant à la structure,
de la table Trajet1, avec les informations du trajet A de la base relationnelle ci-dessus.
Correction
Rappelons que la modélisation structurée (ici avec sérialisation
JSON) a pour but d’éviter autant que possible des références
à d’autres documents qui entraineraient la nécessité
de faire des jointures. On inclus donc comme objets
le conducteur, le site, et comme liste d’objets les passagers.
{"id":"A","conducteur":{"nom":"Albert","ville":"Melun"},"site":{"nom":"Stade de France"},"date":"30/07","passagers":[{"nom":"Aline","ville":"Versailles"},{"nom":"Ktie","ville":"Créteil"}]}
On a bien sûr une représentation redondante puisqu’il faudra (entre
autres) reproduire la représentation des passagers pour chacun de leurs trajets.
Voici la proposition d’une autre modélisation, avec une
table Trajet2 et une table Passager dont la clé est
composite
Rappelons ce qu’est une clé composite en Cassandra, d’après la documentation:
A compound primary key consists of the partition key and the clustering key.
The partition key determines which node stores the data. Rows
for a partition key are stored in order based on the clustering key.
Quelles affirmations sont vraies?
Les lignes de Trajet2 et de Passager sont sur le même serveur
Les passagers d’un même trajet sont tous sur un seul serveur
Les passagers stockés sur un serveur sont triés sur leur identifiant
Les passagers d’un même trajet sont stockés contiguement
Correction
Le placement des documents de Trajet2 et de Passager
est déterminé par idTrajet. Les trajets
et les passagers seront donc distribués sur tous les serveurs.
Les passagers d’un même trajet partagent la même
clé de patitionnement et on les trouve donc sur le même serveur
Les passagers d’un même trajet sont stockés contiguement et
dans l’ordre de leur identifiant (question 4); mais les passagers
apparaissent autant de fois qu’ils font de trajet, et on
peut donc trouver un passager plusieurs fois sur un serveur,
à des emplacements qui dépendent de l’identifiant d’un trajet particulier (question 3).
Est-il possible de convertir la table Trajet1 vers la table Passager
avec un traitement Map Reduce? Expliquez comment, en indiquant ce que font
les fonctions de Map et de Reduce.
Correction
Oui, c’est possible, avec une fonction de Map qui émet une
paire intermédiaire par passager. La clé de cette paire est
celle de la table Passager, et sa valeur le passager.
La fonction de reduce n’a rien de spécial à faire.
Deuxième partie : recherche d’information (6 pts)¶
L’application enregistre des commentaires déposés par les clients sur les conducteurs, et réciproquement.
Voici un échantillon.
\(c_1\): Conduite dangereuse, et conducteur bavard. À éviter.
\(c_2\): Pour la conduite ça ne va pas: le conducteur (sympa par ailleurs)
réussit à être à la fois lent et dangereux
\(c_3\): Trop dangereux! Je veux bien payer pour un co-voiturage, mais
pas avec un conducteur dangereux.
\(c_4\): Sympa, mais le conducteur est très bavard et lent.
\(c_5\) : Il est vraiment bavard de chez bavard. Heureusement, sympa et rien
de dangereux dans sa conduite.
On va se limiter au vocabulaire (dangereux, bavard, lent, sympa).
(NB: on suppose une phase préalable de normalisation qui élimine les pluriels,
majuscules, trouve que « sympa » et « sympathique », « dangereux » et « dangereuse »,
sont les mêmes mots, etc.)
Donnez une matrice d’incidence contenant les tf, et un tableau donnant les idf (sans le log), pour les termes précédents. Placez
les termes en ligne, les commentaires en colonne.
Correction
\(c_1\)
\(c_2\)
\(c_3\)
\(c_4\)
\(c_5\)
dangereux 5/4
1
1
2
0
1
bavard 5/3
1
0
0
1
2
lent 5/2
0
1
0
1
0
sympa 5/3
0
1
0
1
1
Donnez les normes des vecteurs représentant ces commentaires.
Donner les résultats classés par similarité cosinus basée sur les tf
(on ignore l’idf) pour les requêtes suivantes. Expliquez brièvement la raison
du classement pour le premier document.
bavard;
lent et sympa;
dangereux et bavard.
Correction
Il n’est pas nécessaire de diviser par la norme de la requête
puisque cela ne change pas la classement. On obtient donc les calculs:
bavard: c1 : \(\frac{1}{\sqrt{2}}\); c4 : \(\frac{1}{\sqrt{3}}\); c5 : \(\frac{2}{\sqrt{6}}\); le document
c5 arrive en tête car il contient 2 fois le terme, même si d’un autre côté
il est pénalisé par le fait d’en contenir deux autres (dangereux et sympa)
lent et sympa: c2 : \(\frac{1+1}{\sqrt{3}}\); c4 : \(\frac{1+1}{\sqrt{3}}\) c5 : \(\frac{1}{\sqrt{6}}\);
c2 et C4 sont à égalité puisqu’ils contiennent chacun une occurrence de chaque terme,
et une occurrence d’un autre.
dangereux et bavard: c1 : \(\frac{1+1}{\sqrt{2}}\); c2 : \(\frac{1}{\sqrt{3}}\);
c3 : \(\frac{2}{\sqrt{4}}\), c4 : \(\frac{1}{\sqrt{3}}\), c5 : \(\frac{1+2}{\sqrt{6}}\);
C’est évidemment c1 qui l’emporte puisqu’il correspond exactement
à la requête en termes de représentation vectorielle.
Pour la dernière requête, dangereux et bavard, on constate que deux
documents sont à égalité. Est-ce que cela change
si on prend en compte l’idf, comment et pourquoi?
Correction
bavard est un peu moins présent que dangereux dans
la collection, ce qui amène à classer c4 avant c2.
Pour la requête lentetsympa, et les documents c2 et c4,
qu’est-ce qui change si on ne met pas de restriction
sur le vocabulaire (tous les mots sont indexés)?
Correction
Dans ce cas le plus petit document (c4) l’emporte car sa norme est
plus petite. Intuititvement: il parle plus spécifiquement de
lent et de sympa que c2.
Nous recevons un flux de commentaires dans
un fichier trajets.csv. Il contient l’identifiant
du conducteur, du client, et le commentaire. Voici le début.
1, 101, "Voiture bruyante"
1, 103, "Une vraie épave"
2, 101, "La voiture est propre, plus que le conducteur..."
..
Utilisant Pig latin, on charge cette collection avec la commande suivante:
trajets = LOAD 'trajets.csv' as (idConducteur, idClient, commentaire);
Et on exécute le script Pig suivant:
coll1 = filter trajets by contains(commentaire, "voiture")
coll2 = group coll1 by idConducteur;
coll3 = foreach coll2 generate group, COUNT(coll1.commentaire);
Répondez aux questions suivantes
Expliquez le résultat produit par ce script.
Comment ce script peut-il être traduit en MapReduce? Donnez la fonction
de Map et la fonction de Reduce, sous la forme de votre choix.
Quelle serait la requête SQL correspondant à ce script Pig?
Correction
On compte, par conducteur, le nombre de commentaires contenant
le mot « voiture »
Oui, bien sûr, on peut le transcrire en MapReduce. La fonction
de Map filtre les trajets sur le commentaire, et émet
une aire intermédiaire avec pour clé l’identifiant du conducteur.
La fonction de Reduce compte le nombre d’élements dans le groupe reçu.
Sachant que Cassandra organise la distribution des données
selon la technique du hachage cohérent, expliquez l’algorithme qui
place un document de la table Passager sur un serveur.
Parmi les requêtes ci-dessous, lesquelles peuvent être
routées vers un seul serveur?
Les trajets vers Versailles
Les passagers du trajet t12 (c’est son identifiant)
Les sites visités par le passager p988 (c’est son identifiant)
À l’instant \(t\), les valeurs de hachage de deux trajets
\(T_1\) et \(T_2\) sont identiques. Peuvent-ils être placés sur deux
serveurs différents à un instant \(t+\Delta\), sachant qu’entretemps
plusieurs nœuds ont été ajoutés au système Cassandra?
Correction
Le placement sur un serveur est déterminé par idTrajet. La
valeur de cet attribut est hachée, et le serveur
dont l’intervalle de responsabilité sur l’anneau
contient la valeur de hachage reçoit le trajet.
Réponses:
La recherche sur un attribut autre que l’identifiant
de placement implique un recherche sur tous les serveurs
Une recherche sur l’identifiant de trajet peut se faire sur un seul serveur
Un passager est stocké autant de fois qu’il a effectué de trajets,
et sur des serveurs différents.
La fonction de hachage est immuable. Donc deux trajets
dont les valeurs de hachage sont identiques seront toujours
sur le même serveur.