Recherche d’information - TP ElasticSearch : pertinence¶
Cette séance de travaux pratiques est à réaliser à la suite de la précédente (voir chapitre chap-ritp_tpelasticdsl). En particulier, le lancement d’ElasticSearch et le chargement des données sont identiques. On travaille sur l’index contenant les données de 5000 films (environ).
Vous devriez notamment pouvoir relancer votre instance es1 avec la commande
suivante (conservez ou enlevez le -i selon que vous souhaitez avoir votre
serveur en mode interactif ou non) :
sudo docker start -i es1
Ouvrez ensuite un nouveau terminal.
Elasticsearch et la pertinence¶
Une première notion de score¶
Nous pouvons observer avec l’API _explain d’Elasticsearch le calcul du score
pour un film donné et pour une requête donnée.
Prenons, par exemple, la requête life sur le titre, et regardons quel score
est calculé pour le film des Monty Python, « Life of Brian » (La vie de Brian, en
français).
Utilisez la requête suivante (en POST) dans l’adresse :
movies/movie/2232/_explain
Et celle-ci dans la partie « document » :
{
"query": {
"match": {
"fields.title": "life"
}
}
}
Vous devez obtenir un score de 3.077677 (quelques chiffres peuvent différer à la fin).
Avec la documentation, reconstituez les détails du calcul de ce score, avec tf, idf et fieldNorm.
Correction
Le
tfvaut 1, car il y a 1 occurrence delifedansLife of Brianet que la racine carrée de 1 vaut 1. (tf(freq=1.0), with freq of:)L”
idfvaut 6.154529 car il y a 27 documents sur 4850 contiennentlifeEt 1 + ln(4850/(27 + 1)) = 6.154529 (idf(docFreq=27, maxDocs=4850))la
fieldNormvaut 0.5. En effet, il y a 3 termes dans « Life of Brian », et cettefieldNormest l’inverse de la racine carrée de ce nombre. Or, 1/sqrt(3) = 0.577. Stocké sur un octet donc arrondi à 0.5 ({"value": 0.5, "description": "fieldNorm(doc=679)", })Si on calcule 1 * 6.154529 * 0.5, on obtient 3.077677
En réalité, reposant sur Lucene, Elasticsearch utilise généralement une fonction de score plus évoluée que celle que l’on vient de voir, qui combine seulement 3 facteurs. Cette fonction est appelée la Practical Scoring Function de Lucene.
En lisant les explications sur la Practical Scoring Function (lien dans la
phrase précédente), vous devriez
constater que le score final repose sur les notions de tf et d”idf que
vous connaissez, mais qu’il y a des modifications importantes. Notamment, de
nouveaux paramètres font leur apparition, l”idf est élevé au carré et le
tf est la racine carré du nombre d’occurrences d’un terme dans le document,
ce qui diffère sensiblement de la formule vue dans le cours. Les effets des
différents termes ou facteurs sont détaillés dans cette documentation. Nous
allons dans la suite aborder l’un d’entre eux, le boosting.
Boosting¶
Quand on effectue des recherches sur plus d’un champ, il peut rapidement devenir pertinent de donner davantage de poids à l’un ou l’autre de ces champs, de façon à améliorer les résultats de recherche. Par exemple, il peut être tentant d’indiquer qu’une correspondance (match) dans le titre d’un document vaut 2 fois plus qu’une correspondance dans n’importe quel autre champ. C’est ce que l’on appelle en anglais le boosting, cela autorise la modification du score calculé par Elasticsearch en vue de rendre les résultats plus pertinents (pour les utilisateurs d’un système donné).
Il existe de nombreuses manières d’ajuster les paramètres entrant dans le score, nous allons en aborder quelques unes.
Saisissez la commande suivante et observez la position d’American Grafiti dans le classement, avec et sans l’option « boost ». Que se passe-t-il ?
{
"_source": {
"includes": [
"*.title"
],
"excludes": [
"*.actors*",
"fields.genres",
"fields.directors"
]
},
"query": {
"bool": {
"should": [
{
"match": {
"fields.title": {
"query": "Star Wars",
"boost": 4
}
}
},
{
"match": {
"fields.directors": {
"query": "George Lucas"
}
}
}
]
}
}
}
Avec le boosting, American Grafiti est 9e, derrière Bride Wars, mieux classé car le boosting favorise la correspondance avec (au moins) un des mots du titre.
Si on peut associer du boosting positif à certaines valeurs de certains champs, on peut rejeter vers le bas du classement des documents qui contiennent certaines valeurs pour d’autres champs. On peut combiner boosting positif et boosting négatif (évidemment pour des champs différents).
Exemple : avec la requête ci-dessous, on ne récupère que les films dont le titre
contient Star Wars, mais l’on pondère négativement avec negative boost le
réalisateur JJ Abrams, dont le film doit apparaître en queue de classement :
{
"_source": {
"includes": [
"*.title"
],
"excludes": [
"*.actors*"
]
},
"query": {
"boosting": {
"positive": {
"query": {
"match_phrase": {
"fields.title": {
"query": "Star Wars",
"boost": 2
}
}
}
},
"negative": {
"match": {
"fields.directors": "Abrams"
}
},
"negative_boost": 0.5
}
}
}
Si les documents contiennent des valeurs numériques comme la popularité (les likes d’un statut de réseau social, le nombre d’achats d’un produit donné), ou une note, il est possible d’utiliser cet indicateur pour pondérer les documents.
On utilise pour cela field_value_factor. Avec nos documents, nous pouvons
proposer une pondération avec la note (ce qui revient à ordonner par rating) :
{
"_source": {
"includes": [
"*.title",
"*.rating"
],
"excludes": [
"*.actors*"
]
},
"query": {
"function_score": {
"query": {
"match_phrase": {
"fields.directors": {
"query": "Sergio Leone"
}
}
},
"functions": [
{
"field_value_factor": {
"field": "fields.rating"
}
}
]
}
}
}
Regardez notamment les scores qui sont maintenant calculés. Il est possible d’ajouter de nombreux paramètres, pour modifier la façon dont est utilisée cette valeur de note (multiplication, addition, max, min, etc.).
Il est même possible, avec script_score de calculer vos propres valeurs et
d’en tenir ensuite compte dans le calcul du score (voir
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-function-score-query.html#function-script-score
pour les détails).
Regardons pour finir des fonctions assez utiles, les fonctions de décroissance. Celles-ci s’appliquent à une valeur d’un document selon une échelle « glissante ».
L’idée est d’ajuster la pertinence des documents en fonction, par exemple :
de leur ancienneté
de leur distance (géographique)
de leur écart de prix
Cette pondération peut être linéaire, exponentielle, ou gaussienne. Voir ces
courbes
pour une illustration du fonctionnement de cette pondération, et la page
Function Decay
pour les détails mathématiques précis. La courbe présente une valeur d’âge
(age), dont la référence est fixée à 40. En fonction de la fonction de
décroissance choisie et de la valeur d’un document, son score global sera
affecté d’un facteur supplémentaire (entre 0 et 1) minorant son importance. Par
exemple, un document pour lequel l’âge vaudrait 30 aurait, pour les 3 fonctions
choisies, un score multiplié par 0.5.
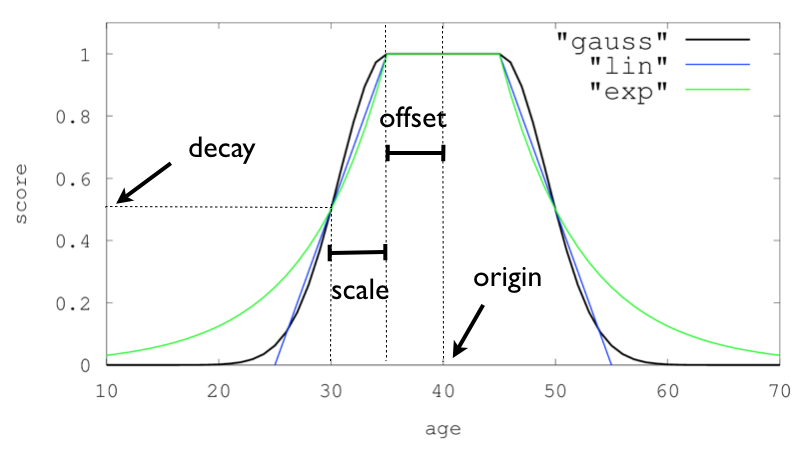{kind=link}
Dans nos documents, on dispose d’un champ date précis, donnant le jour de sortie
des films. On peut donc, avec la requête suivante, trouver les films qui sont
sortis un peu avant ou après le film « Grand prix » de Frankenheimer, sorti le 21
décembre 1966. Les paramètres decay, scale, offset sont visuellement
expliqués sur ces courbes
, ils permettent d’ajuster la forme de la courbe de la fonction de décroissance
(et donc les minorations en fonction de la distance à la valeur de référence).
{
"_source": {
"includes": [
"*.title",
"*.release_date",
"*.year"
],
"excludes": [
"*.actors*",
"*.genres"
]
},
"query": {
"function_score": {
"query": {
"exists": {
"field": "fields.release_date"
}
},
"functions": [
{
"gauss": {
"fields.release_date": {
"origin": "1966-12-21T00:00:00Z",
"scale": "30d",
"offset": "1d",
"decay": 0.5
}
}
}
]
}
}
}
À vous de jouer¶
Proposer les requêtes DSL pour organiser les résultats de la façon souhaitée :
- les films de James Cameron en pondérant négativement ceux qui durent plus de deux heures (choisissez par exemple la fonction exponentielle)
Correction
{ "_source": { "includes": [ "fields.title", "fields*.rating", "fields.running_time_secs" ], "excludes": [ "fields*.actors*", "fields*.genres" ] }, "query": { "function_score": { "query": { "match_phrase": { "fields.directors": { "query": "James Cameron" } } }, "functions": [ { "exp": { "fields.running_time_secs": { "origin": "7200", "scale": "200", "decay": 0.5 } } } ] } } }
les meilleures comédies romantiques (il s’agit d’effectuer un simple tri par
rating)Correction
{ "size": 25, "_source": { "includes": [ "fields.title", "fields*.genres" ], "excludes": [ "fields*.actors*", "fields*.rating", "fields.running_time_secs" ] }, "query": { "bool": { "must": [ { "match": { "fields.genres": "Romance" } } ] } }, "sort": [ { "fields.rating": { "order": "desc" } } ] }
- les films réalisés par Clint Eastwood, en affichant d’abord ceux dans lesquels il joue
Correction
{ "size": 21, "_source": { "includes": [ "*.title", "*.actors", "*.directors" ], "excludes": [ "*.genres" ] }, "query": { "bool": { "must": { "match_phrase": { "fields.directors": { "query": "Clint Eastwood" } } }, "should": { "match_phrase": { "fields.actors": { "query": "Clint Eastwood", "boost": 4 } } } } } }
- les films de Sergio Leone, en les ordonnant du plus récent au plus ancien (deux requêtes possibles, avec boosting ou sans boosting mais avec un tri)
Correction
Sans boosting
{ "size": 25, "_source": { "includes": [ "fields.title", "fields*.directors", "fields*.release_date" ], "excludes": [ "fields*.actors*", "fields*.rating", "fields*.genres", "fields.running_time_secs" ] }, "query": { "bool": { "must": [ { "match_phrase": { "fields.directors": "Sergio Leone" } } ] } }, "sort": [ { "fields.release_date": { "order": "desc" } } ] }
Avec boosting
{ "_source": { "includes": [ "*.title", "*.release_date" ], "excludes": [ "*.actors*" ] }, "query": { "function_score": { "query": { "match_phrase": { "fields.directors": { "query": "Sergio Leone" } } }, "functions": [ { "field_value_factor": { "field": "fields.release_date" } } ] } } }
- les films du genre Western, en pondérant négativement ceux réalisés par Sergio Leone
Correction
{ "size": 75, "_source": { "includes": [ "*.title" ], "excludes": [ "*.actors*" ] }, "query": { "boosting": { "positive": { "query": { "match_phrase": { "fields.genres": { "query": "Western" } } } }, "negative": { "match_phrase": { "fields.directors": "Sergio Leone" } }, "negative_boost": 0.5 } } }
- les films qui sont sortis dans les 15 jours avant ou après Lost in Translation de Sofia Coppola
Correction
{ "size": 25, "_source": { "includes": [ "fields.title", "fields.rating", "fields.release_date" ], "excludes": [ "fields*.actors*", "fields*.genres" ] }, "query": { "function_score": { "query": { "exists": { "field": "fields.release_date" } }, "functions": [ { "gauss": { "fields.release_date": { "origin": "2003-08-29", "scale": "15d", "decay": 0.5 } } } ] } } }
les films de sport autour de la boxe, et assez courts. Indice : la durée du film se trouve dans
fields.running_time_secs.Correction
{ "_source": { "includes": [ "*.title", "fields.plot", "*.genres", "fields.running_time_secs" ], "excludes": [ "*.actors*" ] }, "query": { "function_score": { "query": { "bool": { "must": [ { "exists": { "field": "fields.running_time_secs" } }, { "exists": { "field": "fields.genres" } }, { "match": { "fields.genres": { "query": "Sport" } } }, { "exists": { "field": "fields.plot" } } ], "should": [ { "wildcard": { "fields.plot": "box*" } }, { "range": { "fields.running_time_secs": { "lte": 7200 } } } ] } } } } }

Ce cours de Philippe Rigaux est mis à disposition selon les termes de la licence Creative Commons Attribution - Pas d’Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 International.
Table Of Contents
- Introduction
- Préliminaires: Docker
- Modélisation de bases NoSQL
- Interrogation de bases NoSQL
- MapReduce, premiers pas
- Cassandra - Travaux Pratiques
- MongoDB - Travaux Pratiques
- Introduction à la recherche d’information
- Principes du classement de documents
- Opérations de recherche avec ElasticSearch
- Le cloud, une nouvelle machine de calcul
- Systèmes NoSQL: la réplication
- Systèmes NoSQL: le partitionnement
- Calcul distribué: Hadoop et MapReduce
- Traitement de données massives avec Apache Spark
- Traitement de flux massifs avec Apache Flink
- Pig : Travaux pratiques
- Projets NFE204
- Annales des examens
Recherche
Saisissez un ou plusieurs mots-clés.